“欧洲的OpenAI”Mistral AI终于发布了首款推理模型——Magistral。
然而再一次遭到网友质疑:怎么又不跟最新版Qwen和DeepSeek R1 0528对比?
(此前该公司发布Ministral 3B/8B时,声称“始终优于同行”,却没有对比Qwen2.5)
 图片
图片
 图片
图片
在该模型发布的前几个小时,Mistral AI的CEO Arthur Mensch在接受炉边访谈时声称即将发布的Magistral能够与其他所有竞争对手相抗衡。
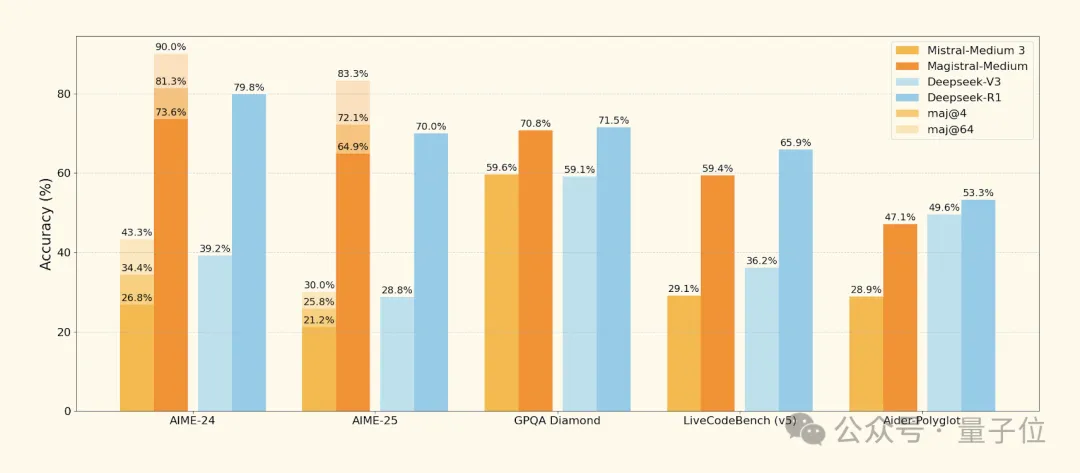
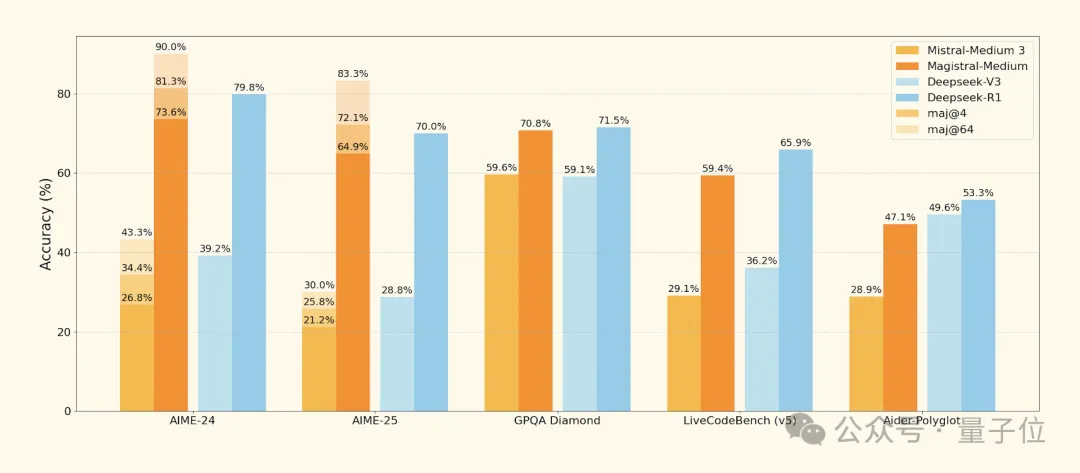
在官方展示的基准测试结果中,DeepSeek-R1的数据确实不是最新的(在AIME-25数学测试中,DeepSeek-R1-0528的准确率已经从旧版的70%提升至87.5%),并且比较行列里完全不见Qwen的身影。
 图片
图片
不过,与同公司初期模型Mistral Medium 3相比,该框架在AIME-24上的准确率提升了50%。
此次Magistral发布了两种版本:
Magistral Small——24B参数的开源权重版本,可在Apache 2.0许可下自行部署。
Magistral Medium——更强大的、面向企业的版本,在Amazon SageMaker上提供。
 图片
图片
专为透明推理而设计
在Magistral发布之前,Mistral AI的CEO Arthur Mensch在访谈中提到:
“从历史上看,我们看到美国的模型用英语进行推理,中国的模型更擅长用中文进行推理。”
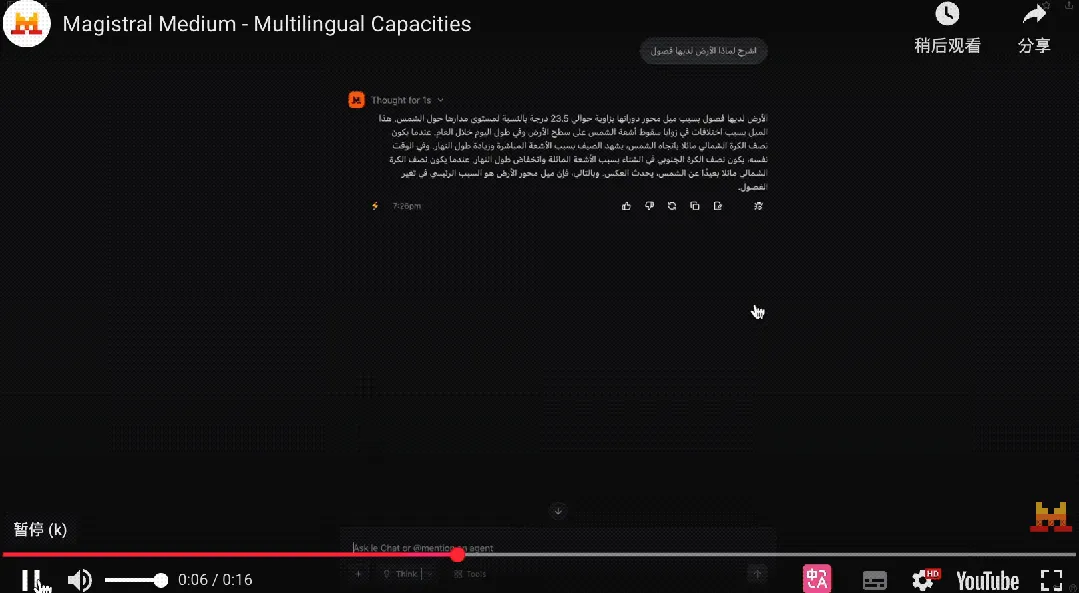
于是,这次Magistral的一个亮点就是支持多语言推理,尤其是解决了主流模型用欧洲语言的推理效果不如本土语言的缺陷。

下面的例子展示了在Le Chat中,使用Magistral Medium的阿拉伯语提示和响应。
 图片
图片
与通用模型不同的是,Magistral针对多步逻辑进行了微调,提升了可解释性,并在用户的语言中提供了可追溯的思考过程,能够实现大规模实时推理。
下面的例子展示了重力、摩擦和碰撞的单次物理模拟,在预览中使用的是Magistral Medium。
 图片
图片
就好像Magistral不是黑箱预言家,而是一个能陪你「摆事实、讲道理」的智能伙伴。
并且,在Le Chat中,通过Flash Answers,Magistral Medium的token吞吐量比大多数竞争对手快10倍。
这就能够实现大规模的实时推理和用户反馈。
 图片
图片
作为Mistral推出的首个基于纯强化学习(RL)训练的推理大模型,Magistral采用改进的Group Relative Policy Optimization(GRPO)算法。
直接通过RL训练,不依赖任何现有推理模型的蒸馏数据(如DeepSeek-R1需SFT预热)。
通过消除KL散度惩罚、动态调整探索阈值和基于组归一化的优势计算,在AIME-24数学基准上实现从26.8%到73.6%的准确率跃升。
 图片
图片
首创异步分布式训练架构,通过Generators持续生成、Trainers异步更新的设计,配合动态批处理优化,实现高效的大规模RL训练。
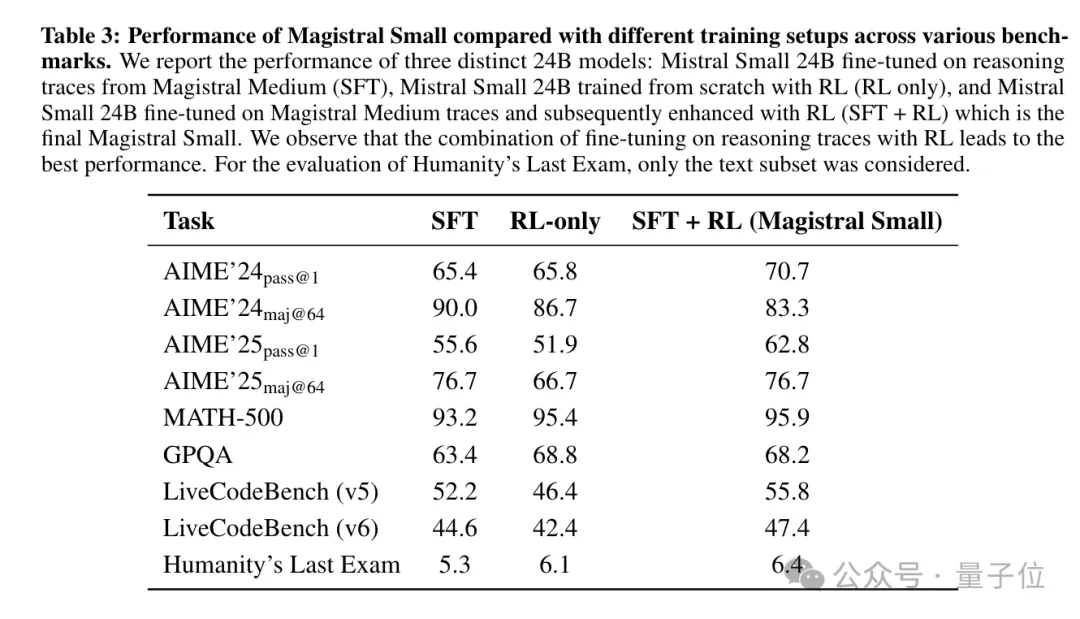
还反直觉地发现纯文本RL训练可提升多模态性能(如MMMU-Pro-Vision提升12%),并验证RL对小模型同样有效(24B的Magistral Small在AIME-24准确率达70.7%)。
 图片
图片
这些创新使Magistral在无需预训练蒸馏的情况下,以纯RL方式为LLM的强化学习训练提供了新范式。
One More Thing
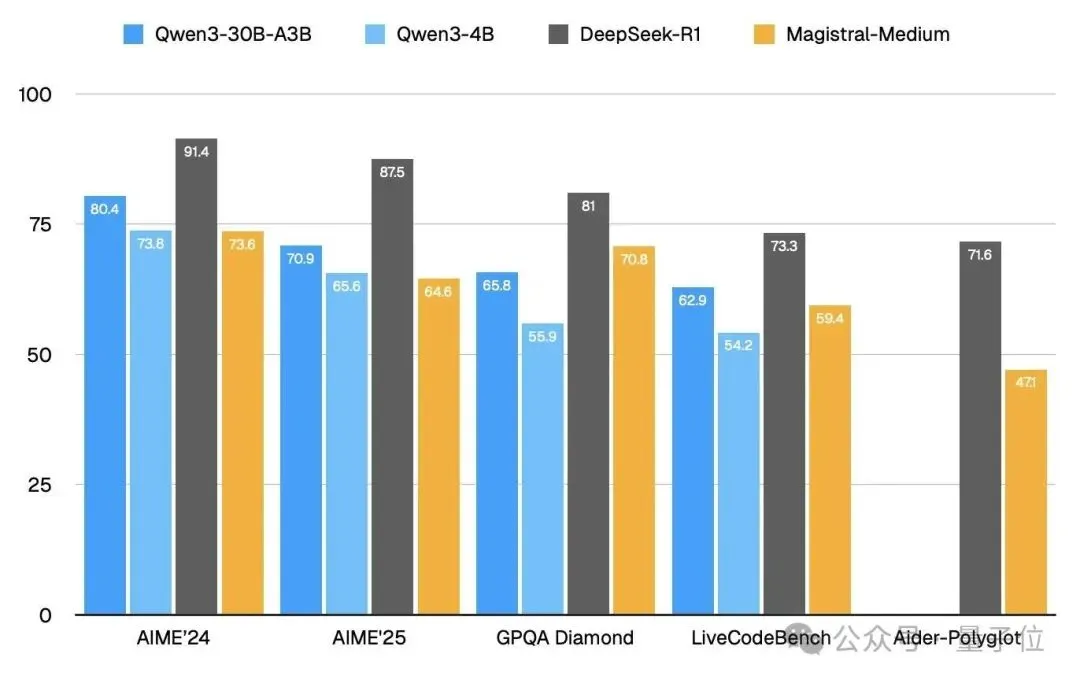
官方没有给出Magistral与最新版Qwen和R1的对比,网友来代劳了。
 图片
图片
从结果可以看出,Qwen 4B与该模型相近,小型的30B MoE效果更好,R1最新版就更不用说了(doge)。
并且,由于“欧洲的OpenAI”越来越不Open,Stability AI前CEO建议Mistral AI应该争取真正的开源来占据开源的领导地位。
 图片
图片
参考链接:
[1]https://mistral.ai/news/magistral
[2]https://x.com/dylan522p/status/1932563462963507589
[3]https://x.com/arthurmensch/status/1932451932406415531


