近期,搜索型 Agent 的热度持续攀升⸺从 OpenAI 的 Deep Research 到各类学术探索,「多轮检索 + ⼯具调⽤ + 深度推理」的新范式正在深刻改变 AI 获取和整合信息的⽅式。但如何让这些 Agent 能⼒持续提升,达到接近⼈类的表现⽔平,仍然是⼀个核⼼挑战。
⽬前主流的训练⽅法是可验证奖励强化学习(RLVR):给定任务题⽬和标准答案,⽤最终预测结果的正确性作为奖励信号来训练 Agent。然⽽,这种⽅法⾯临着⼀个根本性的瓶颈:要让 Agent 变强,需要大量「高质量任务 + 可验证答案」的数据支撑。 而现实情况是:
人工标注:成本⾼昂,特别是跨⼯具链的标注数据难以复⽤;
离线合成:难以把控合成质量,仍依赖⼈⼯校验,且验证成本居⾼不下;
扩展困境:即便有⾜够的离线合成任务,如何让训练难度⾃适应地跟随 Agent 能⼒提升?
那么,是否存在⼀种⽅法,能让 Agent 在无需人工标注的情况下,通过与外部真实世界的交互,自主生成训练任务、实现自我驱动的进化?

论⽂标题:Search Self-Play: Pushing the Frontier of Agent Capability without Supervision
研究团队:阿⾥巴巴夸克基座⼤模型 × 北京⼤学 × 中⼭⼤学
⽂章链接:https://arxiv.org/abs/2510.18821
代码仓库:https://github.com/Alibaba-Quark/SSP=
来⾃阿⾥巴巴夸克、北京⼤学、中⼭⼤学的研究者提出了⼀种新的解决⽅案:搜索自博弈 Search Self-play(SSP)⸺⼀种⾯向深度搜索 Agent 的⾃我博弈训练范式。其核⼼思路是:让⼀个模型同时扮演两个⻆⾊⸺「出题者」和「解题者」,它们在对抗训练中共同进化,使训练难度随着模型能⼒动态提升,最终形成⼀个⽆需⼈⼯标注的动态博弈⾃我进化过程。
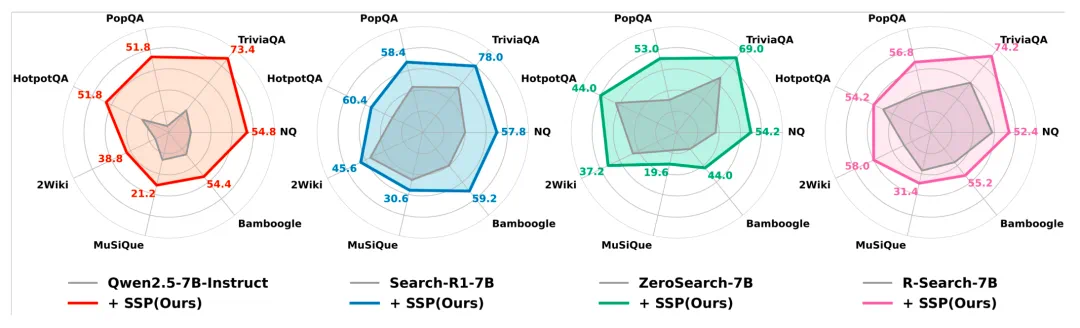
通过⼤量试验,研究者发现经过 SSP ⽅法的训练,多个开源深度搜索模型(Search-R1、ZeroSearch、R-Search)都能在原本⽔平上进⼀步显著提升,在通⽤的 Qwen2.5-base 模型上,平均成功率更是达到了惊⼈的 26.4 分,并且整个训练过程没有⽤到任何监督信息!
💡 方法概览
搜索⾃博弈的核⼼设计是让同⼀个⼤语⾔模型在不同的系统提示下,轮流扮演「出题者(Proposer)」和「解题者(Solver)」两个⻆⾊。
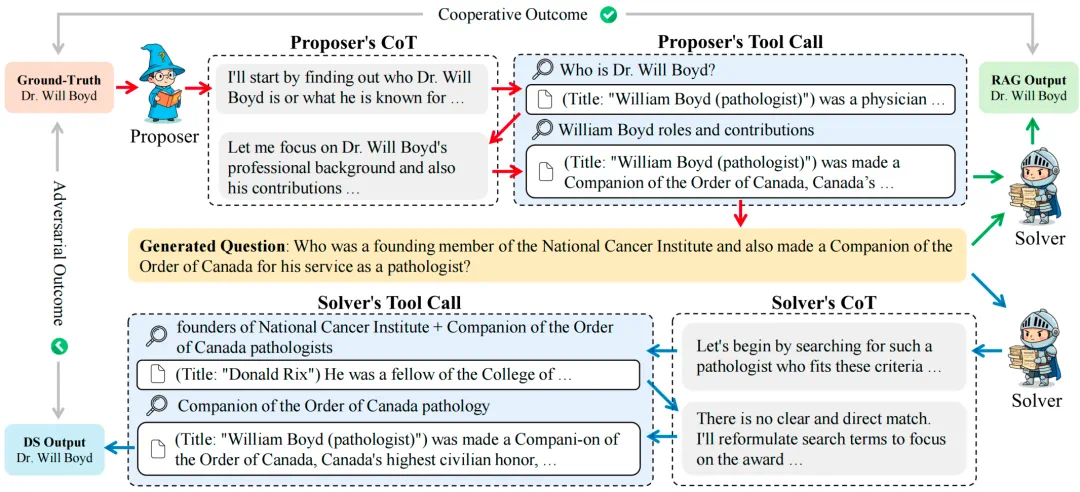
如上图所示,搜索⾃博弈分为三个阶段:
首先是问题生成阶段:Proposer 围绕⼀个参考答案,通过多轮搜索收集外部信息,反向构造出「有⼀定难度、但可解且答案唯⼀」的问题。
其次是协作验证阶段:为了防⽌ Proposer ⽣成对于 Solver 来说⽆解或模糊的问题(即「Reward Hack」现象),系统会将 Proposer 检索到的⽂档作为 RAG 材料,让 Solver 在有参考信息的条件下(不调⽤搜索⼯具)尝试回答。只有 Solver 能够正确作答的问题,才会进⼊对抗博弈。
最后是对抗求解阶段:通过验证的问题会交给 Solver,此时 Solver 可以使⽤完整的搜索功能,自行通过多轮推理、检索来解答问题。根据 Solver 的表现,Proposer 和 Solver 各⾃获得奖励信号并在线更新策略。
这种设计的巧妙之处在于:通过⼯具检索,问题⽣成不仅依赖于出题模型本身的能⼒,还可以利⽤海量外部的知识,突破了仅凭模型内部知识出题的局限;同时通过 solver 的协作验证,保证题⽬和答案的⼀致性和可解答性。
在「零和对抗」的训练中,出题者和解题者相互制衡、共同进化,形成⼀个动态提升的训练过程。
🛠 建模与优化:零和博弈机制
搜索⾃博弈可以建模为⼀个 min-max 优化问题。令 μ 为 Proposer 策略, ν 为 Solver 策略, a^∗ 为参考答案,Q (・)、A (・) 分别是问题和答案的提取函数,r (・,・) 为判定答案是否等价的⼆元奖励函数。那么 SSP 要优化的⽬标是:
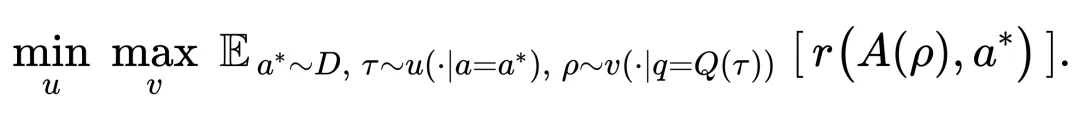
这意味着 Proposer 希望最⼩化 Solver 的成功率(出更难的题),⽽ Solver 则希望最⼤化⾃⼰的成功率(提升解题能⼒)。
为了保证 Proposer ⽣成的问题既可解⼜唯⼀,研究引⼊了协作约束:将 Proposer 出题轨迹中所有的检索结果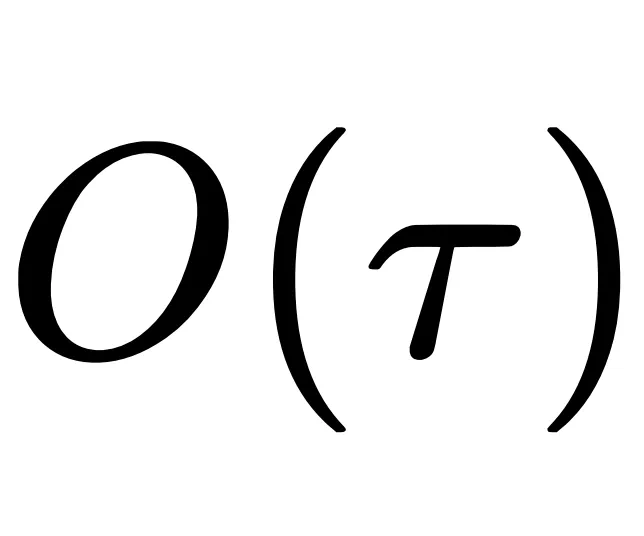 作为 RAG 材料提供给不调⽤搜索⼯具的 Solver,要求其在不使⽤搜索⼯具的开卷情况下能够正确解答,即:
作为 RAG 材料提供给不调⽤搜索⼯具的 Solver,要求其在不使⽤搜索⼯具的开卷情况下能够正确解答,即:
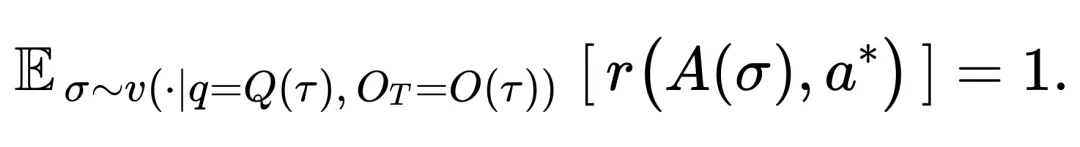
在实际训练中,研究采⽤拒绝采样来优化这⼀约束:只有通过 RAG 验证的问题才会进⼊对抗阶段。随后对两个⻆⾊进⾏在线交替优化:
Solver 优化:采⽤ Group Relative Policy Optimization(GRPO)算法,在每个问题上进⾏多轨迹探索,以组均值作为基线来稳定优势估计并更新策略。
Proposer 优化:采⽤ REINFORCE 算法,根据「Solver 平均成功率」的互补信号(1−成功率)来优化,从⽽⽣成更具挑战性但仍可验证的问题。
两个⻆⾊在每⼀步训练中都在线更新,形成紧密耦合、持续共同进化的零和博弈。

📊 主要实验结果
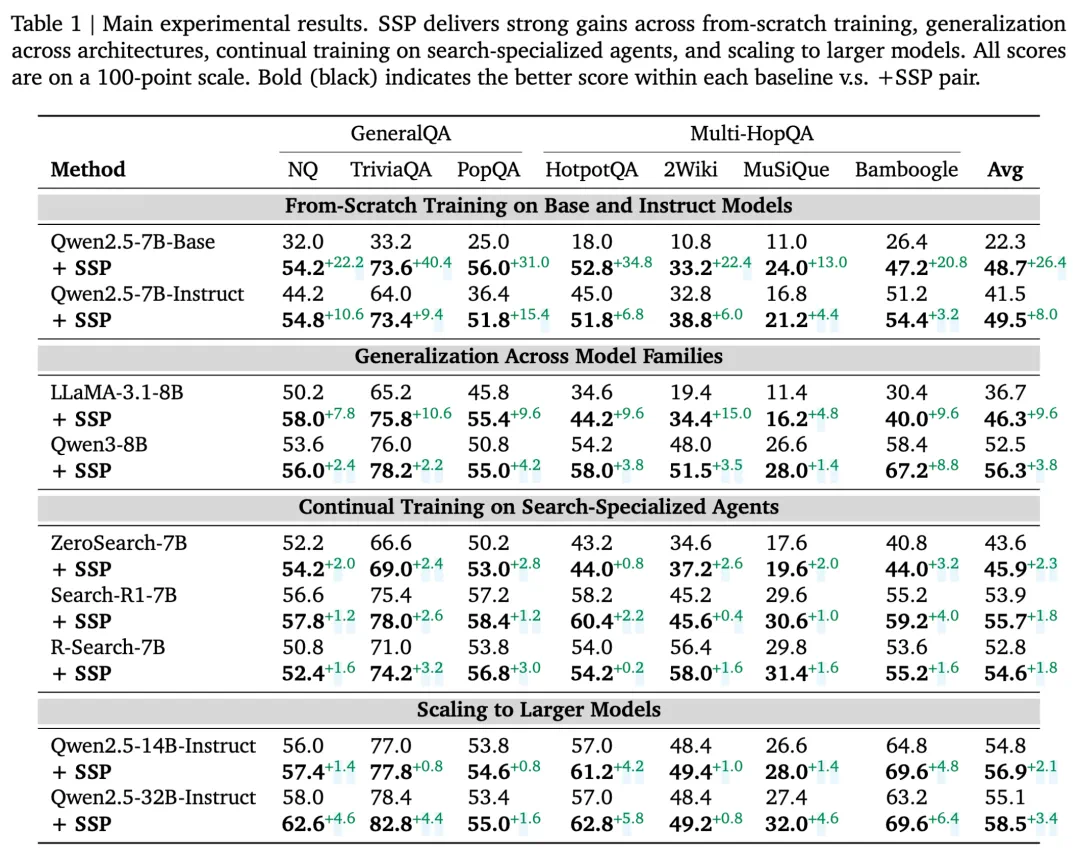
研究者在七⼤开放领域问答基准上对 SSP 进⾏了全⾯评估,包括 NQ、TriviaQA、PopQA、HotpotQA、2Wiki、MuSiQue 和 Bamboogle,覆盖了从单跳到多跳、从简单到复杂的各类问答任务。
实验设置涵盖了多个维度:「从零训练」(未经专⻔训练的基础模型)、「持续训练」(在已有能⼒基础上继续提升)、「跨架构泛化」(不同架构的模型)以及「不同⼤⼩的模型泛化」(扩展到更⼤规模模型)。
实验结果显示,在所有实验设置下,SSP 在问答基准测试中均持续超越基线方法, 表明 SSP 是⼀种⾼效且通⽤的增强智能体能⼒的⽅法。
SSP 在⽆任何外部监督的情况下,从零训练能给模型带来显著提升。这⼀增益在未经过指令微调的基础模型上尤为突出,例如,对 Qwen2.5-7B-Base 应⽤ SSP 可实现平均 26.4 分的显著提升,在 TriviaQA 上更是获得 40.4 分的惊人提升。SSP 对指令微调模型同样有效,将 Qwen2.5-7B-Instruct 的平均性能提升 8.0 分。
值得注意的是,SSP 可作为有效的持续训练策略,拓展 Agent 的能力边界。尽管⼀些强⼤的开源模型已在⾯向搜索的任务上经过⼤量数据的⼴泛训练(如 Search-R1、R-Search),SSP 仍能实现性能提升。这种性能增益在扩展到更⼤模型时依然保持:对 Qwen2.5-32B-Instruct 应⽤ SSP 后,其在七个基准测试中的五项达到 SOTA 水平。
🌱 启示与展望:让模型去「为难」模型
搜索⾃博弈并⾮局限于搜索任务。它代表了⼀种新的范式:
让智能体在自我出题与解题的循环中,自我验证、自我进化,最终达到 superhuman 的水平。
研究者相信,这种「⾃我博弈」的训练范式具有极⼤潜⼒:⼈⼯标注与校验的速度远远赶不上模型能⼒提升;让模型去「为难」模型将会成为未来⼤模型训练的必然选择。
未来,我们或许会看到越来越多类似 AlphaGo Zero 的时刻⸺模型不再依赖⼈类监督,⽽是通过⾃我竞争持续突破智能的上限。