
当前,驱动科学研究的人工智能(AI for Science,AI4S)在单点取得了可观的进展,实现了工具层面的革新,然而要成为「革命的工具」,需要采用「通专融合 AGI」方式。大模型的突破性能力逐步改变科学研究的模式,而大模型在科学领域的深度应用亟需科学的评测支撑。
现有科学评测面临着两大痛点:现有测试多聚焦知识记忆,而真实科研需要从原始科学数据感知到复杂推理的全链条能力;天文、地球、生命和材料等领域存在大量未开发的多模态数据分析需求。
为此,上海人工智能实验室 AI4S 团队推出了 Scientists’ First Exam(以下简称 SFE)—— 系统评估多模态大模型(MLLMs)多学科、高难度的科学专业领域认知能力的评测基准。
SFE 技术报告链接: https://arxiv.org/abs/2506.10521
SFE 数据集链接:https://huggingface.co/datasets/PrismaX/SFE
SFE 评测基准已上架到司南评测集社区,欢迎访问:https://hub.opencompass.org.cn/dataset-detail/SFE
SFE 首创「信号感知 - 属性理解 - 对比推理」三级评估体系,涵盖五大科学领域的 66 项高价值任务,采用原始科学数据和中英双语问答形式。测试表明,尽管主流模型在传统基准表现优异,但在 SFE 高阶科学任务上仍面临显著挑战(SOTA 大模型综合得分仅为 30 左右)。SFE 通过系统全面地评测大模型在科学任务上的能力短板,为科学 AI 发展指明了突破方向。
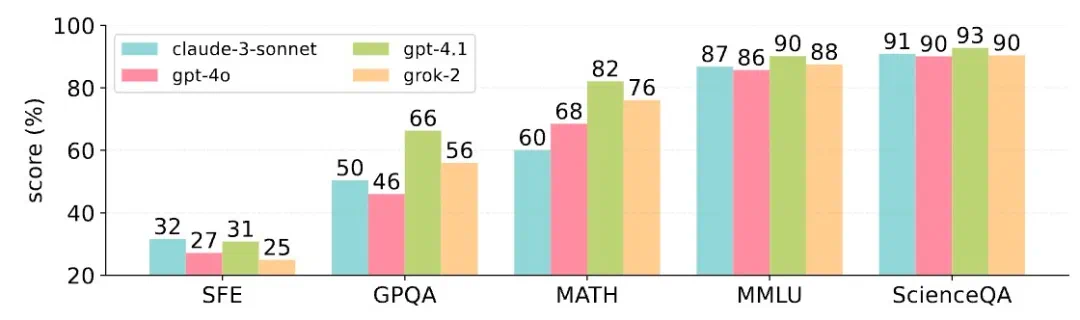
主流 MLLM 在各种 Benchmark 上的性能
三层认知框架评估科学能力的深度和广度
SFE 构建了三层认知框架,包括:
科学信号感知(L1)
科学属性理解(L2)
科学比较推理(L3)
通过这三个认知层级,SFE 考察模型从数据感知到高阶推理的综合能力。SFE 涵盖了天文学、化学、地球科学、生命科学和材料科学五大领域,共包含 66 个由专家精心设计的高价值多模态任务。所有任务基于科学原始数据构建,以视觉问答(VQA)形式呈现,并支持中英文双语。SFE 不仅考查深层次的领域知识和数据分析能力,也旨在提升科学研究效率,促进科学进步。
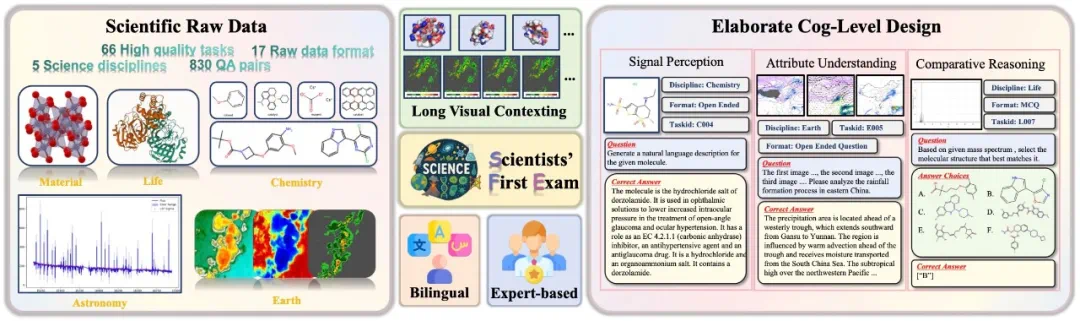
SFE 旨在全面评估 MLLMs 的科学能力的深度和广度
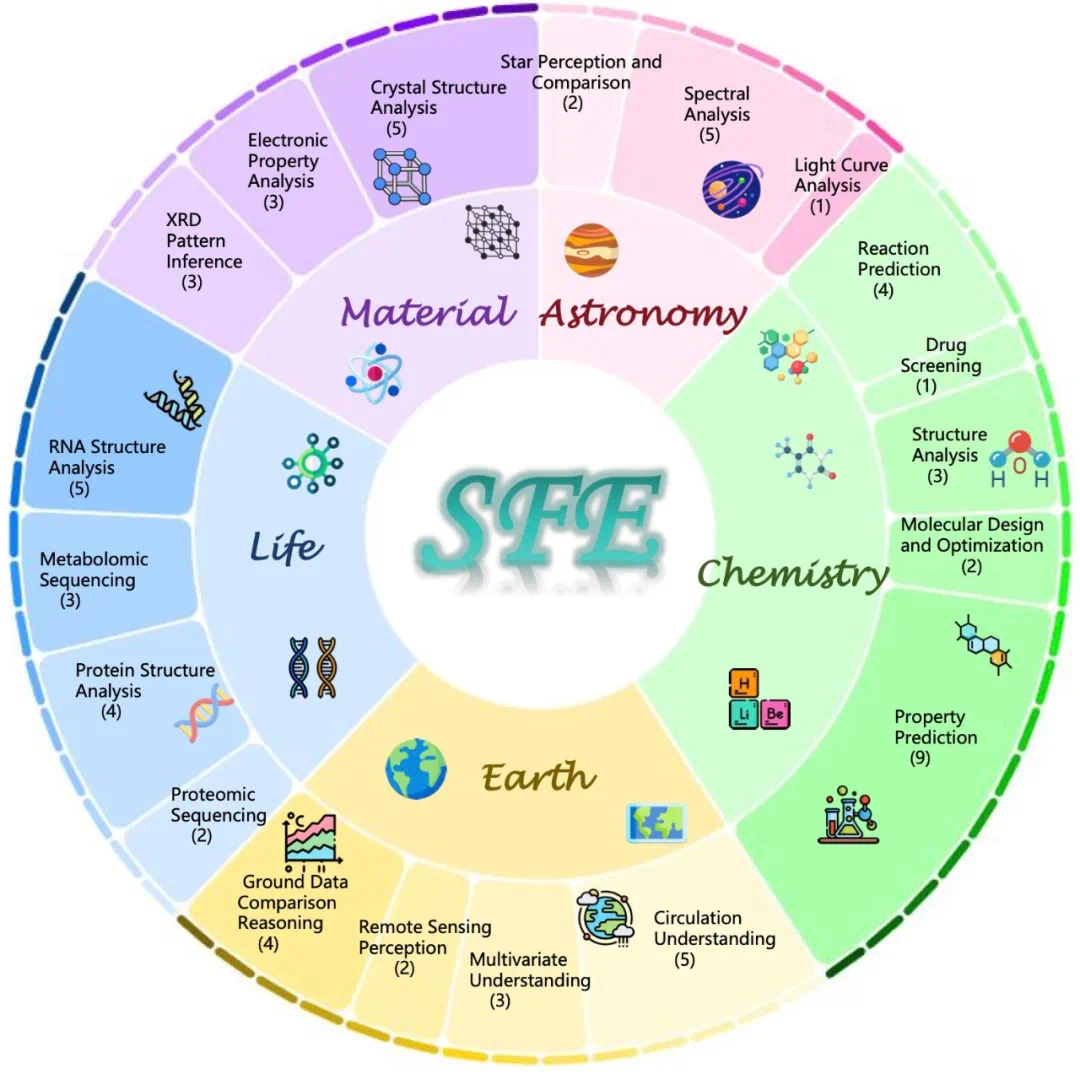
SFE 任务分布
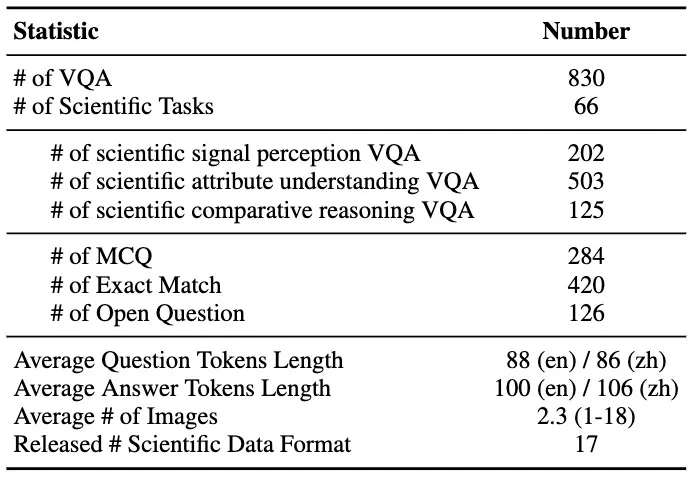
SFE 数据分布
多学科领域专家共建数据集
SFE 的数据集构建与多学科领域专家进行了广泛合作,包含三个关键阶段:
结构设计,与专家共同确定高价值科学挑战和方向;
任务设计,将科学方向细化为具体任务,通过专家设计和评审明确问题类型与认知层级;
基准搭建,精选科学原始数据,进行渲染和可视化,由专家撰写高质量的 VQA 样本。
SFE 数据收集框架图。1. 根据科学前沿进展和领域专家建议,确定了 18 个科学方向。2. 邀请专家提出领域任务并提供基于三个认知水平的原始任务数据。3. 将任务数据可视化并进一步请领域专家对结果基准进行注释。
评测揭示主流 MLLMs 在高阶科学任务上面临挑战
基于 SFE,对 16 个主流的开源与闭源 MLLMs 进行了评测。为了降低评测过程中的随机性,所有模型的 Temperature 参数都被统一设置为 0。同时,为了保证评测的公平性,所有模型的最大生成 Token 数也被统一限定为 1024。在此实验设置下,SFE 观察到以下关键现象:
闭源 MLLMs 的科学能力显著优于开源 MLLMs
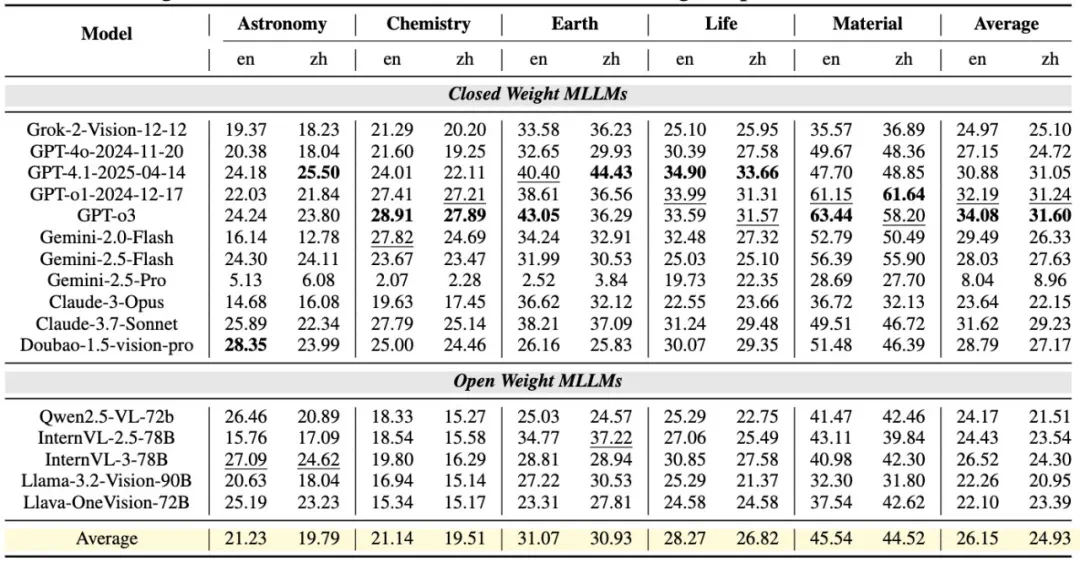
SFE 评测结果显示,闭源大模型(如 GPT-o3、Claude-3.7-Sonnet)在科学认知能力上整体优于开源模型,平均领先 6-8%。
其中,GPT-03 与 Gemini-2.5-Pro 的表现差异超过 26%。造成这一显著差距的主要原因在于,Gemini-2.5-Pro 在推理过程中进行了过多冗余的思考,导致 Token 消耗过快,最终未能完整输出结论。而 GPT-o3 虽同为具备推理能力的模型,但能够更有效地控制思考过程的冗余度,提高推理效率,因此获得了更高的分数。这一结果进一步证明了 SFE 能有效区分不同模型的科学能力。
此外,同一系列模型内部也表现出明显进步,例如 Claude-3.7-Sonnet 相比前代提升超过 7%。这一趋势在 InternVL 模型系列中同样存在,反映出模型架构与训练方法的持续改进带来的能力提升。
MLLMs 在 SFE 的不同学科之间表现出明显性能差距
评测结果显示,材料科学是各类模型表现最好的领域,GPT-o3 在该方向的英文任务中达到 63.44%,中文任务为 58.20%,即便是开源模型(如 Qwen2.5-VL-72b、InternVL-3-78B)也能超过 40%。这种优势主要得益于材料科学任务的输入结构化明显(如相图、X 射线衍射图),模型可依赖其较强的符号化视觉信息处理能力,输出结构化的科学答案。
相比之下,天文学任务则更具挑战性,涉及光谱分析和天体物理参数的数值估算,因原始数据噪声大、直观性弱,当前模型普遍难以胜任。该现象反映了 SFE 能有效揭示 MLLMs 在不同类型科学推理上的优势与不足。
MLLMs 的科学能力正在从知识理解到高阶推理进行转变
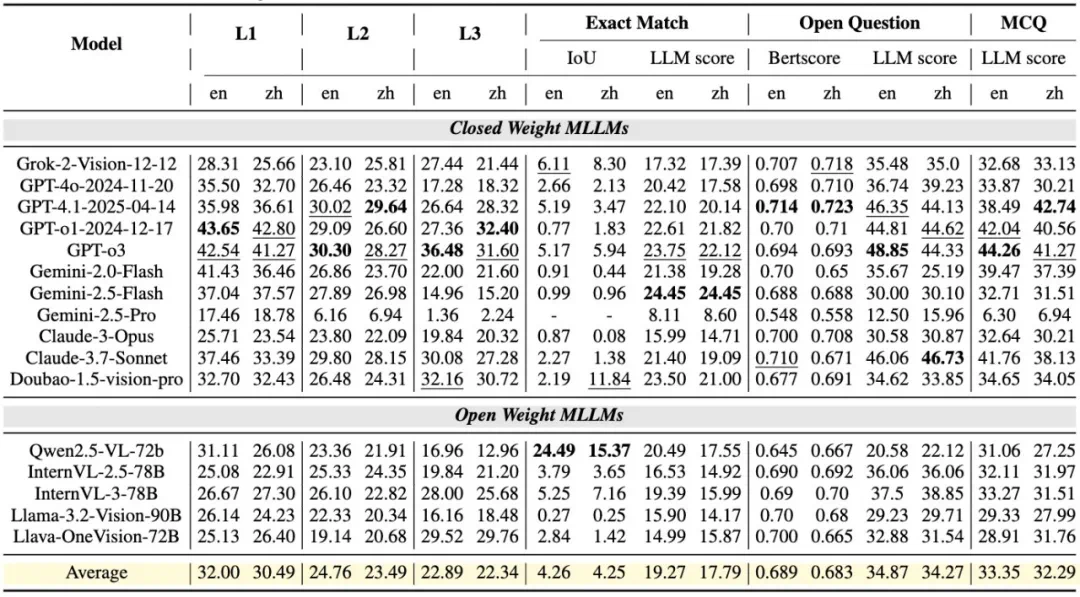
SFE 的三层认知框架显示,最新的 MLLMs 在高阶推理(L3)任务上表现提升显著,而在理解类(L2)任务上的进步有限。例如,GPT-o3 在 L3 任务上的得分从 26.64%(GPT-4.1)提升到 36.48%,但 L2 分数几乎无变化。这说明模型在推理能力、工具使用等方面进步,知识广度则变化不大。
同样,InternVL-3 英文 L3 任务也较前代提升 8%,这主要得益于其多模态预训练和链式思维等新训练策略。L2 任务进步微弱,进一步说明模型的提升主要来源于高阶推理能力的架构与训练创新。
闭源 MLLMs 在可扩展性上普遍优于开源模型
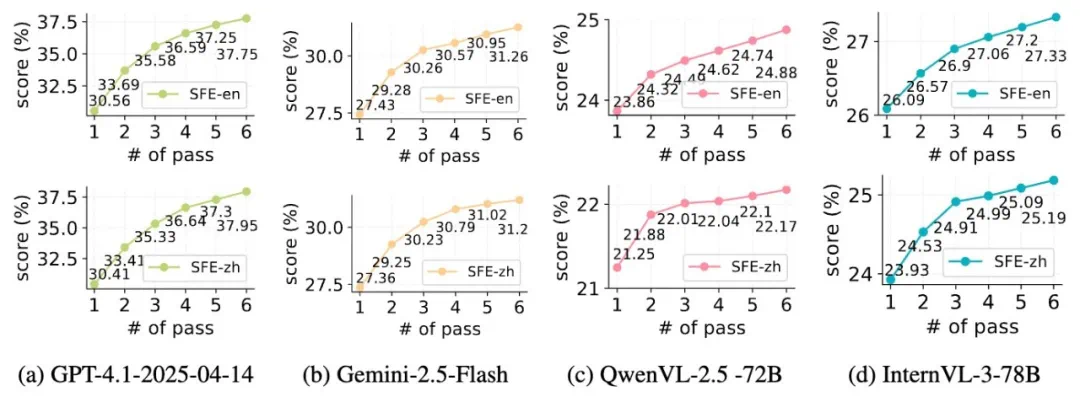
采用 Pass@k 指标评估模型生成高质量答案的能力,结果显示,闭源模型(如 GPT-4.1-2025-04-14 和 Gemini-2.5-Flash)不仅初始表现更好(30.56% vs 26.09%),而且随着 k 增加,性能提升也更明显(30.56% → 37.75% vs 26.09% → 27.33%)。
这表明闭源模型在预训练时或许使用了更丰富多样的数据集,并在后训练阶段注重了探索(Exploration)与利用(Exploitation)的平衡,优于仅注重 Exploitation 的开源模型。

科学领域模型大小的 Scaling Law
在 SFE 评测下,不同大小的 MLLMs 表现出模型规模与科学能力提升并不总是成正比。例如,Qwen2.5-VL-72B 与 InternVL-3-78B 相较于自家小模型并未显著提升,Qwen2.5-VL-72B 甚至低于 Qwen2.5-VL-7B,可能存在过拟合问题。
这表明在科学领域,模型扩大的同时需合理扩充科学数据,否则难以实现性能线性提升。
SciPrismaX科学评测平台 共建 AI4Science 生态
除发布了 SFE 评测基准之外,研究团队还构建了「棱镜」(SciPrismaX) 科学评测平台。平台包含了模型能力、学科多样性、评估策略、评估对象与评估工具五大模块,覆盖了 AI for Innovation、AI for computation 和 AI for Data 三层评估维度,致力于构建更严谨、动态且与科研实践深度契合的评估生态。

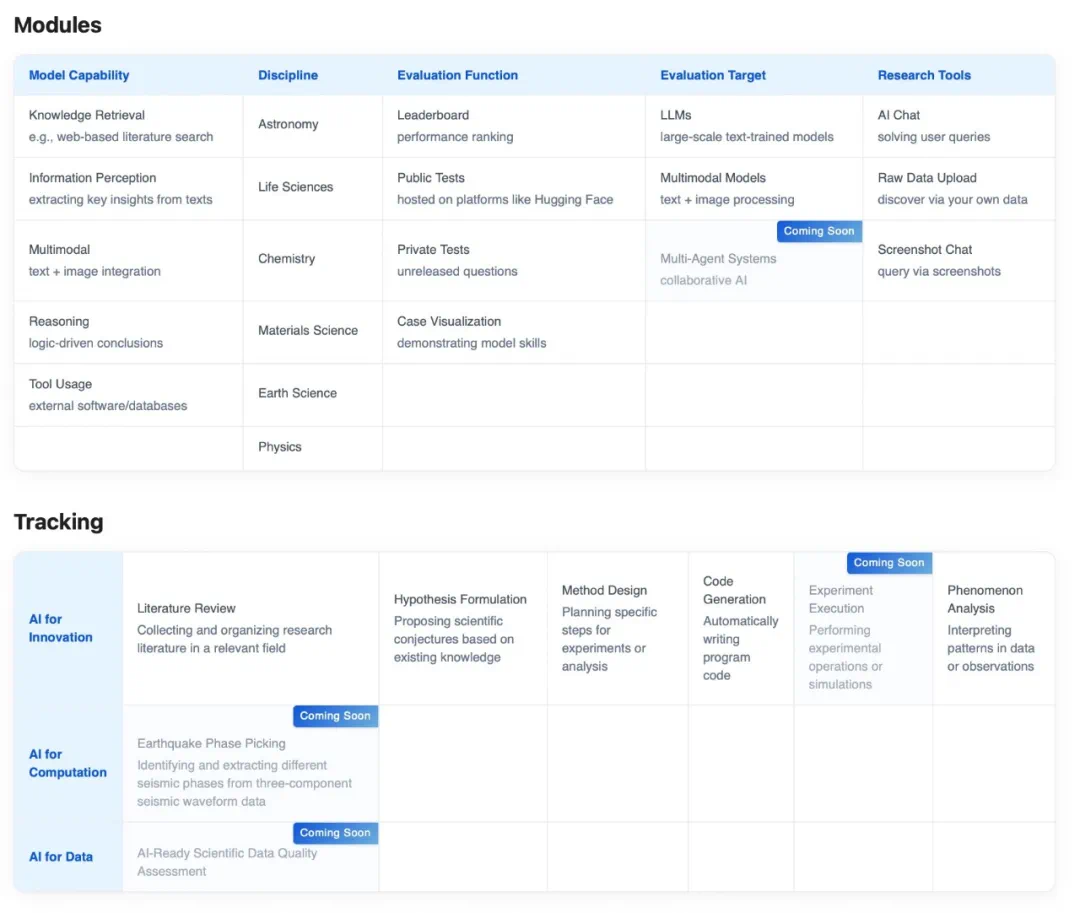
同时,平台还将通过实时追踪、自建、与社区共建等方式,维护动态更新的高质量科学评测基准数据库,以期共同推进 AI 在 Science 领域基准的进步。
「棱镜」(SciPrismaX) 科学评测平台链接:https://prismax.opencompass.org.cn/


