受限于算力和存储,那些沉睡在数年前的点击、收藏与购买,往往被粗暴地截断或遗忘。即便被召回,它们在模型眼中也只是一串串冰冷且互不相识的 ID 代码。但事实上,真正有趣的东西也往往藏在这些被遗忘的 “长尾” 之中。如何唤醒这 10 万级 的沉睡数据,并读懂它们背后的视觉与语义关联?
阿里妈妈与武汉大学团队给出的答案是 MUSE(MUltimodal SEarch-based framework)。这不仅仅是一个新的 CTR 模型,更像是一个给推荐系统安装的 “多模态海马体”。它利用图像与文本的语义力量,重构了用户跨越时空的兴趣图谱。
甚至,他们还开源了构建这个 “数字大脑” 的基石:Taobao-MM 数据集。
对于推荐系统长久以来技术演进路线,这一突破可谓是一次深刻的反思与重构!

论文标题:MUSE: A Simple Yet Effective Multimodal Search-Based Framework for Lifelong User Interest Modeling
论文链接:https://arxiv.org/abs/2512.07216
数据集链接:https://taobao-mm.github.io/
在搜推广业务里,CTR 建模这几年大致走过了这样一条路:一方面,特征工程和 ID embedding 体系越来越完善,主流的 ID-based 建模方法基本都被尝试过;另一方面,模型从只看短期行为,逐步演进到以 SIM 为代表的 “两阶段长期行为建模” 框架,在不牺牲时延的前提下,把可用的历史行为长度扩展到了万级别。
这些演进的确带来了可观收益,但随着历史行为越来越长,单纯在 SIM 类 ID-based 结构上叠加小改动,收益的边际变得越来越难以拉高,尤其是在检索精度受限的场景下,序列从万级往上扩展,效果提升会明显趋缓。
与此同时,一个趋势越来越明显:用户在平台上的行为序列变得极长,但绝大部分没有被真正 “用起来”。在淘宝中,用户多年积累下来的浏览、点击、加购、购买,加起来轻松就是、百万级行为序列。但受限于在线延迟、存储和算力,实际部署中的模型通常只能使用最近几千条行为,或者对整条序列做非常粗粒度的截断和过滤。再叠加一个现实约束:现有主力 CTR 模型在建模长期兴趣时,依赖的是高度稀疏的 ID 特征,长尾和过期 item 的 ID embedding 质量不佳,而它们在 “终身历史” 里占比很高;另外即便把 10 万条行为都拉了进来,模型看到的依旧主要是 “ID 共现关系”,而不是用户真实的内容兴趣。
在这样的背景下,MUSE 诞生了!
这是阿里妈妈和武汉大学团队面向搜推广业务提出的一个面向 “超长序列 + 多模态” 的终身兴趣建模新框架。
与其在现有 SIM 类 ID-based 长序列结构上继续做局部微调,MUSE 更关注的是利用多模态信息重新组织这 10 万级行为,系统性提升 “终身兴趣建模” 的质量与可用长度。它在架构上与各类 “扩展 dense 参数、提升模型表达能力” 的工作基本正交:无论当前使用的是经典 DNN 还是基于 Transformer 的推荐大模型结构,都可以把 MUSE 视为一个可插拔的 “终身兴趣建模模块”,与之叠加使用,共同放大收益。
目前,MUSE 已在阿里妈妈展示广告精排模型中全量上线,具备对 10 万长度用户原始行为序列的建模能力(并可结合聚类等方法持续向百万级扩展),基于多模态 embedding 统一表示并建模用户行为,同时通过架构与工程协同优化不增加任何延迟。在线上 A/B 实验中,MUSE 带来了稳定、显著的业务收益:CTR 提升 12.6%。同时,阿里妈妈也基于真实业务日志整理了首个 “长序列 + 多模态 embedding” 的大规模数据集 Taobao-MM,对外开放,用于支持业界和学界在「长序列 × 多模态」方向的进一步研究。
下面从 “工业落地视角” 拆解 MUSE,一步步展开。
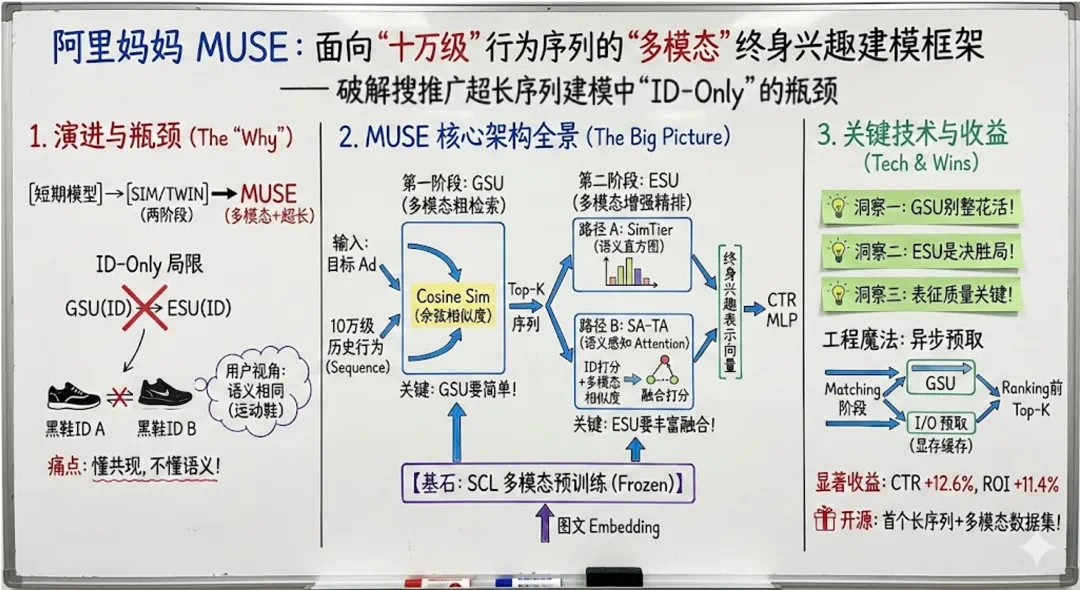
一、问题背景:终身行为建模,卡在哪?
在大规模搜推广业务中,关于终身行为建模的主流架构已经比较统一:以 SIM / TWIN 为代表的两阶段框架。
GSU(General Search Unit)在用户超长行为序列中,先做一次 “粗检索”—— 从最多 10⁵ 级行为中挑出与当前目标 item 相关的 Top-K(例如 50 条);
ESU(Exact Search Unit)再在这 K 条行为上做精细建模(DIN / Transformer 等各种 attention 结构),输出 “终身兴趣向量”,输入 MLP 结构。
这样的设计让我们一方面可以利用超长行为,另一方面又不至于把在线模型的延迟与成本拉爆。
然而,业界两阶段模型(SIM、TWIN、UBR4CTR 等)的共性是:从头到尾都围绕 ID 展开。GSU 使用 ID embedding 做相似度检索(比如基于类目、基于 ID embedding 近邻、基于 attention score 等);ESU 中仍然只使用 ID embedding 做行为聚合(target attention /self-attention 等)。
对应地,又会暴露出两类典型问题。
长尾 / 过期 item 泛化能力弱:这类 ID 出现次数少,embedding 学得不充分;GSU 检索质量直接受限 —— 历史中与目标 item 实际高度相关的点击行为,因为 ID embedding 不 “像”,可能被排除在 Top-K 之外。
ESU 语义表达力有限,只能依赖共现:模型更多是在学 “谁经常和谁一起被点”,对内容语义本身掌握不足;例如,用户一直在逛 “黑色运动鞋”,一个新上的视觉相似的黑色休闲鞋广告由于没有历史共现记录,在纯 ID 空间里很难被识别为 “强相关”。
为缓解上述问题,近两年开始有工作尝试把多模态信息引入终身行为建模。例如 MISS 在 GSU 阶段引入图文 embedding 用于检索,但 ESU 阶段仍然只使用 ID,不对多模态语义做融合建模。也就是说,检索阶段变 “聪明” 了一些,但建模阶段仍然在老路上。
二、核心洞察:GSU 要 “简单”,ESU 要 “丰富 + 融合”
在 MUSE 之前,阿里妈妈做了大规模系统实验,对多模态在 GSU 和 ESU 两个阶段的作用做了拆分分析,得到三个关键洞察,非常适合作为工业系统设计时的参考原则。

对 GSU:简单的多模态 cosine 就够了。在 GSU 中,他们系统对比了几种检索方式:只用 ID embedding 做检索;用多模态 embedding(多种预训练方式得到的多模态 embedding,包括 OpenCLIP / I2I / SCL);在多模态 embedding 上叠加 Attention 打分;ID 与多模态的各种 “加权融合” 检索策略。结果非常直接:单纯用高质量多模态 embedding 做余弦相似度检索,就已经稳定优于 ID-only 的 GSU;再叠加复杂结构(Attention、ID-Multi 融合),要么效果提升有限甚至下降,要么算力和工程复杂度明显增加,不具备性价比。结论是:在有高质量多模态 embedding 的前提下,GSU 只需要一个轻量的余弦检索就足够好。GSU 属于在线性能最敏感的一环,在这层 “搞复杂”,往往收益极低甚至适得其反。
对 ESU:多模态序列建模 + ID 融合非常关键。在 ESU 端,重点做了两方面增强:一是显式建模多模态相似度序列,引入 SimTier,把 “目标 item 与每条历史行为的多模态相似度序列” 压缩为一个 “相似度直方图”,作为语义兴趣的一种 summary 表达;二是把多模态信号注入 ID-based attention,提出 SA-TA(Semantic-Aware Target Attention),在原有 ID-based target attention 打分的基础上,将多模态 cosine 相似度及其与 ID 打分的交互项融合进去,作为最终的 attention score。在大规模广告数据上的实验结果显示:单独使用 SimTier 的多模态 ESU,相比只用 ID 的 Target Attention,GAUC 可以提升约 +0.7%;在此基础上叠加 SA-TA,总体 GAUC 提升可达到约 +1.2%。这说明 ESU 和 GSU 的设计原则截然不同。
表征质量对 ESU 比 GSU 敏感得多。阿里妈妈对比了三类多模态预训练方式:OpenCLIP(基于 2 亿级图文数据的对比学习)、I2I(基于 item 共现关系的对比学习,引入协同信号)、SCL(基于 “搜索 - 购买” 行为构造正样本,兼具语义与行为相关性)。现象是:在 GSU 只替换 embedding 类型时,效果变化相对温和;在 ESU 替换 embedding 时,差异明显:SCL > I2I > OpenCLIP。结论是:ESU 对多模态 embedding 的质量极其敏感;GSU 更像 “粗粒度过滤器”,对表征精度的要求相对没那么苛刻。
三、MUSE 框架详解
基于上述分析,团队落地了完整可部署的 MUSE 框架。整体可以拆成三步(下图从左至右):
多模态表征如何预训练:基于语义与行为的 SCL 对比学习;
多模态 GSU 如何做:轻量余弦检索;
多模态增强 ESU 如何做:SimTier + SA-TA 双路建模。
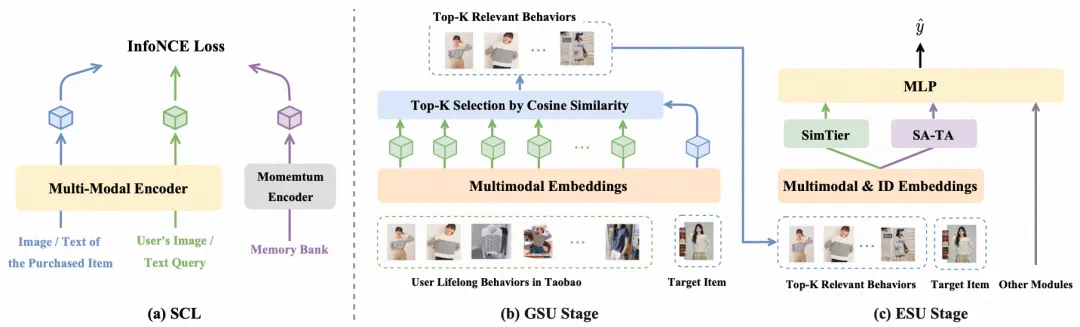
底层采用 SCL 多模态预训练。以图像模态为例,所有 item 的图像 embedding 预训练方式如下:输入包括用户搜索 query 对应的图像和该 query 下最终购买的商品图像;正样本 pair 由 query 与购买商品构成;负样本 pair 通过 MoCo memory bank 动态构造;损失函数为 InfoNCE 对比学习(形式类似 CLIP,但正负样本来自真实用户搜购行为)。得到的 embedding 具备两方面能力:内容语义(图像信息的语义对齐)和行为相关性(与真实 “搜索 - 购买” 行为对齐)。在 MUSE 中,这些多模态 embedding 在训练 CTR 模型时为冻结参数(推理阶段仅查表),便于保证线上性能的稳定性和工程可控性。
GSU 使用 SCL embedding 做简单 cosine Top-K。其目标是从用户 10⁵~10⁶ 级的历史行为中,选出最相关的几十条行为作为 ESU 的输入。具体步骤包括:通过查 embedding 表获取目标 item 的 SCL embedding(v_a)和用户所有历史行为 item 的 SCL embedding(v_i);计算每条历史行为与目标 item 的相似度 r_i = cos (v_a, v_i);按 r_i 排序,取 Top-K,形成 “输入给精排模型的行为子序列”。整个过程没有复杂 Attention,也没有 ID–MultiModal 的交织检索,本质是一个高效的内积排序。
ESU 采用 SimTier + SA-TA 双管齐下。其核心由两条并行路径构成。路径 A 是 SimTier—— 显式建模 “相似度分布”:给定 GSU 得到的相似度序列 R = [r_1, ..., r_K],
将相似度区间 [-1, 1] 等分为 N 个 bin(tier);
统计每个 bin 内落入的行为个数,得到一个 N 维 histogram:h_MM;
h_MM 可以理解为:用户历史行为中,与当前广告 “高相关 / 中相关 / 低相关” 的数量分布,即一个紧凑的 “语义兴趣分布向量”。
相比直接在多模态 embedding 序列上堆复杂结构,这种方式计算开销极小,并且在工业场景的实验中,效果非常可观。
路径 B 是 SA-TA—— 在 ID attention 里注入多模态语义。这条路径保留了 ID embedding 的优势(协同过滤信号),在此基础上做 “语义增强”。
标准 DIN Target Attention:用 target ID embedding 与行为 ID embedding 做打分,得到 α_ID;
同步拿到多模态相似度 R(沿用 GSU 的 r_i);
将两者融合为最终打分:α_Fusion = γ₁・α_ID + γ₂・R + γ₃・(α_ID ⊙ R),其中 γ 为可学习标量,⊙ 为逐元素乘;
用 Softmax (α_Fusion) 作为权重,对行为 ID embedding 做加权和,得到 u_l^ID。
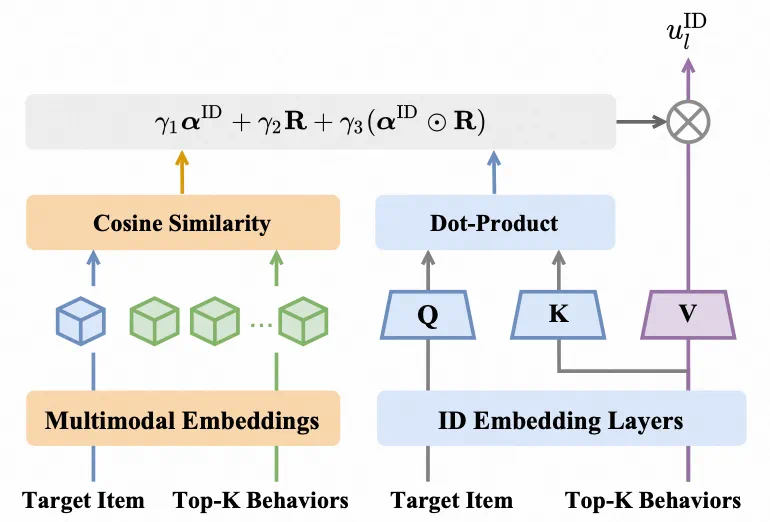
直观理解是原本 ID-based attention 对长尾 item 的打分容易失真;加上多模态相似度 R,相当于在告诉 attention: “这条行为虽然 ID 很冷,但在语义上和当前广告高度相似,可以给更高权重。”
最终用户终身兴趣表示由 SimTier 输出的 h_MM 与 SA-TA 输出的 u_l^ID 拼接而成,拼接后的向量作为 “终身兴趣表示”,输入上层 CTR MLP。至此,多模态在 ESU 中既有单独一条序列建模路径,又深入参与到 ID attention 的行为聚合过程。
四、工程落地:10 万行为 + 多模态,还能延迟可控?
超长序列 + 多模态,直觉上看 “又长又贵”。MUSE 在线上通过一个非常偏工程的拆分设计实现延迟可控。
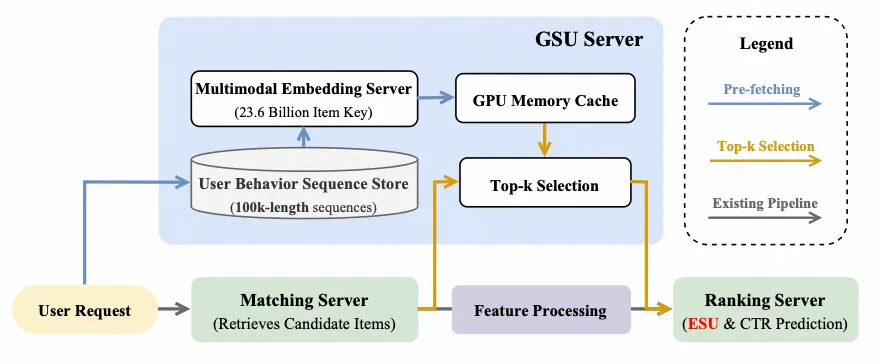
阿里妈妈展示广告线上整体 pipeline 可粗略抽象为:Matching(从全库召回约 10³ 个候选广告)和 Ranking(CTR 模型对这些候选预估打分)。MUSE 被部署在 Ranking 阶段,用于针对这些候选建模用户的终身行为。
实践发现,最大瓶颈并不在算力,而是在网络通信:需要拉取用户 100k 行为序列及其对应 embedding,网络与存储访问会引入不容忽视的时延。为此,团队的改造重点是把 GSU 从 Ranking 的关键路径中剥离出来,做异步预取。
具体分为两个阶段:
Pre-fetching 阶段(与 Matching 并行)—— 用户请求到达后,Matching 负责召回候选广告,同时 GSU 服务开始从远端存储拉取用户 100K 行为的多模态 embedding,这些 embedding 预先缓存到 GPU 显存中,该步骤的时延整体被 Matching 阶段遮蔽掉;
相似度计算 Top-K Selection 阶段(Ranking 前的小环节)—— 当 Matching 完成时,GSU 一侧的行为 embedding 已经就绪,此时只需对候选广告与缓存的行为 embedding 做一次相似度计算即可,得到 Top-K 行为 ID 和相似度序列,交由 Ranking 服务的 ESU 使用,这部分计算量很小,可以与 Ranking 的特征处理并行完成,对整体时延影响极小。
在这样的设计下,GSU 对端到端延迟几乎是 “隐身” 的。新增成本主要在于存储与网络读取负载(但被并行化掩盖)以及 ESU 端增加的 MLP /attention/ SimTier 算力开销(量级可控)。
线上对比实验设置为:Baseline 是 SIM(两阶段 ID-only 架构,行为长度 5K),MUSE 是多模态 GSU + 多模态增强 ESU,行为长度扩展至 100K。 A/B 结果显示:CTR +12.6%、RPM +5.1%、ROI +11.4%。同时,在离线实验中也对行为长度做了消融(5K / 10K / 100K),观察到:序列越长,MUSE 带来的收益越大;多模态增强 ESU 在所有长度上都显著优于 ID-only ESU,且长度越长,优势越明显。这基本佐证了一个直观判断:当你手里有几十万级别的用户历史行为日志,多模态 + 检索式建模,确实能把这些 “沉睡日志” 转化为有效的业务资产。
五、对业界的几个直接启发
如果你在做广告 / 内容推荐 / 电商推荐,MUSE 这套实践有几个非常 “可复制” 的启发点。
先别急着在 GSU 上玩花活:优先把 item 的图文 embedding 学好(无论是自建 CLIP、SCL,还是其它多模态预训练);在此基础上,用多模态 cosine 取代 GSU 的 ID-only 检索,往往是性价比最高的一步。Attention 检索、复杂多塔融合等设计,在 GSU 这个阶段不一定值得你花大量算力和工程复杂度。
把多模态引入 ESU,而不是只停留在 GSU:ESU 是真正决定 “特征如何被使用” 的地方,也是对 embedding 质量最敏感的环节;即便暂时无法重构整个 ESU,也可以分两步推进:一是引入一个轻量的 “相似度直方图” 类模块(如 SimTier)来刻画语义分布;二是在现有 DIN / TWIN 的 attention 中,引入多模态相似度作为辅助打分(类似 SA-TA)。这类改造对现有模型结构的侵入性不大,但从实验看收益往往很可观。
工程上,优先解决 “序列拉不进来” 的问题:多模态 + 超长序列的最大障碍往往不在算法,而在 I/O 和基础设施。MUSE 提供了一个可直接借鉴的模板:把 GSU 抽成独立服务,尽量与 Matching 异步并行;尽可能将 embedding 搬到就近缓存(如 GPU 显存);在 Ranking 阶段只保留轻量计算,保证路径收敛。这类设计思路,本质上是从 “只在旧框架上雕花”,转向围绕 “可扩展架构 + 高投产比” 重新规划整条推荐链路。
六、开源数据:首个 “超长行为 + 多模态 embedding” 公开数据集
这篇工作还给社区带来了一个附加价值:首个同时具备 “长行为序列+高质量多模态 embedding” 的大规模公开数据集 Taobao-MM。
其主要特点包括:
用户行为序列最长 1K(开源版本),工业内部实验支持高达 100K;
每个 item 提供 128 维 SCL 多模态 embedding(不包含原始图文,规避版权风险);
数据规模约为 1 亿样本、近 900 万用户、3,500 万级 item。
对学界研究者和工业界团队来说,这是一个可以直接验证 “多模态+长序列” 建模方案的基准数据集,有助于减少自建数据的成本。
七、小结:从 “只调 ID 模型” 到 “MUSE 多模态兴趣引擎”
从 MUSE 和近期工业界的推荐系统演进可以看到一个共同趋势:不再只在旧的 ID-only 框架上做局部微调,而是从软硬件协同、架构层面,重新组织 “算力×特征×模型”。具体到 MUSE:
结构观上,接受 “用户行为本质上是一个超大规模序列数据库”,先检索再建模;
信号观上,摆脱 ID-only 的限制,让图文 embedding 真正参与终身兴趣建模;
工程观上,把最重的 I/O 和计算挪到异步与缓存,把在线关键路径做得足够轻量。
如果你的业务场景具备以下特征:用户累积了较长行为日志(>> 万条)、每个 item 具备图文等丰富内容特征、纯 ID-only 模型的收益已经越来越难挖掘,那么可以考虑按这样一个路线落地 “轻量版 MUSE”:先提高表征质量,评估现有图文预训练 embedding,或尝试类似 SCL 的行为增强式预训练;用多模态支撑 GSU,在现有两阶段结构中,优先用多模态 cosine 替代 GSU 的 ID 检索;在 ESU 中融合多模态,在 DIN / TWIN 的 target attention 中,引入一条 “多模态相似度支路”,观察 offline 指标变化。这基本就是一个 “轻量版 MUSE” 的起点,后续可以逐步演进到完整的双路 ESU 与异步 GSU 架构,在控制延迟的前提下,打开新的效果增量空间。
阿里妈妈技术团队已在多模态智能领域取得多项突破,此次发布的 MUSE,不仅仅是算法的进步,更是工程与算法深度协同的典范。它告诉我们,在追求模型 “大” 的同时,也要注重 “巧” 和 “效率”,才能真正让技术在工业界发挥最大能量。
One More Thing ICLR 2026 Workshop 等你来稿
还有个好消息!阿里妈妈联合北京大学等组织和个人,将在 ICLR 2026 举办 Workshop on AIMS(AI for Mechanism Design & Strategic Decision Making) ,目前征稿已开启!
如果你正在探索人工智能与机制设计、决策智能的交叉前沿 ——
无论是自动机制发现、多智能体博弈均衡、高维/自然语言场景下的机制建模,
还是 AI 系统的公平性、鲁棒性,亦或是广告、云市场等真实场景的落地应用 ——
那么,这场 ICLR 2026 Workshop 正是为你而设!
截稿日期:2026 年 1 月 30 日;
接受 Long Paper(≤9 页)与 Short Paper(≤4 页),支持双重投稿(可与 ICML/KDD 等会议多投),录用不存档;
由 Tuomas Sandholm(CMU)、Song Zuo(谷歌)、Vijay V. Vazirani (UCI)、Niklas Karlsson (亚马逊)、郑臻哲 (上海交大) 等顶尖学者组成讲者与审稿阵容;
投稿地址:https://openreview.net/group?id=ICLR.cc/2026/Workshop/AIMS
此外,我们还设有 Best Paper 奖、Best Poster 奖,优秀作者还有机会获得阿里巴巴等企业的研究实习推荐!
这不仅是一场研讨会,更是连接人工智能、经济学与运筹学的桥梁。
更多详情,可戳 Workshop 官方网站:
https://alimama-tech.github.io/aims-2026/