近期,懂车帝的《懂车智炼场》栏目对量产自动驾驶系统的NOA辅助驾驶功能进行了安全关键场景测试。
结果显示,在黑夜施工工地、高速公路前方车辆发生事故以及障碍物后突然驶出车辆等高风险场景中,目前尚无任何系统能够在测试中做到完全避免事故。
这类安全关键场景在真实道路上虽不常见,但一旦发生,可能导致人员伤亡或严重交通事故。
为了提升自动驾驶系统在此类情境下的可靠性,必须在多样化且高风险的安全关键场景中进行广泛测试。
然而,这类极端场景在现实中采集难度极高——发生频率低、风险大、难以批量获取。
在仿真环境中,类似的场景虽然可以批量制造,但现有模拟器在画面真实度上与现实仍有差距,难以直接用于真实域下端到端系统的极限测试。
为此,来自浙江大学与与哈工大(深圳)的研究团队提出了SafeMVDrive——首个面向真实域的多视角安全关键驾驶视频生成框架。
它将VLM关键车辆选择器与两阶段轨迹生成结合,驱动多视角视频生成模型,在真实域中实现批量制造高保真安全关键视频,可用于对端到端自动驾驶系统的安全性测试。
 论文地址:https://arxiv.org/abs/2505.17727
论文地址:https://arxiv.org/abs/2505.17727
项目地址:https://zhoujiawei3.github.io/SafeMVDrive/
代码地址:https://github.com/zhoujiawei3/SafeMVDrive
数据集地址:https://huggingface.co/datasets/JiaweiZhou/SafeMVDrive
为了实现高质量真实域多视角安全关键场景,研究人员首先尝试将安全轨迹模拟与多视角视频生成模型结合,用真实域视频驱动极限测试。然而在实践中,他们发现存在两大挑战:
一是安全关键车辆的选择。现有方法大多依赖简单的启发式规则(如选择最近车辆),缺乏对场景关系的视觉理解,容易选错目标车辆,导致生成场景的安全关键性不足或生成失败;
二是多视角视频生成模型的泛化性问题。由于现有模型在训练时几乎没有接触过碰撞或近距离互动等极端场景数据,在这些情况下的生成质量明显下降。
为此,研究团队提出了两项关键创新:
- VLM关键车辆选择器:引入经过GRPO微调的视觉语言模型,从多视角真实画面中推理交通互动关系,精准识别最有可能制造危险的对抗车辆;
- 双阶段轨迹生成:先生成符合物理规律的碰撞轨迹,再转化为「接近碰撞但成功规避」的轨迹,既保留紧张刺激的安全关键特征,又保持视频生成的高保真度。
SafeMVDrive能够批量生成高保真、多视角的安全关键驾驶视频,显著提高极端场景的覆盖率,并在保持画质与真实感的同时,为端到端自动驾驶系统的极限压测提供更具挑战性的测试数据。
效果展示
对于给定的多视角图像,SafeMVDrive能够在真实域生成高质量的安全关键多视角视频,其中不仅包含目标车辆的安全关键行为(如加塞、急刹、后方突然加速),还呈现出自车(当前多视角摄像机安装车辆)的相应规避动作。

侧方车辆突然加塞,自车轻微向右转向避让

后方车辆突然加速,自车向左变道以躲避

后方车辆突然加速,自车同步提速进行规避

前方车辆突然减速,自车变道并减速避让
如下图所示,相比于将开源数据集中的自然轨迹用于多视角视频生成模型(Origin),以及简单的将碰撞轨迹模拟生成的轨迹与多视角视频生成模型结合(Naive)而言,SafeMVDrive兼顾视频真实性质量以及场景危险性。

第一列自然轨迹生成的视频较常见,第二列碰撞轨迹生成的视频未段车辆变形失真,第三列本框架生成的视频兼具真实性与安全关键性
方法概述
SafeMVDrive的核心目标,是从一个给定的初始场景中批量生成真实域多视角安全关键驾驶视频。
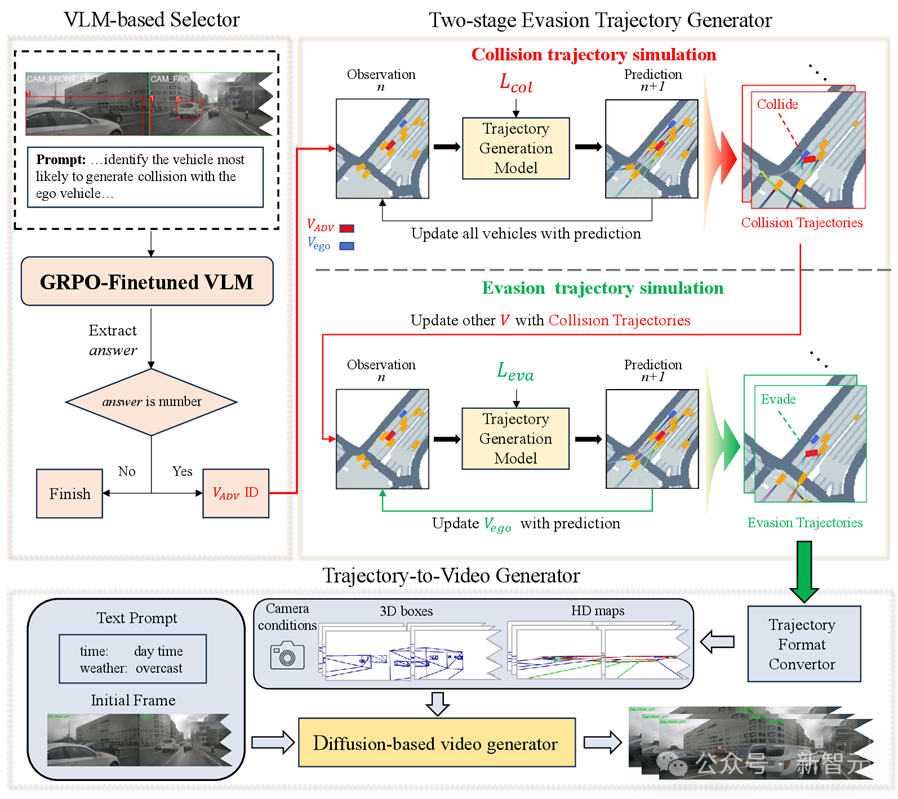
整个方法由三大模块组成:
VLM车辆选择器:多视角画面中锁定安全关键车
在极端驾驶场景的构造中,第一步是决定哪辆车会对自车构成威胁。
传统方法常依赖非视觉信息即数据集标注并结合启发式规则(如距离最近的车辆)选择。这种简单的规则往往无法覆盖复杂的交通场景,并且可能因为数据集漏标注导致选择的车辆无法以自然的轨迹与自车发生碰撞。
如下图所示,右图展示的是非视觉信息即数据集标注,失去了对于安全关键车辆信息判断至关重要的障碍物标注,导致传统的启发式规则方法错误判断认为大巴可以与自车发生自然轨迹的碰撞,实际上其并无法绕过障碍物与自车发生碰撞。

研究人员提出利用初始场景的多视角图像中的视觉信息,配合VLM的场景理解能力实现更有效的安全关键车辆选择。
首先,研究人员利用碰撞轨迹模拟自动化生成「初始场景——安全关键车辆」配对数据集,之后利用GRPO算法微调VLM,最终地得到了基于VLM的安全关键车辆选择器。
双阶段轨迹生成:从「碰撞」到「规避」
现有安全关键轨迹生成方法多以制造碰撞事件为目标,但由于当前多视角视频生成器缺乏真实多视角碰撞数据,这类碰撞控制信号往往导致生成画质下降。
为此,研究人员提出双阶段规避轨迹生成策略,在保留安全关键特征的同时生成可被现有视频生成器真实渲染的规避场景。
第一阶段为碰撞轨迹模拟:基于可控扩散轨迹生成模型,从初始单帧场景出发,通过test-time loss guidance引导对抗车辆与自车发生有效碰撞。研究人员设计了三类损失:
对抗损失:在碰撞发生前按时间衰减加权,最小化两车间距离,鼓励对抗车辆快速逼近自车,并在碰撞后将损失置零以避免不自然的「粘连」行为;
无碰损失:约束除自车与对抗车辆外的其他车辆避免碰撞;
在路损失:惩罚驶入非可行驶区域的轨迹,保持交通合理性。
第二阶段为规避轨迹转化:在保持第一阶段所有非自车轨迹不变的前提下,仅更新自车轨迹,并以无碰损失和在路损失引导自车规避对抗车辆,从而将原本的碰撞场景自然转化为安全关键的规避场景。
这种方式既保留了对抗车辆的威胁性动作,又确保了生成结果的真实感和物理合理性。
最终,经过筛选的规避轨迹被用于驱动多视角视频生成器,得到兼具安全关键性与视觉真实感的驾驶视频。
多视角视频生成:真实域合成高保真「险情」
在SafeMVDrive的最后一步,研究团队采用了多视角视频生成模块,将双阶段轨迹生成器输出的「规避型」安全关键轨迹转化为高保真真实域视频。
具体来说,他们选用UniMLVG作为骨干网络,该模型不仅支持显式控制自车与周围车辆的运动轨迹,还能在较长时间跨度内保持视频质量稳定。
转换过程中,生成的规避轨迹会被编码成逐帧控制信号(3D边界框、高清地图、相机参数),并结合多视角初始帧与时间及天气文本描述输入视频生成器。
由于安全关键场景持续时间较长,SafeMVDrive采用自回归滚动生成方式:每段视频的最后一帧作为下一段的起始帧,对应时间窗口的控制信号则用于引导后续生成。
通过这种迭代,完整的碰撞规避轨迹最终被渲染为真实域的多视角「险情」视频,兼顾安全关键性与画面真实感
实验结果
研究团队从两个方面进行了评估:生成视频的真实感与安全关键性,以及对抗车辆选择的准确度。
高保真危险场景批量生成
如下表所示,SafeMVDrive在生成真实域多视角视频的同时,显著提升了安全关键场景的覆盖率和多样性。
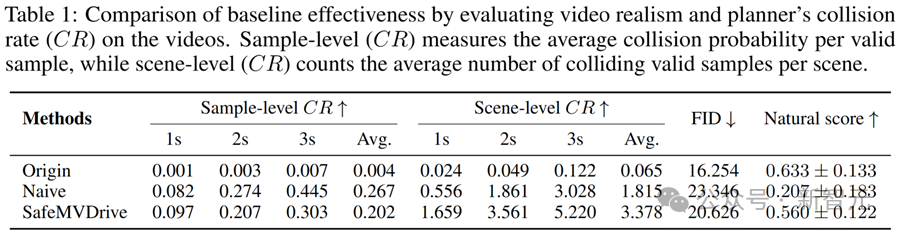
在碰撞率指标上,它生成的场景比开源数据集中自然轨迹用于多视角视频生成模型(Origin)更具挑战性,且在保持高碰撞率的同时,画质与真实感依然接近真实视频,远优于将碰撞轨迹模拟生成的轨迹直接与多视角视频生成模型结合生成的视频(Naive)。
精准锁定安全关键车辆
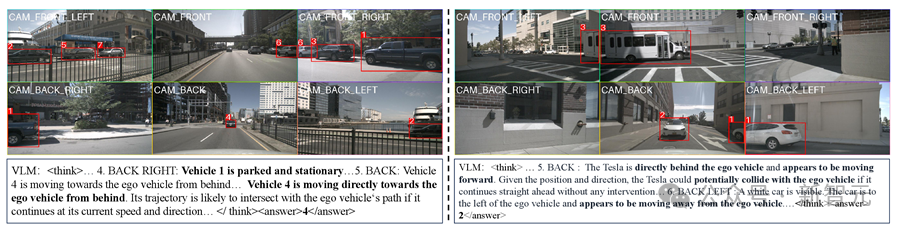
如下图所示,在对抗车辆选择任务中,VLM关键车辆选择器通过多视角画面推理交通关系,有效的分析场景并且选择了合适的安全关键车辆。
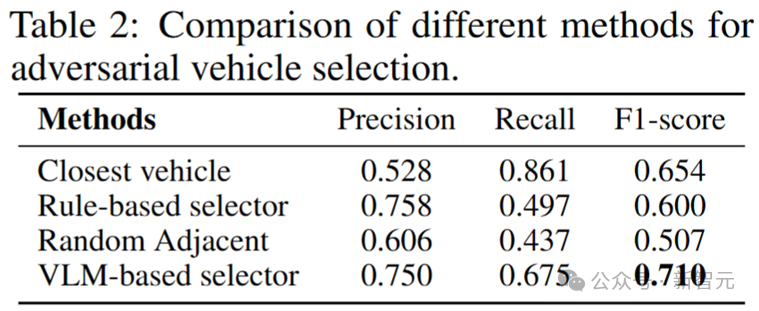
如下表所示,VLM关键车辆选择器兼顾了精度与召回率,识别出的目标车辆更符合真实交通逻辑,明显优于基线方法。这保证了后续生成的安全关键车辆模拟的高效率以及场景的丰富度。
作者介绍
本文由浙江大学与哈工大(深圳)的研究团队共同完成,感谢所有参与的作者。以下为部分作者简介:
周家葳,哈工大(深圳)硕士研究生,研究方向为自动驾驶内容生成与世界模型。
吕林烨,哈工大(深圳)博士研究生,主要关注人工智能安全,涵盖自动驾驶与大语言模型。
李渝,浙江大学「百人计划」研究员,长期从事人工智能软硬件安全与测试方法研究。


