随着人工智能技术的不断发展,多模态模型在图像理解、自然语言处理等领域的应用越来越广泛。SAIL-VL2 是由字节跳动抖音 SAIL 团队和新加坡国立大学 LV-NUS 实验室联合推出的一款开源多模态视觉语言模型,旨在实现全面的多模态理解和推理。
一、项目概述
SAIL-VL2 是由字节跳动抖音 SAIL 团队和新加坡国立大学 LV-NUS 实验室联合开发的开源视觉语言基础模型。作为 SAIL-VL 的继任者,SAIL-VL2 在 2B 和 8B 参数规模下,于多样化的图像与视频基准测试中均达到当前最优性能,展现出从细粒度感知到复杂推理的强劲能力。其核心创新包括大规模数据筛选与优化、渐进式训练框架以及混合专家(MoE)架构,使得模型在效率和性能上均实现了显著提升。
 图片
图片
二、核心功能
(一)多模态理解与交互
SAIL-VL2 能够同时处理图像和文本信息,准确完成多种任务,如图像描述生成、视觉问答等。它能够理解视觉内容并生成相应的语言描述,为多模态交互提供了强大的基础。这种能力使其在内容创作、智能客服等领域具有广泛的应用前景。
(二)高效的模型架构
SAIL-VL2 采用创新的混合专家(MoE)架构,在仅激活部分参数的情况下实现高性能,显著提升了计算效率。这种架构突破了传统密集型模型的限制,使得模型在大规模数据处理和复杂任务中表现出色,同时降低了训练和部署成本。
(三)精准的理解与推理
通过先进的多模态融合技术,SAIL-VL2 能够更准确地理解复杂的视觉信息,并结合上下文进行深度推理。它在多种基准测试中表现出色,尤其是在复杂推理任务中,展现了强大的逻辑推理能力,为多模态应用提供了可靠的解决方案。
(四)大规模数据处理
SAIL-VL2 通过优化的数据处理管道,能够高效处理海量的多模态数据。其数据处理策略包括评分与筛选,确保数据质量和分布的多样性,从而提升训练效率和模型性能。这种能力使其在处理大规模多模态数据时具有显著优势。
(五)多任务学习
SAIL-VL2 支持多种多模态任务,如字幕生成、OCR 识别、视频理解等,具有广泛的适用性。通过多任务学习,模型能够同时处理多种任务,展现出强大的通用性和适应性,为多模态应用提供了灵活的解决方案。
三、技术揭秘
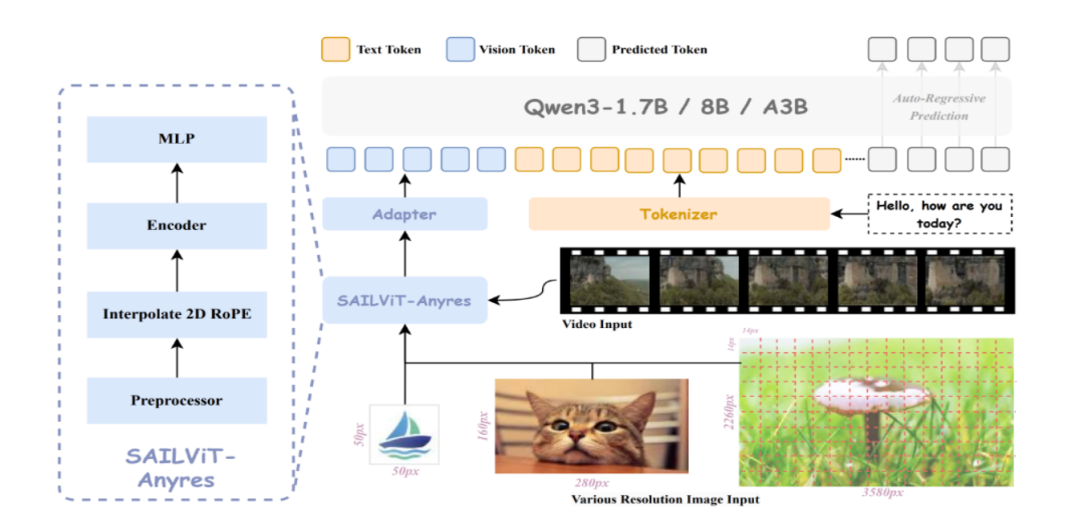
(一)视觉编码器SAIL-ViT
SAIL-VL2 的视觉编码器 SAIL-ViT 基于 Vision Transformer 架构,能够高效地将图像和视频编码为视觉标记序列。通过渐进式训练,SAIL-ViT 逐步提升视觉特征与语言模型的对齐能力,最终实现全面的跨模态融合。这种设计不仅提高了视觉理解的准确性,还增强了模型在多模态任务中的表现。
(二)渐进式训练框架
SAIL-VL2 采用渐进式训练框架,从视觉编码器的预训练开始,逐步过渡到多模态预训练,最后通过监督微调(SFT)和强化学习(RL)混合范式进行优化。这种分阶段的训练方法系统性地提升了模型的多模态理解和推理能力,确保模型在不同任务中都能表现出色。
(三)混合专家(MoE)架构
SAIL-VL2 引入了高效的混合专家(MoE)架构,突破了传统密集型大语言模型的限制。通过仅激活部分参数,MoE 架构在保持高性能的同时显著提升了计算效率和模型规模的可扩展性。这种架构设计使得 SAIL-VL2 在处理大规模多模态数据时更加高效。
(四)数据处理与优化
SAIL-VL2 通过优化的数据处理管道,能够高效处理海量的多模态数据。其数据处理策略包括评分与筛选,确保数据质量和分布的多样性,从而提升训练效率和模型性能。此外,SAIL-VL2 还采用了动态学习率搜索(AdaLRS)等技术,进一步优化训练过程。
(五)多模态任务适配
SAIL-VL2 通过设计灵活的适配器和训练策略,能够适应多种多模态任务,如图像描述生成、视觉问答、视频理解等。这种多任务适配能力使得 SAIL-VL2 在不同应用场景中都能展现出强大的通用性和适应性,为多模态应用提供了灵活的解决方案。
四、基准评测
(一)多模态理解任务
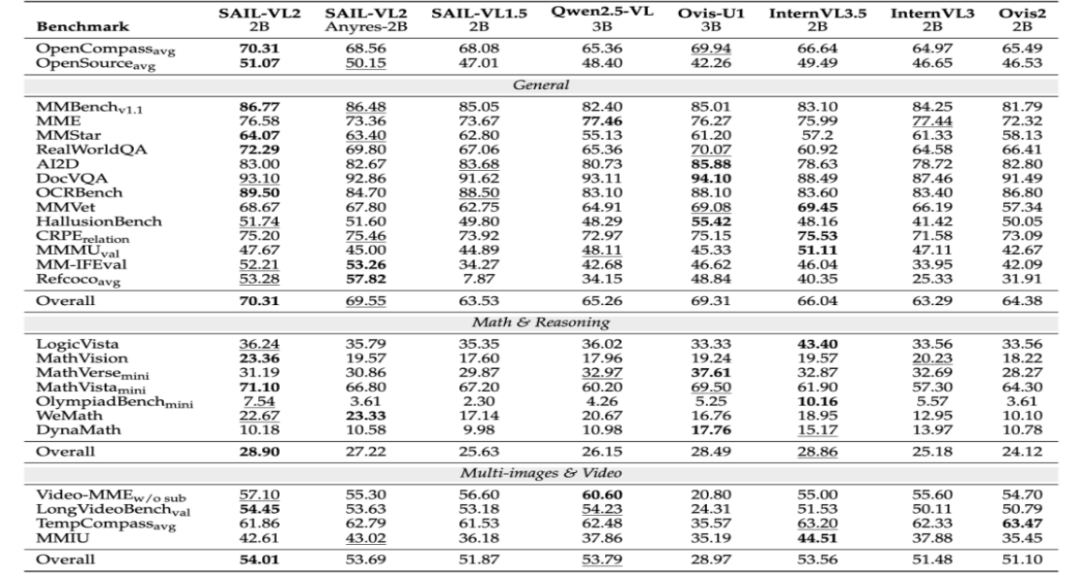
在MMBench-v1.1、MMStar、RealWorldQA 等基准测试中,SAIL-VL2-2B 和 SAIL-VL2-8B 均取得了领先的成绩。
(二)复杂推理任务
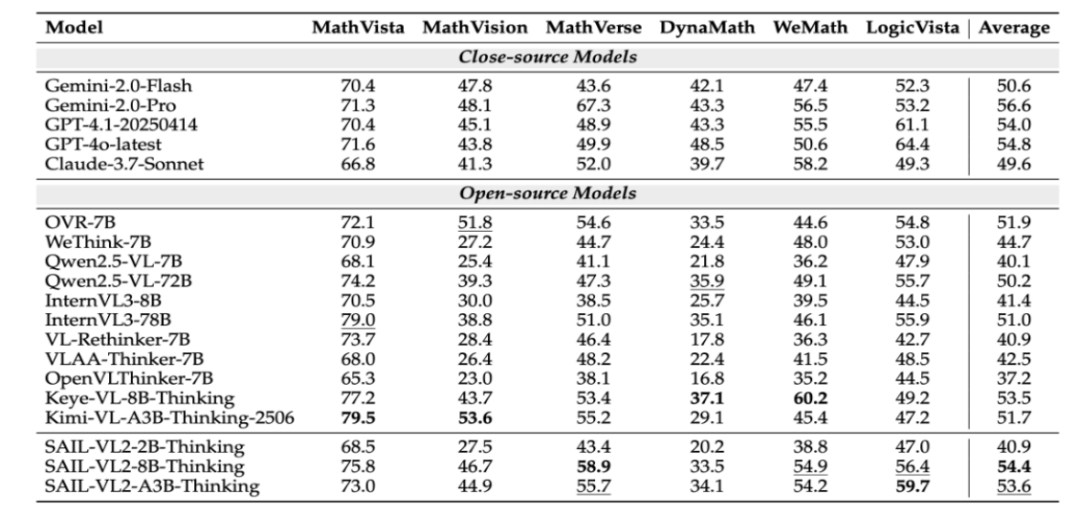
SAIL-VL2-Thinking 在 MathVista、LogicVista 等复杂推理基准测试中表现出色,8B 版本的零样本分数达到 75.8。
五、应用场景
(一)图像描述生成
SAIL-VL2 能够根据输入的图像自动生成准确且自然的描述文本。这一功能在内容创作、智能标注等领域具有重要应用价值。例如,它可以为社交媒体平台自动生成图像描述,帮助用户更快地发布内容,提升用户体验。此外,它还可以用于辅助视障人士理解图像内容,提供更加友好的信息访问方式。
(二)视觉问答(VQA)
SAIL-VL2 可以理解图像内容并回答与图像相关的问题。这一功能在智能客服、教育辅助等领域具有广泛应用。例如,在智能客服中,SAIL-VL2 可以通过图像问答帮助用户解决产品相关问题;在教育领域,它可以辅助学生理解复杂的图像内容,提高学习效果。
(三)多模态内容创作
SAIL-VL2 支持从文本生成图像或从图像生成文本,实现视觉与语言之间的有效转换。这一功能在广告设计、故事创作等领域具有重要应用。例如,广告设计师可以利用 SAIL-VL2 根据创意文本快速生成图像,提高创作效率;创作者也可以通过图像生成文本,丰富内容形式。
(四)视频理解与分析
SAIL-VL2 能够处理视频数据,提取关键帧信息并生成视频摘要或描述。这一功能在视频推荐、监控分析等领域具有重要应用。例如,在视频推荐系统中,SAIL-VL2 可以通过视频理解生成更准确的视频标签,提升推荐效果;在监控分析中,它可以实时分析视频内容,及时发现异常情况。
(五)智能搜索
SAIL-VL2 结合图像和文本信息,提供更精准的搜索结果。这一功能在电商平台、内容检索等领域具有重要应用。例如,在电商平台上,用户可以通过上传图像或输入文本,快速找到相关商品;在内容检索中,SAIL-VL2 可以通过多模态理解,提供更准确的搜索结果,提升用户体验。
六、快速使用
以SAIL-VL2-2B 模型为例,以下是使用 Python 进行推理的代码示例:
复制结语
SAIL-VL2 作为一款开源的多模态视觉语言模型,凭借其高效的架构设计、强大的多模态能力和卓越的推理性能,在多个领域展现出了巨大的应用潜力。其开源特性为研究人员和开发者提供了丰富的资源,有助于推动多模态人工智能技术的发展与创新。
项目地址如下:
Github仓库:https://github.com/BytedanceDouyinContent/SAIL-VL2
Hugging Face 模型库:(https://huggingface.co/BytedanceDouyinContent
arXiv 技术论文:https://arxiv.org/pdf/2509.14033


