嘿,各位AI圈的同仁们!最近AI界热议的话题可不少,但微软悄悄放出的这个“小”家伙,绝对值得咱们重点关注。微软这次没有追逐那种动辄千亿参数的“巨无霸”,反其道而行之,推出了参数规模相对小巧的Phi-4系列推理模型。但这可不是性能缩水,恰恰相反,它们在推理任务上展现出了惊人的效率和能力。
这次发布的Phi-4系列主要有两个成员:
- Phi-4-reasoning:参数规模是140亿(14B)。
- Phi-4-mini-reasoning:参数规模只有区区38亿(3.8B)。
听着参数是不是觉得不大?但可别小瞧它们,尤其是在解决那些需要“动脑子”的复杂推理任务上,比如数学和逻辑问题,Phi-4系列的表现简直是一匹黑马!
3.8B 参数,性能竟然“吊打”更大模型?这个Mini有点狂!
让我印象最深,也是最能体现“轻量化性能突破”的,就是那个只有3.8B参数的Phi-4-mini-reasoning。要知道,现在市面上随便一个有点能力的模型都得奔着7B、8B甚至几十亿去了。3.8B,这几乎是能跑在大多数稍好点电脑甚至部分高端手机上的参数量级了。
但就是这个“小不点”,在数学推理基准测试中,愣是超越了一些参数规模更大、或者经过专门优化的模型!
你知道DeepSeek-R1吧?它在代码和数学领域可是公认的强手。DeepSeek-R1的蒸馏版本(为了缩小体积而优化的版本),参数可能也在7B、8B这个级别。结果呢?我们的Phi-4-mini-reasoning在数学推理上,表现直接优于它!这不光是赢了,这简直是轻量化模型的一次正面“逆袭”。
Phi-4-mini-reasoning:3.8B参数,在数学推理任务上,性能超越DeepSeek-R1的蒸馏版本,成为轻量化推理领域的新标杆!
这事儿意味着什么?意味着咱们以后做AI推理,不一定非得依赖那些“吞金兽”级别的大模型了。对于那些对延迟要求高、对硬件成本敏感的应用场景(比如端侧AI、教育辅导APP、或者一些需要本地部署的推理任务),Phi-4-mini-reasoning提供了一个极其有吸引力的解决方案。它证明了,通过更聪明的设计和更高质量的数据,小模型也能拥有“大智慧”。
 图片
图片
14B 的全能选手:Phi-4-reasoning 的实力也不俗
当然,这个系列里还有个块头稍大一点的——Phi-4-reasoning,14B参数。如果说Mini是极致效率的代表,那14B版本就是在效率和性能之间取得更好的平衡。
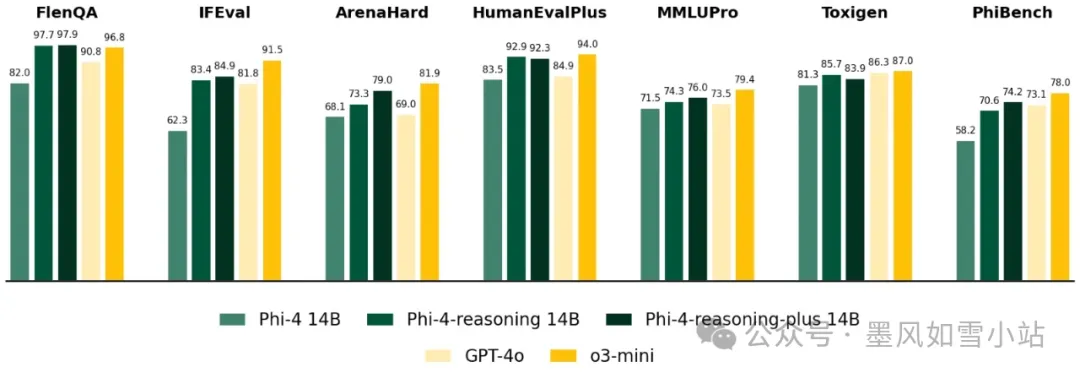
它在更广泛的推理任务中都表现出色,据说在不少评测中,性能甚至超过了OpenAI的o1-mini模型(OpenAI在小模型领域的探索)。特别是在复杂的数学和逻辑问题解决上,14B版本能处理更深、更广的推理链条。
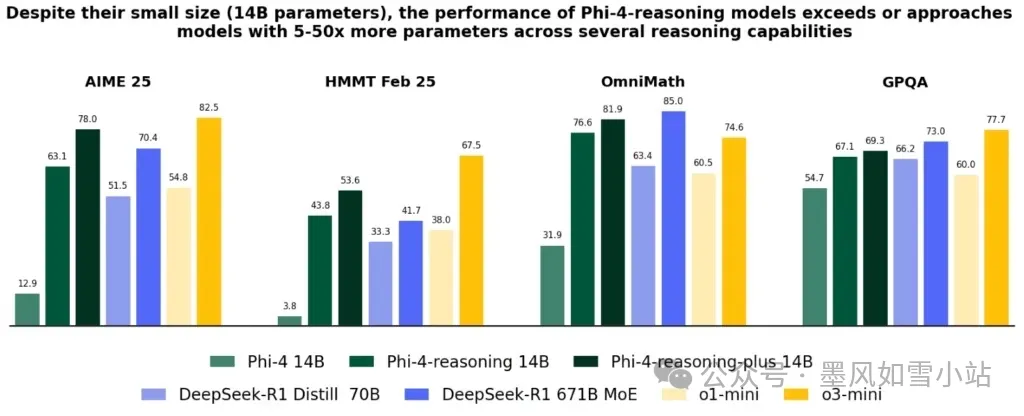
而且,更强的Phi-4-reasoning-plus版本,通过强化学习优化,在AIME(美国数学奥林匹克资格赛)这种高难度考试中,甚至打败了6710亿参数的DeepSeek-R1完整模型!这简直是“以小博大”的经典案例。
这14B模型适合那些对推理精度要求更高,同时又希望比超大模型更易部署、成本更低的场景。
“小”而“精”的秘诀:训练数据与方法是关键
Phi-4系列之所以能在轻量化下实现性能突破,很大程度上归功于其训练方法。它们是基于Phi-4基础模型,通过高质量的数据进行监督微调(SFT)得来的。特别是高质量的“可教导”提示数据集,据说一部分还是用OpenAI的o3-mini模型生成的(AI套娃?)。
这不是简单粗暴地堆砌数据,而是精选那些最能教会模型进行逻辑推理、一步步思考的“教科书级别”范例。用行内话说,就是专注于提升模型的“思维链”(Chain-of-Thought)能力。
 图片
图片
纳德拉的小目标:微软内部AI写代码比例要飙到95%?
聊到微软的AI进展,不得不提他们自家对AI的“使用心得”。微软CEO萨提亚·纳德拉之前曾公开表示,目前微软内部大约有 20%~30% 的代码已经是AI辅助或直接生成的了。
更令人震惊的是,他预测到 2030年,这个比例可能会飙升到 95%!
 图片
图片
虽然这个预测听起来有点像“凡尔赛”,而且在公开报道中直接找到纳德拉明确说出“95%”这个数字的原始出处还需进一步核实(比如Build大会等),但它无疑反映了微软对AI在软件开发领域巨大潜力的信心,以及他们内部正在大力推动AI工具(比如GitHub Copilot)的应用。
这跟Phi-4有什么关系?虽然Phi-4推理模型更侧重逻辑推理,但强大的推理能力是生成高质量代码的基础。未来,像Phi-4这样的高效推理模型很可能会被集成到GitHub Copilot这类工具的后端,让AI生成的代码逻辑更严谨、更准确,覆盖更复杂的场景。
如果这个预测成真,意味着未来的程序员角色将发生巨大转变,更多是去做需求设计、架构规划、代码审核和系统优化,而大量的具体代码实现则交给AI去完成了。这无疑是整个软件工程领域的一次潜在革命。
总结:小模型的大未来,微软走在了前面
总的来说,微软Phi-4系列推理模型的发布,特别是Phi-4-mini-reasoning的惊艳表现,有力地证明了“小而精”的路线在AI领域是完全走得通的。它们通过高质量数据和优化的训练策略,在参数量大幅缩减的情况下,实现了性能上的显著突破,尤其是在数学和逻辑推理这些“硬骨头”任务上。
 图片
图片
这不仅降低了AI部署的门槛和成本,为AI在更多设备和场景上的落地打开了大门,也为整个AI模型的研究指明了一个重要方向:不只是拼参数规模,更要拼模型效率、数据质量和训练策略的创新。
结合微软在AI生成代码方面的积极实践和宏伟目标,我们可以看到,微软正在通过模型创新和内部应用双轮驱动,加速AI技术的落地和普及。Phi-4系列,就是这股浪潮中的一个重要里程碑。
期待这些“小而美”的模型能给我们带来更多惊喜,也期待AI技术能更快更好地赋能各行各业!