谢赛宁团队新作正在引起热议!
一直以来,作为文生图基石的CLIP模型主要基于英文数据训练,但实际上,全球互联网仍有超过50%的非英文数据。
为了将CLIP模型进一步扩展,研究人员需要搞定两大“拦路虎”:
- 缺乏处理非英语数据的筛选方法;
- 现有多语言CLIP的英语性能比纯英语版本差(即所谓的“多语言诅咒”)。
而谢赛宁团队正是在这两方面取得突破。他们提出了首个基于全球数据从头训练的CLIP——MetaCLIP 2,通过扩展元数据、优化筛选和提升模型容量,斩获了以下成果:
- 搭建了能处理300多种语言的CLIP数据整理流程。
- 打破了“多语言诅咒”,不仅没有影响英语任务的表现,而且反倒还提升了。
论文一作Yung-Sung Chuang(MIT博士生、现Meta实习生)激动表示:
是时候告别语言过滤器了!
刚被小扎从OpenAI挖走的Lucas Beyer也出来对这一观点表示认同,顺带还感谢了论文中的引用:
很高兴看到我们提出并始终倡导的“NoFilter”理念能在MetaCLIP 2中得到应用。
这就是正确的道路!
这也引来了谢赛宁本人的回应:
早在MetaCLIP中,团队的目标也是NoFilter(与其搞复杂过滤,不如相信原始数据的价值)。
我也认为NoFilter才是正道。
下面详细来看MetaCLIP 2所采用的方法。
概括而言,为了让CLIP模型能从全球数据中学习,MetaCLIP 2采用了三大关键创新:
- 构建全球元数据
- 实施全球筛选算法
- 构建全球模型的训练框架
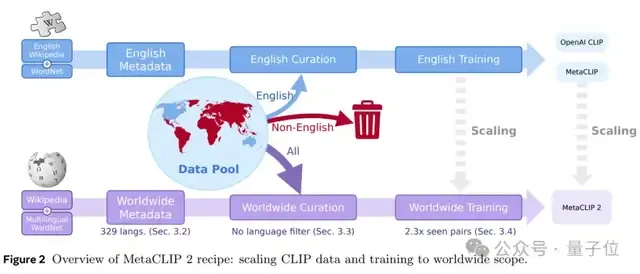
开始之前,论文先回顾了原始MetaCLIP所采用的思路。
简单说,其筛选逻辑主要分三步:
- 从英语WordNet、维基百科提取50万个 “视觉概念”,组成元数据列表M;
- 用这些概念匹配图像-文本对的描述文字(逐个检查文本里的内容,看能否匹配到M里的词条);
- 设定一个阈值t,通过 “平衡机制”(控制头部/尾部概念的比例)筛选数据,确保“猫”“狗”这类常见概念和“深海生物”“小众建筑”这类少见概念分布合理。
顺便一提,OpenAI CLIP将t设置为20k,而MetaCLIP为了适配十亿级英语数据,把t调高到170k ,让平衡策略更适合大规模数据。
而MetaCLIP 2,正是在英文MetaCLIP的基础上,进一步优化了架构和流程。
这第一步非常简单,无非是将之前的元数据扩展到300多种语言。
具体而言,它现在包含了多语言的WordNet和各国维基百科的词汇,有点像给每种语言都编了一套 “视觉概念词典”。
然后用算法给每种语言“量身筛数据”。
先是识别文字是哪种语言,再用对应语言的“字典”去匹配图像-文字对。
同时给每种语言设立单独的筛选标准(比如控制“常见概念”和“少见概念”的比例),确保每种语言的数据分布合理,不会出现某类内容过多的情况。
下图为MetaCLIP 2筛选全球多语言图像-文本对的伪代码(用Python/NumPy风格编写):
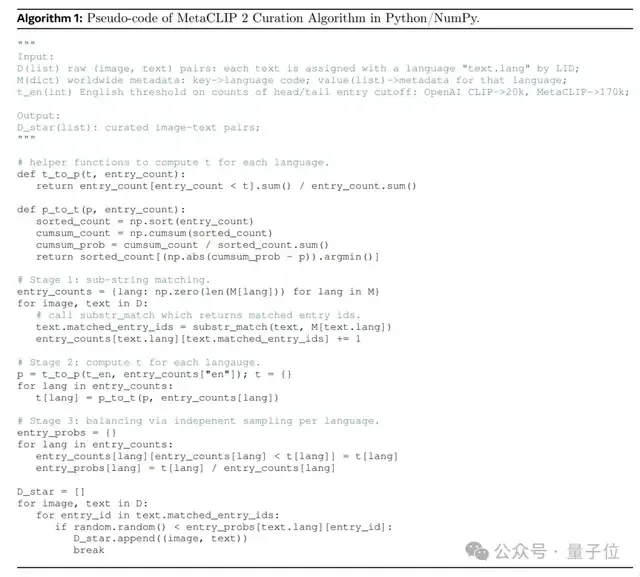
最后再调整训练策略,避免“顾此失彼”。
一方面,鉴于全球数据变多了,所以团队按比例增加了训练时“见过的样本量”(比如扩大2.3倍),保证英语样本量不减少。
另一方面,团队发现模型大小很关键——小一点的模型(如ViT-L/14)还会受“多语言诅咒”,但大一点的ViT-H/14能打破诅咒,让英语和非英语能力一起提升。
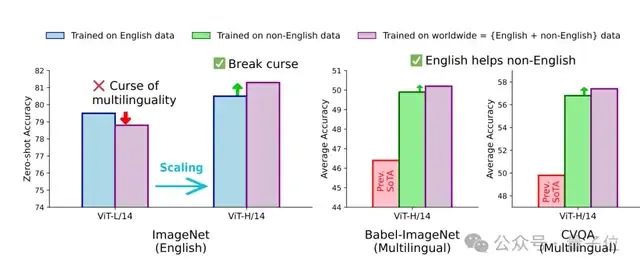
p.s. 大语言模型中的“多语言诅咒”是指,当模型在多语言数据上进行训练时,出现某些特定语言(尤其是原本表现较好的语言,如英语 )性能下降的现象。
采用以上数据筛选方法,MetaCLIP 2与NoFilter理念形成了深度协同——筛选逻辑的本质从“语言过滤”(如直接排除非英语数据)转向“概念平衡”,从“排除数据”(如用单一标准排除数据)转向“优化分布”。
为了验证方法的有效性,团队基于全网公开数据(英语占44%,非英语占56%)进行了实验。
训练配置上,团队基本沿用OpenAI CLIP/MetaCLIP的参数,仅调整样本量(如ViT-H/14用290亿样本)和模型容量。
实验结果显示,MetaCLIP 2在多项测试中表现亮眼:
首先,它打破了大语言模型领域存在的“多语言诅咒”,证明学了非英语数据后,英语能力不仅没有下降,甚至反而变强了。
例如,它在ImageNet识别日常物品上准确率达到81.3%,超过纯英语CLIP的80.5%。
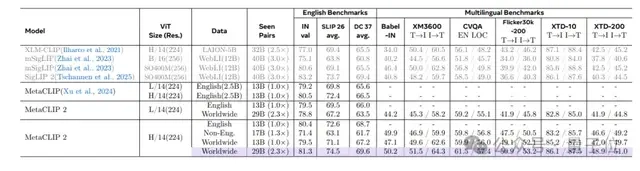
其次,它在多语言测试中(如用280种语言给图片分类、跨36种语言搜图),成绩远超之前的mSigLIP、SigLIP 2等模型。
还是上面这张图,它在Babel-ImageNet多语言图像分类任务里,取得了50.2%的准确率;在XM3600图像到文本检索任务中,检索匹配的准确率达到64.3%。
更有意思的是,MetaCLIP 2不仅更懂“文化多样性”,而且嵌入质量也更优。
一方面,它在文化多样性任务(如地理定位)上表现更优,如在Dollar Street、GLDv2等数据集上,全球数据训练的模型准确率显著高于纯英语或纯非英语模型。
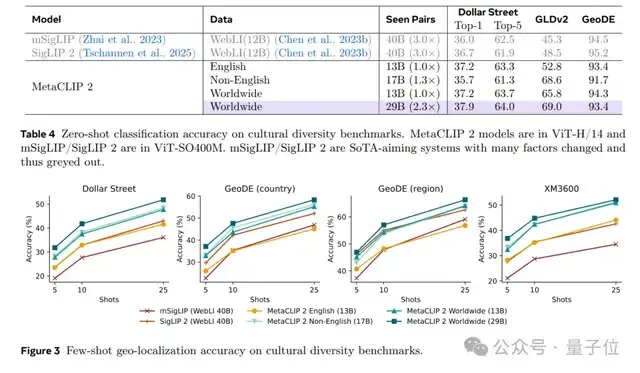
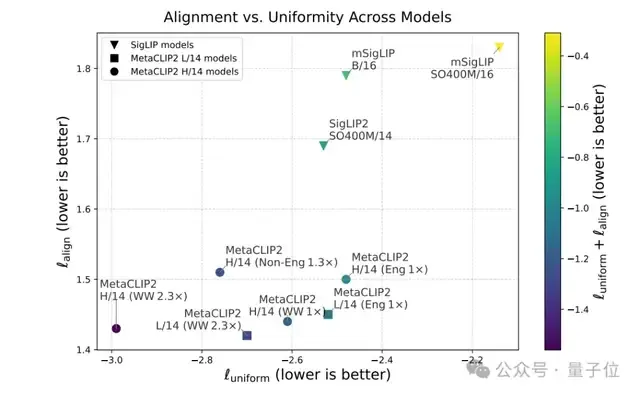
另一方面,它在对齐性(图像-文本相关性)和均匀性(视觉嵌入分布)上的得分同样更优。
划重点,目前相关数据和代码均已开源了~
论文: https://arxiv.org/abs/2507.22062 代码地址: https://github.com/facebookresearch/MetaCLIP


