Qwen

阿里通义千问 Qwen Code v0.5.0 正式发布,号称让 AI 编程“跳出命令行”
AI在线 12 月 26 日消息,今天下午,通义千问 Qwen 官方公众号发文宣布,Qwen Code v0.5.0 版本更新正式发布。 此次更新除了功能增强以外,还标志着 Qwen Code 从“命令行工具”向“开发生态”迈进的关键一步。 根据介绍,用户可在终端窗口中同时运行四个 Qwen Code 实例,分别处理不同任务,而不必等待一个对话结束后再开始另一个对话窗口。

修图 AI 模型 Qwen-Image-Edit-2511 开源上线:提升角色一致性、增强几何推理
AI在线 12 月 25 日消息,阿里通义 Qwen 团队于 12 月 23 日上线推出 Qwen-Image-Edit-2511 全新图像编辑模型,在 Qwen-Image-Edit-2509 基础上,减轻图像漂移、提升人物一致性、集成 LoRA 能力、增强工业设计生成能力,以及强化几何推理能力。 该模型作为通义家族在视觉生成领域的最新尝试,专门针对“图像编辑”场景进行了优化。 不同于传统的文生图模型(Text-to-Image),该模型主要解决的是“在保持原图主体结构不变的前提下,对特定区域进行精准修改”这一行业难题,为开发者和设计师提供了更高效的 AI 辅助工具。
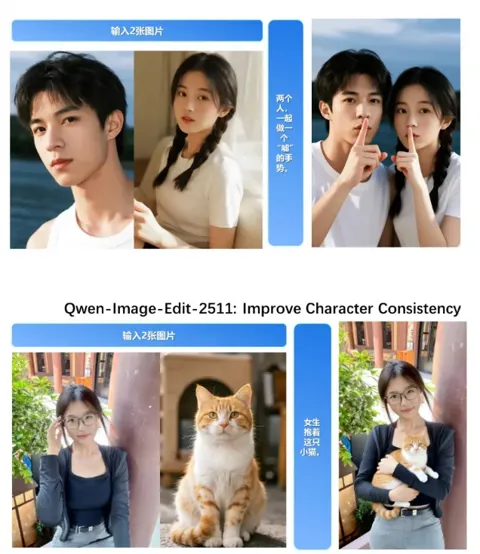
阿里 Qwen 发布新一代图像编辑模型Qwen-Image-Edit-2511,人物一致性大幅提升
阿里巴巴旗下的Qwen团队近期在 AI 视觉领域再次发力,正式发布了全新升级的图像编辑模型 Qwen-Image-Edit-2511。 针对以往 AI 在修图时容易导致“人脸变形”或“身份丢失”的痛点,该模型实现了质的飞跃,能够确保在进行创意修改的同时,精准保留原图人物的面部特征。 根据Qwen官方在Hugging Face上公布的信息,这款模型是此前版本的重大迭代。

阿里开源图像生成模型 Qwen-Image-Layered:能像 PS 一样分图层编辑
AI在线 12 月 22 日消息,今天下午,阿里宣布开源全新图像生成模型 Qwen-Image-Layered,首次在模型内实现 PS 级的图层理解与图像生成。 新模型采用自研创新架构,可将图片“拆解”成多个图层,可类比为使用 Photoshop 分层作图修图,号称能够实现几乎“零漂移”的 AI 图像精准编辑,彻底解决 AI 生图的一致性难题,加速大模型在专业设计领域的现实落地。 给定⼀张图像,Qwen-Image-Layered 可将其分解为若⼲个 RGBA 图层:分解完成后,编辑操作仅作⽤于⽬标图层,将其与其他内容物理隔离,从根本上确保了编辑的⼀致性。

开源AI大模型大比拼:国产三强并列第一,硅谷巨头陷落!
在最近的开源 AI 大模型评比中,中国的开源 AI 技术再一次展现出强大的实力,DeepSeek、Qwen 和 Kimi 三款模型被评为影响力并列第一,这一消息引发了业界的广泛关注。 由 AI 研究员 Nathan Lambert 和 Florian Brand 共同发布的这份榜单,涵盖了35家机构,其中超过一半是中国团队。 这显示出中国在开源领域的迅猛发展,和美国企业的闭源选择形成鲜明对比。

Meta新AI模型 “牛油果” 将于明年推出,蒸馏学习引发业界关注
在全球科技竞争日益激烈的背景下,美国科技巨头 Meta(前身为 Facebook)近日宣布,旗下新一代 AI 大模型 “牛油果”(Avocado)有望在2024年第一季度正式发布。 这个新模型在开发过程中,采用了阿里巴巴的 Qwen 模型进行蒸馏学习,意图通过这一技术提升自身的 AI 能力。 知情人士透露,“牛油果” 可能会以 “闭源” 的形式推出,这意味着 Meta 将对该模型的访问权限进行严格控制,甚至可能会向外部客户出售使用权。
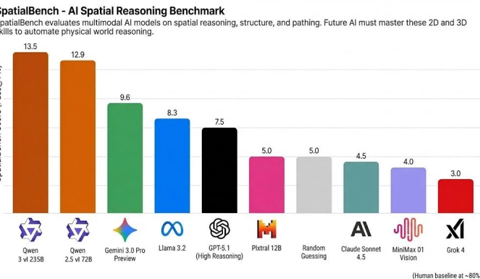
超越Gemini3、GPT5.1,阿里千问登顶空间推理全球冠军
11月26日,空间推理基准测试SpatialBench更新了最新一期榜单,阿里千问的视觉理解模型Qwen3-VL、Qwen2.5-VL位列头两名,超越Gemini 3、GPT-5.1、Claude Sonnet4.5等国际顶尖模型。 据了解,SpatialBench是一项近年来兴起的第三方空间推理基准测试榜单,主要聚焦多模态模型在空间、结构、路径等方面的综合推理能力,被AI社区视为是衡量“具身智能”进展的新兴测试标准之一。 SpatialBench不仅测试模型已知的知识,还测试模型在二维和三维空间中“感知”和操控抽象概念的能力,这对具身智能的落地尤为关键。

阿里“千问 App”横空出世:一周下载量破千万,刷新 AI 应用增长记录!
据 AIbase 报道,阿里巴巴旗下的 AI 助手“千问 App”自公测以来表现抢眼,仅一周时间下载量便突破1000万次,创下 AI 应用史上最快的增长记录,超越了 ChatGPT、Sora 和 DeepSeek 等知名产品。 Qwen 模型家族的强劲表现此次千问 App 的爆发式增长,得益于阿里巴巴 Qwen 模型家族长期以来的技术积累和市场铺垫。 自2023年全面开源以来,阿里 Qwen 模型已在全球范围内超越 Llama、Deepseek 等竞争对手,成为性能强劲且应用范围最广的开源大模型之一,全球累计下载量已突破6亿次。

中国已成为全球开源 AI 大模型的最大提供者
在北京举行的2025开放原子开发者大会上,中国工程院院士倪光南强调,中国已成为全球开源人工智能大模型的最大提供者,特别是如 Qwen、DeepSeek 和 Kimi 等模型在国际评估中表现突出。 他指出,开源技术正成为推动全球信息技术发展的重要力量,尤其是在快速发展的 AI 领域。 倪光南表示,开源的趋势顺应了时代的发展需求,体现了全球信息技术领域的创新活力。

夸克AI眼镜S1发布会定档11月27日
阿里巴巴正式进军智能穿戴新赛道。 夸克宣布,其首款自研旗舰级双显AI眼镜——夸克AI眼镜S1 发布会将于 11月27日 举行。 目前该产品已开启预售,并在“双11”期间一举拿下天猫智能眼镜品牌榜、店铺榜、XR品类榜三项销量第一,表现相当抢眼。

阿里“千问”项目秘密启动:基于Qwen模型,全面对标ChatGPT发起C端AI未来之战
据《科创板日报》报道,阿里巴巴已秘密启动代号为**“千问”的重大项目,旨在基于其最强模型Qwen,打造一款同名个人AI助手——千问APP。 此举被阿里核心管理层视为“AI时代的未来之战”**,标志着阿里正式加入全球AI应用的顶级竞赛,全面对标当前市场领导者ChatGPT。 阿里希望借助Qwen模型的开源技术优势,赢得这场竞争。

Qwen拿半成品刷下AIME’25满分,给别人留点面子吧……
鱼羊 发自 凹非寺. 量子位 | 公众号 QbitAI半成品模型,已经刷下高难度数学推理测试AIME 25满分战绩。 开源之王Qwen又在深夜放大招了。

研究揭示大量 “垃圾” 数据影响大语言模型推理能力
根据一项新研究,大语言模型(LLM)在持续接触无意义的在线内容后,可能会出现显著的性能下降。 这项研究表明,这些模型的推理能力和自信心都受到影响,引发了对它们长期健康的担忧。 研究团队来自多个美国大学,提出了 “LLM 脑衰退假说”,借鉴了人类在过度接触无脑在线内容时可能造成的认知损害。

比Qwen3-Max更Max?夸克抢先用上最新闭源模型
最强搜索「牵手」最强模型,能碰撞出什么火花? Qwen 最新闭源模型,让夸克先用上了。 10 月 23 日,一向不爱出风头的夸克上线了对话助手,可以让用户在一个 App 内即可完成信息查找、问题解答与任务处理,实现了 AI 搜索与对话的深度融合。

阿里 Qwen 推出 Deep Research:一键生成报告、网页与播客
近日,阿里巴巴旗下 Qwen 团队 宣布对其 Qwen Deep Research 工具进行重大升级。 这一功能可在网页版 Qwen Chat(ChatGPT 竞品)中激活,为用户带来从研究、生成到发布的完整闭环体验。 此次更新的最大亮点是:用户不仅能生成带有引文的综合研究报告,还可一键创建 交互式网页 与 多说话者播客。

阿里亲身入局具身智能!Qwen内部组团,通义千问技术负责人带队
衡宇 发自 凹非寺. 量子位 | 公众号 QbitAIQwen团队内部组建了一个全新的具身智能小分队! 这一消息由通义千问技术负责人林俊旸(Justin Lin)在上对外公开。

Qwen要入局机器人了:林俊旸官宣成立具身智能团队
已经成为开源模型领头羊的 Qwen,终于要开始入局机器人了。 昨天,阿里通义千问大语言模型负责人林俊旸在社交媒体上官宣,他们在 Qwen 内部组建了一个小型机器人、具身智能团队,旨在提供更强基座模型,同时表示「多模态基础模型正转变为基础智能体,这些智能体可以利用工具和记忆通过强化学习进行长程推理,它们绝对应该从虚拟世界走向物理世界」。 这一举动让关注 Qwen 的开发者兴奋不已。

AIME'25满分炸场!Qwen一波七连发,全家桶大更新
它来了,它来了! 新一代旗舰模型Qwen3-Max带着满分成绩,正式地来了——国产大模型首次在AIME25和HMMT这两个数学评测榜单拿下100分! 和前不久Qwen3-Max-Preview一致,参数量依旧是超万亿的规模。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉