在人工智能领域,“大模型”和“大语言模型”这两个词经常被提及,很多人甚至把它们当成了同义词。其实,这两者之间存在本质的区别。今天,我就带你深入剖析什么是大模型,什么是大语言模型(LLM),它们的区别在哪里,以及如何利用这些模型提升你的项目效率。文章干货满满,适合AI爱好者、开发者和企业决策者阅读!🚀
 在这里插入图片描述
在这里插入图片描述
一、大模型到底是什么?
“大模型”(Foundation Model)是指基于海量数据训练出来的通用人工智能模型。它们是拥有庞大的参数规模,通常达到百亿、千亿级别,具备强大的泛化能力,能够适应多种任务,并支持微调以满足特定应用需求。
大模型的核心特征:
- 参数规模巨大:通常是百亿甚至千亿级别的参数,模型越大,理论上理解和生成能力越强。
- 通用能力强:不仅能完成单一任务,而是能在多种任务中表现优异。
- 支持微调:可以根据具体业务需求进行二次训练,提升特定领域的表现。
- 跨模态能力:不仅限于文本,还能处理图像、音频、视频等多种数据类型。
换句话说,大模型是AI领域的“万能工具”,主要是看你用它做什么!
二、大语言模型(LLM)是什么?
大语言模型(Large Language Model,简称LLM)是大模型的一个子集,专注于处理自然语言文本。它们通过海量文本数据训练,能够理解、生成、翻译、总结和对话等多种语言任务。
典型的大语言模型包括:
- ChatGPT(GPT-4o)
- Claude
- 千问
- DeepSeek
这些模型专注于文本处理,广泛应用于智能客服、内容生成、机器翻译、文本分析等领域。
三、大模型 vs 大语言模型:核心区别
对比维度 | 大模型(Foundation Model) | 大语言模型(LLM) |
定义 | 泛指所有基于大规模数据训练的AI模型 | 仅指基于文本训练的语言模型 |
任务范围 | 语言、图像、视频、音频、3D等多模态 | 主要处理自然语言任务 |
代表模型 | GPT-4、Gemini、Midjourney、Whisper等 | ChatGPT、Claude、千问等 |
应用场景 | 对话、代码生成、图像生成、视频生成、语音合成等 | 自然语言理解、文本生成、翻译、对话 |
四、大模型的分类详解
根据任务和模态的不同,大模型可以细分为以下几类:
类型 | 代表模型 | 主要功能 |
大语言模型 | ChatGPT、Claude、DeepSeek | 文字理解与生成 |
图像生成模型 | Stable Diffusion、Midjourney、DALL·E 3 | 生成高质量图像 |
视频生成模型 | Runway Gen-2、Pika Labs、Sora | 视频内容生成 |
语音/音频模型 | Whisper(语音转文字)、Mistral(音乐生成) | 语音识别与音频生成 |
多模态大模型 | Gemini、GPT-4V | 同时处理图像和文本等多种模态 |
代码大模型 | CodeLlama、StarCoder、DeepSeek Coder | 代码生成与辅助编程 |
这说明,大模型不仅仅是“语言模型”,它们在图像、视频、音频等领域同样发挥着巨大作用。
五、如何利用大模型API实现多模态AI应用?
对于开发者和企业来说,想要快速接入各种大模型,最便捷的方式就是通过API调用。
六、获取大模型API的两种途径
方式一:通过“OpenAI官网”获取API Key(国外)
步骤1:访问OpenAI官网
在浏览器中输入OpenAI官网的地址,进入官方网站主页。https://www.openai.com
步骤2:创建或登录账户
- 点击右上角的“Sign Up”进行注册,或选择“Login”登录已有账户。
- 完成相关的账户信息填写和验证,确保账户的安全性。
步骤3:进入API管理界面
登录后,导航至“API Keys”部分,通常位于用户中心或设置页面中。
步骤4:生成新的API Key
- 在API Keys页面,点击“Create new key”按钮。
- 按照提示完成API Key的创建过程,并将生成的Key妥善保存在安全的地方,避免泄露。🔒
 生成API Key
生成API Key
使用 OpenAI API代码
现在你已经拥有了 API Key 并完成了充值,接下来是如何在你的项目中使用 GPT-4.0 API。以下是一个简单的 Python 示例,展示如何调用 API 生成文本:
复制import openai
import os
# 设置 API Key
openai.api_key = os.getenv("OPENAI_API_KEY")
# 调用 GPT-4.0 API
response = openai.Completion.create(
model="gpt-4.0-turbo",
prompt="鲁迅与周树人的关系。",
max_tokens=100
)
# 打印响应内容
print(response.choices[0].text.strip())方式二:通过“能用AI”获取API Key(国内)
针对国内用户,由于部分海外服务访问限制,可以通过国内平台“能用AI”获取API Key。
步骤1:访问能用AI工具
在浏览器中打开能用AI进入主页https://ai.nengyongai.cn/register?aff=PEeJ
步骤2:进入API管理界面
登录后,导航至API管理页面。
 在这里插入图片描述
在这里插入图片描述
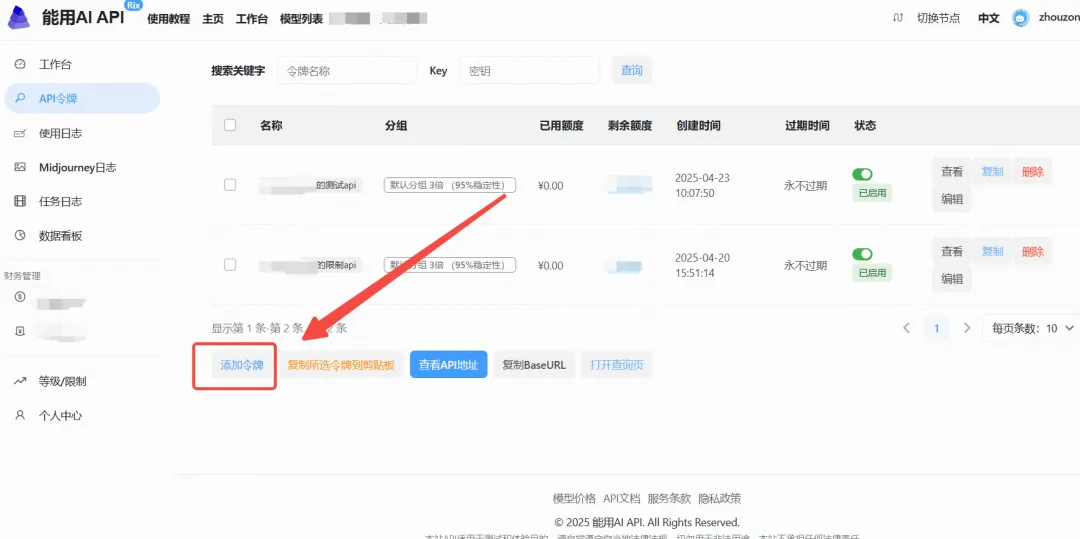
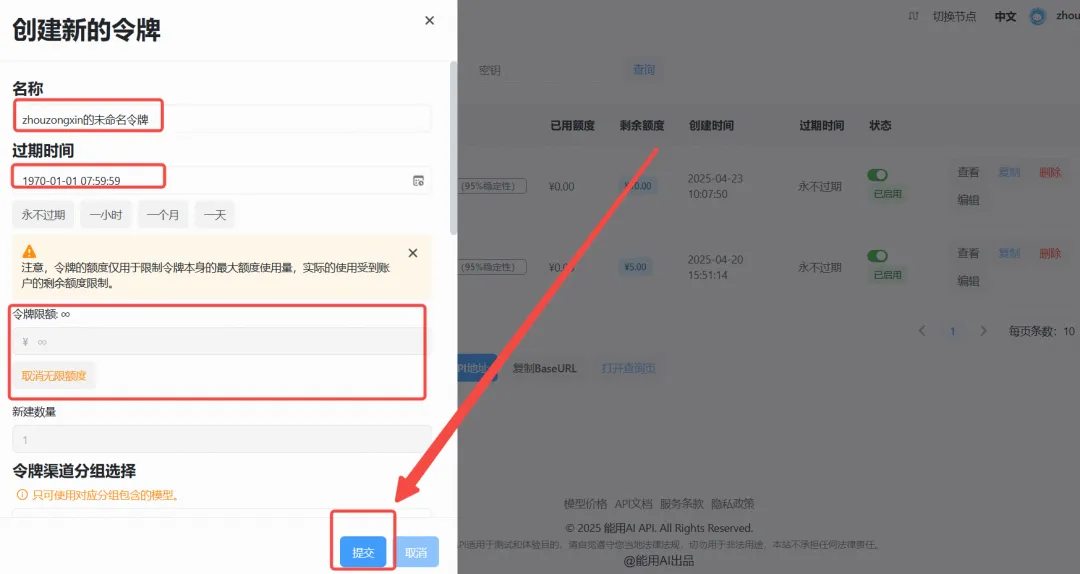
步骤3:生成新的API Key
- 点击“添加令牌”按钮。
- 创建成功后,点击“查看KEY”按钮,获取你的API Key。
 在这里插入图片描述
在这里插入图片描述

使用OpenAI API的实战教程
拥有了API Key后,接下来就是如何在你的项目中调用OpenAI API了。以下以Python为例,详细展示如何进行调用。
1.可以调用的模型
复制gpt-3.5-turbo gpt-3.5-turbo-1106 gpt-3.5-turbo-0125 gpt-3.5-16K gpt-4 gpt-4-1106-preview gpt-4-0125-preview gpt-4-1106-vision-preview gpt-4-turbo-2024-04-09 gpt-4o-2024-05-13 gpt-4-32K claude-2 claude-3-opus-20240229 claude-3-sonnet-20240229
 在这里插入图片描述
在这里插入图片描述
2.Python示例代码(基础)
基本使用:直接调用,没有设置系统提示词的代码
复制from openai import OpenAI
client = OpenAI(
api_key="这里是能用AI的api_key",
base_url="https://ai.nengyongai.cn/v1"
)
response = client.chat.completions.create(
messages=[
# 把用户提示词传进来content
{'role': 'user', 'content': "鲁迅为什么打周树人?"},
],
model='gpt-4', # 上面写了可以调用的模型
stream=True # 一定要设置True
)
for chunk in response:
print(chunk.choices[0].delta.content, end="", flush=True)3.Python示例代码(高阶)
进阶代码:根据用户反馈的问题,用GPT进行问题分类
复制from openai import OpenAI
# 创建OpenAI客户端
client = OpenAI(
api_key="your_api_key", # 你自己创建创建的Key
base_url="https://ai.nengyongai.cn/v1"
)
def api(content):
print()
# 这里是系统提示词
sysContent = f"请对下面的内容进行分类,并且描述出对应分类的理由。你只需要根据用户的内容输出下面几种类型:bug类型,用户体验问题,用户吐槽." \
f"输出格式:[类型]-[问题:{content}]-[分析的理由]"
response = client.chat.completions.create(
messages=[
# 把系统提示词传进来sysContent
{'role': 'system', 'content': sysContent},
# 把用户提示词传进来content
{'role': 'user', 'content': content},
],
# 这是模型
model='gpt-4', # 上面写了可以调用的模型
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end="", flush=True)
if __name__ == '__main__':
content = "这个页面不太好看"
api(content) 在这里插入图片描述
在这里插入图片描述
总结与展望
通过本文的详细介绍,你已经掌握了如何获取和使用OpenAI API Key的基本流程。