微软推出了一款名为 Phi-4-mini-flash-reasoning 的全新轻量级人工智能模型。
据说,这款模型专为计算、内存或延迟受限的场景量身打造。其目标是在不依赖强大硬件的情况下,提供卓越的推理能力。
该模型构建于微软去年十二月推出的Phi-4家族基础之上,参数规模达到38亿。模型重点,则聚焦于提升数学推理方面的能力。
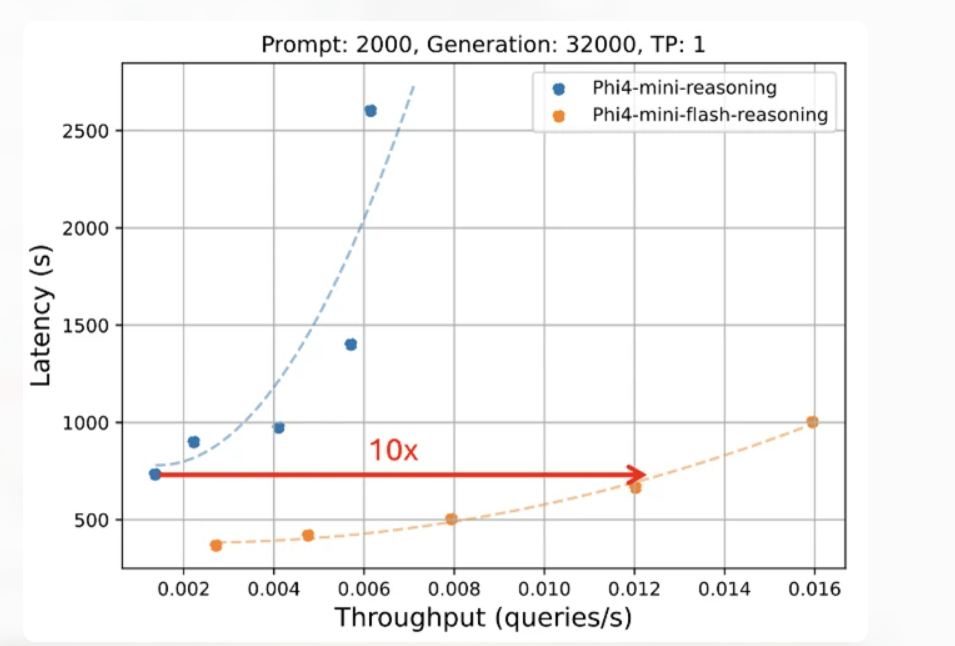
Phi-4-mini-flash-reasoning 直接带来了性能的巨大飞跃。微软方面表示,它实现了高达十倍的吞吐量提升。与其前代模型相比,新模型的平均延迟降低了二至三倍。
 图片
图片
图注:标准推理与 flash 推理的延迟与吞吐量对比,flash 在相同延迟下实现了 10 倍的吞吐量。Flash 推理在保持相同延迟响应的同时,将吞吐量提高了十倍。图源微软
需要指出的是,这些测试结果基于工业级GPU,而非模型所针对的低资源设备。即便如此,这一成绩也预示了其在目标设备上的巨大潜力。
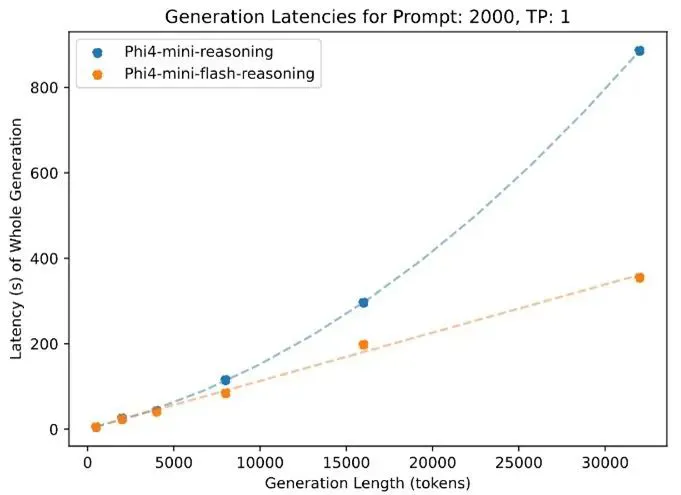
Phi-4-mini-flash-reasoning在处理长上下文方面同样表现出色。该模型支持高达 64,000个 token 的上下文窗口。即使在处理达到容量上限的长序列时,它也能保持其速度和性能。
架构革新:“闪推”机制源自SambaY与GMU
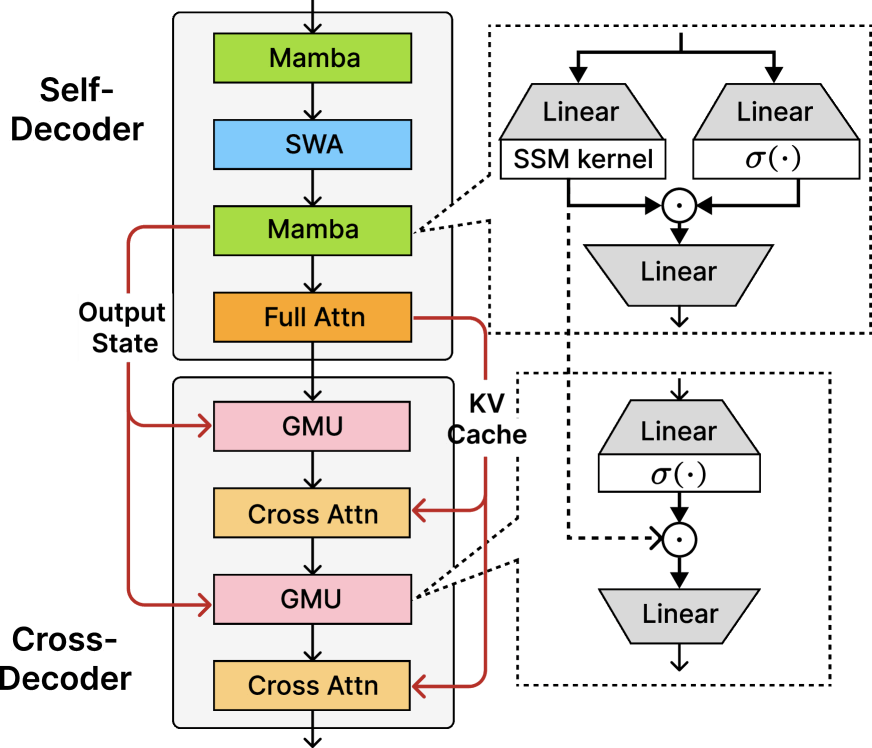
微软将此归功于SambaY设计的高效率。SambaY架构确保了处理速度的稳定,即便序列长度不断增加。
SambaY架构引入了门控内存单元(GMU)和“差分注意力”机制,构成了其技术基石。
传统的Transformer模型每一层都依赖复杂的注意力机制来判断输入内容的重要性。而门控内存单元(GMU)通过一种简化的方式,彻底改变了这一流程。
它用简单的逐元素乘法操作,替代了计算量巨大的交叉注意力运算。这种乘法运算在当前输入和前一层记忆状态之间进行。使得模型能够动态地重新校准需要关注的token,且无需承担常规的计算开销。
 图片
图片
图注:Phi-4-mini-flash-reasoning 在处理 32,000 个 token 时的延迟远低于标准推理模型,突显了 flash 方法的高效性。图源微软
SambaY 实际上混合了多种注意力机制,形成一种高效的混合解码器架构。模型中只有一个全注意力层,负责创建一个键值缓存(key-value cache)。后续的层级可以直接访问这个共享的键值缓存。而门控内存单元(GMU)则取代了大约一半的交叉注意力层。
这些层级通过轻量级的乘法运算共享信息,大幅降低了计算复杂度,这种独特的设计显著削减了内存使用和计算需求。
在传统模型中,随着序列长度的增加,内存与处理器之间的数据传输量会急剧攀升。但在SambaY架构下,即使序列长度增加,数据传输量也基本保持平稳。
超越基准:卓越的推理能力
 图片
图片
论文地址:https://arxiv.org/abs/2507.06607v1 图源微软
新模型的“flash”版本在各项基准测试中脱颖而出。Phi-4-mini-flash-reasoning的训练使用了与Phi-4-mini相同的五万亿token数据集。
训练数据中包含了大量为提升推理能力而生成的合成数据。整个训练过程动用了1000块A100 GPU,持续了14天。
 图片
图片
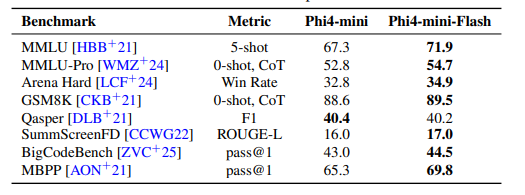
在后续的测试中,它持续击败了作为基础模型的Phi-4-mini。尤其在知识密集型和编程任务上,性能提升了数个百分点。
该模型在数学和科学推理方面的表现也更为优异。值得注意的是,它是在没有采用资源密集型强化学习步骤的情况下,取得了这些成就。
此前的模型版本通常需要依赖强化学习进行微调。在部分基准测试中,Phi-4-mini-flash-reasoning的表现甚至超越了规模是其两倍的大型模型。
这证明了其架构的卓越效率,能够以更小的规模实现更强的能力。
微软已经将Phi-4-mini-flash-reasoning模型在Hugging Face平台上提供。同时,微软在Phi Cookbook中发布了相关的代码示例。完整的训练代码库也已在GitHub上开源。
抱抱脸:https://huggingface.co/microsoft/phi-4-mini-flash-reasoning
Phi Cookbook:https://github.com/microsoft/PhiCookBook
Github:https://github.com/microsoft/ArchScale


