大家伙儿都晓得,语音理解和合成发展得飞快,背后离不开大规模又高质量的语音数据集支撑。特别是语音识别(ASR)和语音合成(TTS),两者算是语音AI的头牌主角。但要说到咱们川渝地区的方言——川渝话,约1.2亿人都在用哦——它的研究就有点儿“捉襟见肘”了。咋个整呢?就是标注资源太缺,现有的数据量又小又散,搞得ASR、TTS表现都一般,根本没法跟普通话比。 你看,目前公开的粤语语料库规模小、风格单一、标注信息也少,得亏前一阵我们发布的一个大规模的多标签、多领域粤语语音语料库WenetSpeech-Yue,这才缓解了粤语语料库稀缺的情况。而四川话数据比之粤语则更加稀少,开源的几个小数据集,数据量少嘞很,场景也太有限。川渝方言评测集更是稀缺,KeSpeech里头能找到点西南官话测试集,基本算“凤毛麟角”。而且这些语料多数只给了语音和文本的对齐信息,缺少说话人年龄、情绪啥的多维度标注,限制了自监督学习和多任务训练的发展,直接导致主流系统在川渝方言上“打了折扣”,在真实应用中表现差强人意。 这不,西北工业大学音频语音与语言处理研究组(ASLP@NPU)联合希尔贝壳、中国电信AI研究院、南京大学和WeNet开源社区,终于硬核推出了WenetSpeech-Chuan——首个大规模多维度标注的川渝方言语音语料库!超过一万小时,涵盖9大领域,包含ASR转录、文本置信度、说话人情感、年龄、性别、语音质量评分等超丰富信息。堪称方言语音数据里的“顶流”。 不仅如此,他们还带来了川渝方言评测新基准——WSC-Eval。它包括两个部分:WSC-Eval-ASR(含人工标注的多场景测试集,Easy和Hard声学条件齐备),以及WSC-Eval-TTS(轻松和高难度子集),用来测评模型的标准表现和泛化能力。 实验效果咋个说呢?用WenetSpeech-Chuan训练的模型,不管是ASR还是TTS,都甩开其他公开系统好几条街,性能甚至能硬刚商业级别,表现巴适得很!这说明啥?说明这个数据集和处理流程硬核得很,堪称川渝方言语音AI的“游戏改变者”。下面我们一块看哈论文中都讲了些啥子。 |

摘要
方言领域缺乏大规模开源数据,严重制约了语音技术的发展,这一问题在使用广泛的四川方言中尤为突出。为填补这一关键空白,我们推出了 WenetSpeech-Chuan,一个拥有 1 万小时、注释丰富的语料库,并基于我们自主设计的完整方言语音处理框架——Chuan-Pipeline构建而成。为了支持严格的评估并展示该语料库的有效性,我们还发布了手工校验转录的高质量 ASR 和 TTS 基准集 WenetSpeech-Chuan-Eval。实验表明,在开源系统中,使用 WenetSpeech-Chuan 训练的模型已达到当前最优性能,甚至在某些场景下可与商业系统媲美。作为目前最大的四川方言开源语料库,WenetSpeech-Chuan 不仅降低了方言语音研究的门槛,也在推动 AI 公平性与缓解语音技术偏见方面发挥着重要作用。语料库、基准测试、模型及相关材料均已在我们的 项目主页上公开发布。
•论文题目:WenetSpeech-Chuan: A Large-Scale Sichuanese Corpus with Rich Annotation for Dialectal Speech Processing
•合作单位:希尔贝壳、电信、南京大学、WeNet开源社区
•作者列表:戴宇航、张子萸、王帅、李龙豪、郭钊、左天伦、王水源、薛鸿飞、王成有、王晴、徐昕、卜辉、李杰、康健、张彬彬、谢磊
•论文预印版:https://arxiv.org/abs/2509.18004
•仓库地址:https://github.com/ASLP-lab/WenetSpeech-Chuan
•Demo展示:https://aslp-lab.github.io/WenetSpeech-Chuan/
•WenetSpeech-Chuan数据集地址:https://huggingface.co/datasets/ASLP-lab/WenetSpeech-Chuan
•WSC-Eval-ASR: https://huggingface.co/datasets/ASLP-lab/WSC-ASR-eval
•WSC-Eval-TTS: https://huggingface.co/datasets/ASLP-lab/WSC-TTS-eval
•ASR模型地址:https://huggingface.co/ASLP-lab/WSChuan-ASR
•TTS模型地址:https://huggingface.co/ASLP-lab/WSChuan-TTS

 扫码直接看论文
扫码直接看论文
背景动机
近年来,大规模开源数据集极大地推动了自动语音识别(ASR)和语音合成(TTS)任务的发展。然而,当这些任务应用于口音或方言语音时,仍面临诸多挑战。已有研究表明,ASR 系统在处理方言时常因发音差异和声学失配而表现不佳,甚至在面对轻微口音的语音时也会出现明显性能下降。同样,关于带口音的 TTS 的研究也指出,准确建模口音变化极具难度。
在众多汉语方言中,这一问题在四川-重庆方言(以下简称四川方言)中尤为突出。四川方言是中国西南地区最主要的语言之一,使用人数约 1.2 亿人。其声调系统、词汇和语法与普通话存在显著差异,形成了清晰的语言区隔。然而,由于缺乏专门面向方言的大规模数据集,主流 ASR 和 TTS 系统在四川话语者中的表现大幅下降,迫切需要一个面向四川方言的大规模开源语料库。然而,现有的开源资源在数据规模和多样性方面仍严重不足。
目前公开可用的四川方言数据集仅包括 MagicData 发布的两个小型语料库:MagicData Conversation(4.53 小时)和 MagicData Daily-Use(6.4 小时)。虽然 KeSpeech 数据集也包含了部分带西南官话口音的样本,但这些语音更多是带口音的普通话,而非真正的四川方言。由于数据规模小、覆盖面窄,这些资源无法支撑鲁棒的 ASR 和 TTS 模型训练。
基于我们在 WenetSpeech 系列项目中构建大规模语音语料的经验,我们此次提出了 WenetSpeech-Chuan,以解决四川方言语音资源的关键缺口。WenetSpeech-Chuan 是一个包含超过 1 万小时四川方言语音的高质量注释语料库,涵盖短视频、综艺、直播等多个真实使用场景。为支持语料库构建与后续研究,我们还提出了 Chuan-Pipeline—— 一个完整的四川方言语音数据处理框架,用于从原始语音中高效构建高质量语料资源。最后,我们发布了两个精细校验的基准测试集 —— WSC-Eval-ASR与 WSC-Eval-TTS,以支持严格、可复现的系统评估。
Chuan-Pipeline
为了构建 WenetSpeech-Chuan 数据集,我们提出了一个完整的语音数据处理流程 —— Chuan-Pipeline,如下图所示。该流程能够系统性地将原始、未标注的音频转换为适用于高质量 ASR 和 TTS 研究的丰富注释语料。
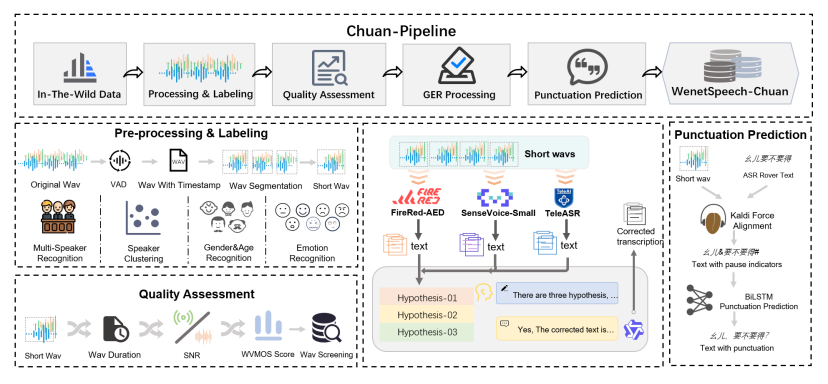
Chuan-Pipeline概览
预处理与标注阶段
该阶段主要包括数据获取、切分处理以及多维度副语言(paralinguistic)信息的标注。数据采集从在线视频平台抓取元数据开始,用于筛选可能包含四川话的内容。在通过人工初步确认方言后,音频流将进入以下处理流程:
•语音活动检测(VAD)与切分:通过 VAD 技术将长音频分割为 5–25 秒的语音片段,同时剔除静音和噪声等非语音部分。
•单说话人筛选与聚类:首先使用 pyannote 工具包识别出单说话人的语音片段,然后利用 CAM++ 模型提取说话人嵌入向量并进行聚类,为每位说话人分配统一 ID。
•副语言信息标注:
○性别识别:使用一个预训练分类器,准确率达 98.7%。
○年龄估计:基于 Vox-Profile 基准,划分为儿童、青少年、青年、中年和老年五个阶段。
○情感识别:使用 Emotion2vec 和 SenseVoice 的预测结果进行多数投票,覆盖七类情感(高兴、生气、悲伤、中性、恐惧、惊讶、厌恶)。
音频质量评估
为了确保语料质量,我们引入自动音频质量评估机制。该机制以对齐后的语音片段为输入,提取如音频时长、信噪比(SNR)等特征,并计算词级虚拟主观评分(WVMOS)以估测感知音质。质量较差的语音样本将被剔除。
LLM-GER 转录处理框架
为了提升四川话的自动语音识别精度,我们在前人研究基础上提出了名为 LLM-GER的转录框架(Large Language Model-based Generative Error Correction based ROVER)。
•第一步:使用三种不同的 ASR 系统(FireRed-ASR、SenseVoice-Small 和 TeleASR)分别生成初步转录文本;
•第二步:利用 Qwen3 大模型进行错误修复与融合。通过设计好的 Prompt,大模型能够理解方言表达,并进行语义一致、不改变 token 数量的纠错操作;
•第三步:生成四份转录结果后,根据它们之间的一致性计算最终的转录置信度。
该方法综合了多个 ASR 系统的优势,同时利用 LLM 对方言表达的强理解能力,实现高质量的四川话转录。实验证明,相较于单一系统,LLM-GER 平均可提升约 15%的转录准确率。
通过 Chuan-Pipeline,我们实现了四川方言大规模、高质量语音数据的系统化构建,为后续多语言、多任务语音研究提供了坚实基础。
标点预测
准确带标点的转录文本对 TTS 训练至关重要,但仅依靠文本的标点预测往往与实际语音停顿不匹配。为此,我们提出一种融合音频与文本的多模态标点预测方法。
•音频部分:使用 Kaldi 模型对音频与文本进行强制对齐,获取词语时间戳及停顿时长。根据阈值(如短停顿 0.25 秒,长停顿 0.5 秒)将停顿划分为短停顿和长停顿。
•文本部分:利用双向 LSTM(BiLSTM)标点模型对停顿候选处进行标点预测:短停顿处插入逗号,长停顿处插入句号、问号或感叹号。
•阈值调整:通过人工反馈不断迭代优化停顿时长阈值,确保标点与实际语音停顿高度匹配。
WenetSpeech-Chuan
通过应用Chuan-Pipeline处理收集到的多源原始数据,我们构建了WenetSpeech-Chuan语料库,一个大规模、多标签、多领域的四川话语音语料库。本节将详细介绍该语料库,包括其元数据、音频格式、数据多样性,以及训练集和评估集的设计原则。
数据规模与置信度
我们为每段音频分配了一个置信度,衡量ASR转录的质量。如下表所示,我们选择了置信度高于0.90的3,714小时“强标签”数据;置信度介于0.60到0.90之间的6,299小时“弱标签”数据则保存在元数据中,供半监督或其他用途使用。综上,WenetSpeech-Chuan共包含10,013小时原始音频。
表1 WenetSpeech-Chuan标签置信度分布
领域分布
下图总结了WenetSpeech-Chuan的来源领域,共包含9个类别。短视频占比最大(52.83%),其次是娱乐类(20.08%)和直播类(18.35%)。纪录片、有声书、访谈、新闻、朗读和戏剧等其他领域比例较小,但丰富了数据集的多样性。
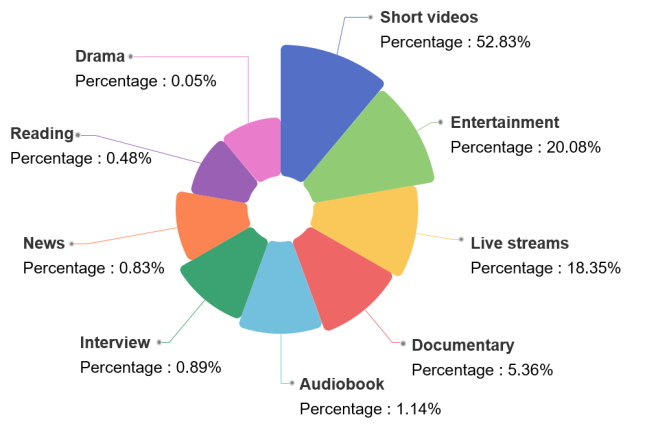
数据领域分类
质量分布
如下图所示,基于WVMOS指标计算的音频质量得分主要集中在2.5到4.0区间,3.0到3.5之间有显著峰值。该分布表明语料库大部分数据质量处于中高水平,兼顾了干净录音与真实环境噪声,适合用于训练通用的鲁棒语音模型。
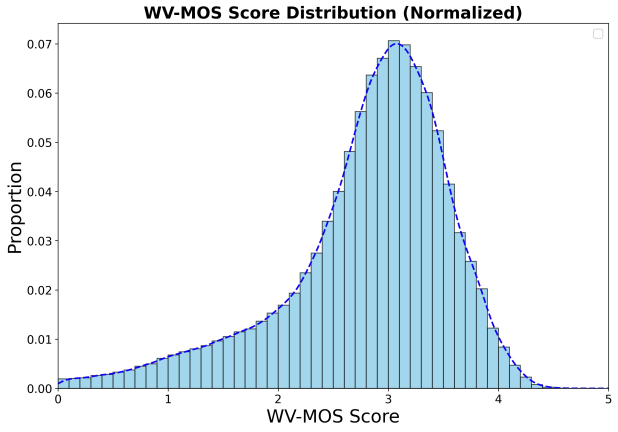
音频质量WVMOS分数分布
WSC-Eval评估集
为了解决四川话ASR和TTS缺乏标准评估基准的问题,我们构建了WSC-Eval-ASR和WSC-Eval-TTS两个针对ASR和TTS的评估集,用于全面检验模型在处理四川方言上的表现。
ASR评估集:我们首先使用Chuan-Pipeline对来自多个领域的原始四川话数据进行预处理,然后由专业标注人员手动精标。此外,所有音频样本均带有说话人属性标签,包括年龄、性别和情绪状态。为了便于更细致地分析模型的性能,我们将总时长为9.7小时的数据进一步划分为“Easy”和“Hard”子集,依据来源领域和声学环境进行区分,从而实现更具层次的模型鲁棒性评估。详细统计信息见表2。
表2 WSC-Eval-ASR测试集

TTS评估集:WSC-Eval-TTS包含两个子集:WSC-Eval-TTS-easy由包含特定四川方言词汇的多领域短句组成;WSC-Eval-TTS-hard由长句和LLM生成的多风格四川方言长句组成,涵盖绕口令、民间俚语及富含感情的语句等风格。在音频提示方面,我们选取了来自MagicData及内部录音的10位说话人(5男5女),每人录制200个句子,确保性别、年龄和口音的多样性与平衡。
实验
ASR部分
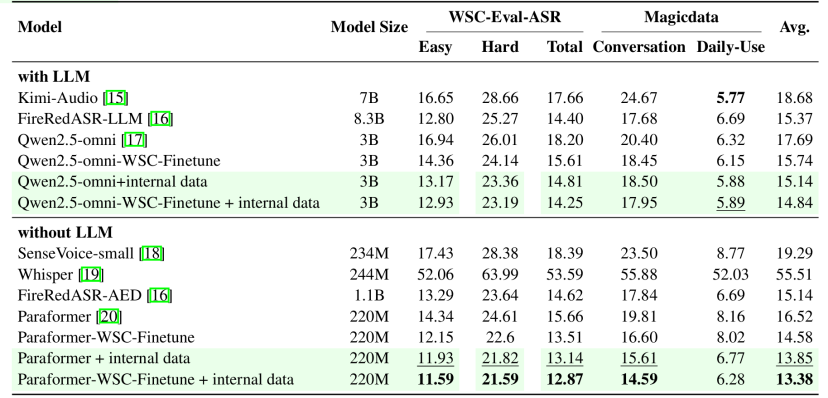
为验证所提出数据集的有效性,我们在三个测试集(WSC-Eval-ASR、MagicData-Conversation、MagicData-Daily-Use)上评估了多种 ASR 模型,涵盖专用识别系统(如 Paraformer、Whisper)及多模态大模型(如 Kimi-Audio、Qwen2.5-omni)。实验结果表明,开源模型 FireRedASR-AED 在多个评测集上表现稳定,平均字错误率为 15.14%,优于其他系统。通过在 WenetSpeech-Chuan 上微调 Paraformer 和 Qwen2.5-omni,整体性能分别提升 11.7% 与 11.02%。进一步结合 1000 小时高质量内部方言数据训练后,Paraformer 在各测试集上平均 CER 降至 13.38%,展现出出色的迁移与适应能力。总体来看,WenetSpeech-Chuan 显著增强了模型对四川方言的识别能力,同时不影响普通话性能。
表3 ASR实验结果
TTS部分
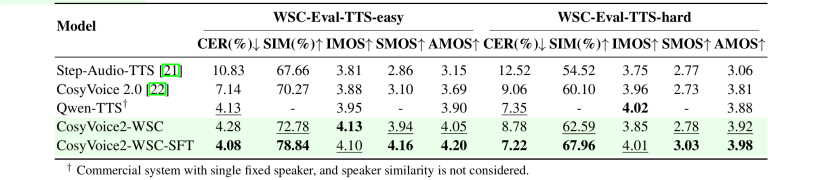
我们将 CosyVoice2-WSC 与多个支持方言的 TTS 模型进行比较,包括 Step-Audio-TTS、CosyVoice2.0、Llasa-1B 和 Qwen-TTS。评估方法包括客观指标(字符错误率 CER、说话人相似度 SIM)和主观指标(可理解性 IMOS、说话人相似度 SMOS、方言自然度 AMOS)。AMOS 部分由 10 位四川本地人和 10 位非专业听众评分,共评估 30 条样本,覆盖不同说话人和任务难度。
结果显示,CosyVoice2-WSC 在主客观评估中均表现良好。在 easy 测试集中,其 CER 为 4.28%,接近 Qwen-TTS 的 4.13%,同时感知质量和说话人相似度更高;在 hard 测试集中,虽然 CER 稍高(8.78% 对比 7.35%),但仍保持较好的稳定性和相似度(SIM 超过 62%)。相比 Step-Audio-TTS 和原始 CosyVoice2,CosyVoice2-WSC 在准确率和听感之间取得更好平衡。
进一步微调后的 CosyVoice2-WSC-SFT 表现最优,在 easy 测试集中 CER 降至 4.08%,SIM 达 78.84%,主观评分领先;hard 集中 CER 降至 7.22%,AMOS 最佳,体现出微调对准确性和自然度的双重提升。
表4 TTS实验结果