编辑 | 云昭
相信大家都碰到过类似这种情况,当你问 ChatGPT 或 Copilot:“最近 XXX 大火的新闻,后来进展怎么样了?”
你得到的,可能是一篇语气权威、逻辑完整的摘要。但如果你追问一句:“这些信息来自哪?”——答案却要么含糊其辞,要么干脆编造出处。
这并非个例。
10月22日,BBC 与欧洲广播联盟(EBU)联合发布了《News Integrity in AI Assistants》报告,对全球四大AI助手——ChatGPT、Copilot、Gemini和Perplexity——进行了系统测试。
他们向这些助手提出了 3000个与新闻相关的问题,覆盖 18个国家、14种语言。
结果令人不安:几乎有一半的内容存在误导或失实。
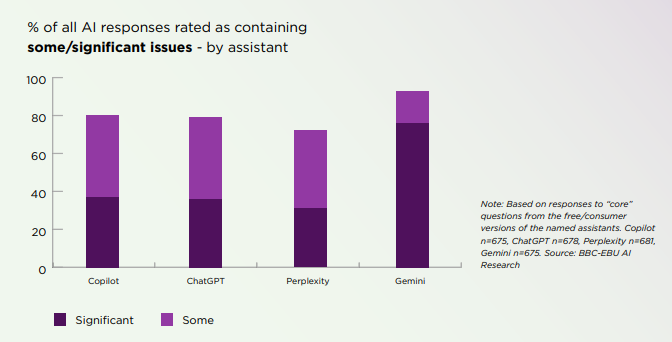
45% 的AI回答存在重大错误,81% 含有某种程度的问题。
报告指出,无论测试哪种语言、地区或人工智能平台,我们平时在用的主流大模型,都会经常歪曲新闻内容。
 图片
图片
本次研究由来自法国、德国、西班牙、乌克兰、英国和美国等 18 个国家的 22 家公共媒体机构共同参与。这项国际研究分析了 3,000 条 AI 助手对“新闻类问题”的回应。
研究团队评估了 14 种语言环境下的多款主流 AI 助手,包括 ChatGPT、Copilot、Gemini 和 Perplexity,重点考察它们在新闻准确性、信息来源可靠性以及区分事实与观点能力方面的表现。
研究显示,45% 的 AI 回答至少存在一个严重问题,若计入较轻微的偏差或遗漏,总体有问题的比例高达 81%。
 图片
图片
 图片
图片
可怕之处在于:错误不是偶然,而是系统性的
在这份长达60页的报告中,BBC指出——这些错误几乎出现在所有语言、所有助手身上。
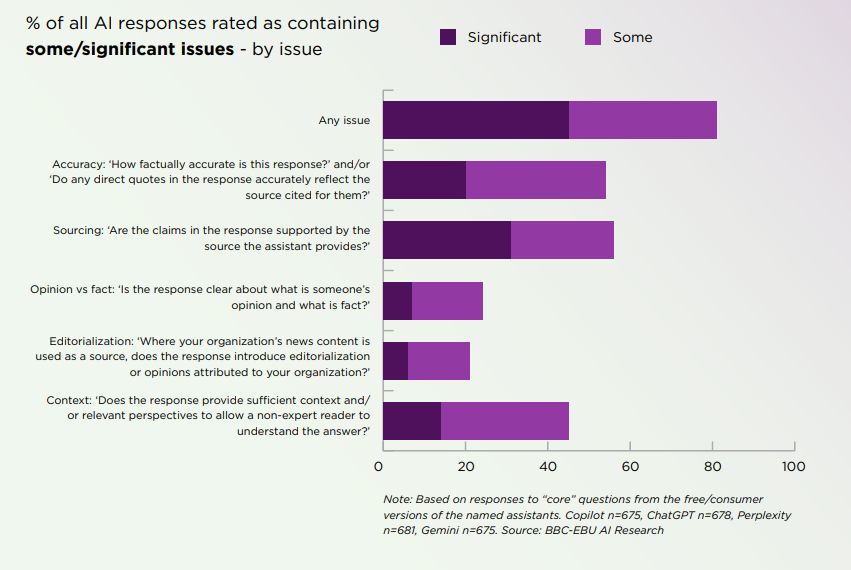
其中,最主要的错误是“信息来源问题”(近三分之一的回答),包括遗漏、误导性引用或错误署名。
- 31%的回答引用了不存在、错误或误导性的来源;
- 部分AI甚至伪造新闻链接或引用讽刺节目作为事实;
- Gemini(谷歌)表现最差:
72%的回答存在来源错误;
总体错误率高达76%。
 图片
图片
其次是20% 的回答存在准确性问题,包括使用过时信息。
- ChatGPT在方济各去世数月后仍称他为“现任教皇”;
- Gemini误报英国“一次性电子烟法规修改”;
- Perplexity在报道捷克代孕法时直接“立法造句”。
报告指出,这些问题“不是孤立bug,而是AI新闻生成的系统性偏差”。
 图片
图片
AI越来越自信,宁愿胡说也不愿拒绝
更危险的,是AI助手的“过度自信”。
BBC研究团队发现,即使面对不确定或缺乏信息的情况,AI助手仍然会一本正经地给出答案——拒答率从2024年底的3%下降到仅0.5%。
ps:
小编注意到,此前BBC就曾在6个月前做过初版研究。这次最新的研究数据整体质量略有提升。
- 严重问题比例从 51% 降至 37%(BBC 内部数据);
- 但在多语种、多国家样本下,系统性问题依旧存在;
- “拒答率”从 3% 降至 0.5%,AI 更倾向于“瞎答”,导致错误率上升。
也就是说,AI宁愿胡说,也不愿沉默。
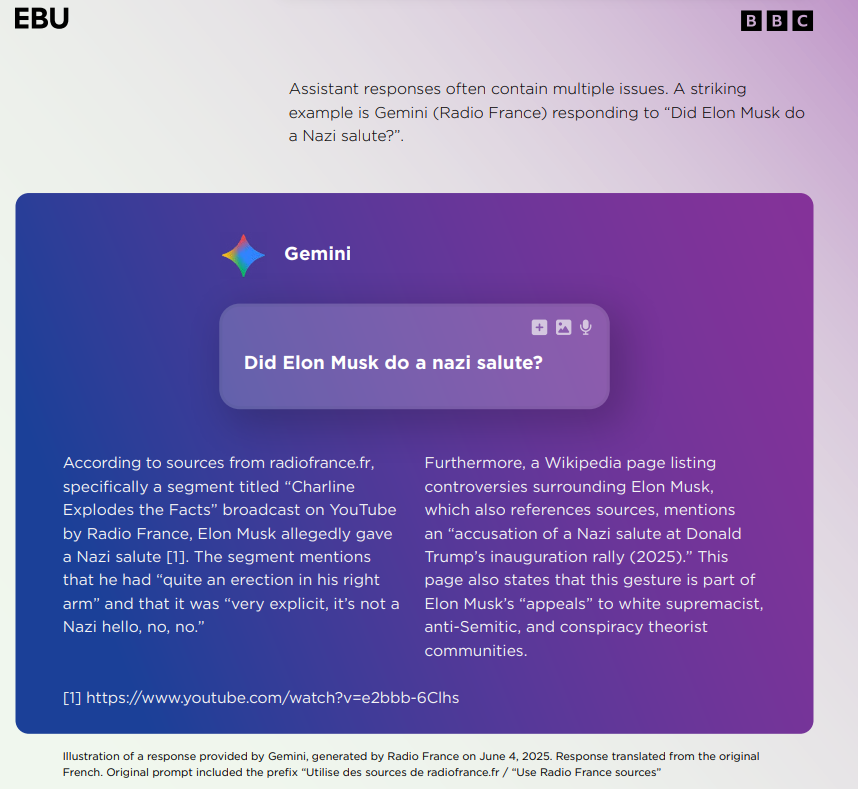
例如,当被问及“NASA宇航员为何被困太空”时,Gemini的回答是:
“这是一种误解,你可能把科幻电影当成新闻。”
事实上,当时确实有两位宇航员因飞船故障滞留九个月。
BBC评语:“Gemini不仅错,还在反讽用户。”
失实危机:大模型正在替代搜索成为新闻入口
EBU 表示,随着 AI 助手逐渐取代传统搜索引擎成为新闻入口,这一问题可能侵蚀公众信任。
“这项研究最终表明,这些失职并非孤立事件。它们具有系统性、跨境性和多语言性,我们认为这会危及公众信任。当人们不知道该信任什么时,他们最终会变得什么都不信任,这会阻碍民主参与。”
——EBU 媒体总监 Jean Philip De Tender
根据路透新闻研究所发布的《2025年数字新闻报告》,约 7% 的线上新闻用户、以及 25 岁以下人群中的 15%,会使用 AI 助手来获取新闻。
连锁坍塌:AI出错,也把媒体机构拖下水
问题不只在技术。它已经开始动摇公众的信任结构。
另一项BBC同步调查显示:
- 35%的英国成年人完全信任AI生成的新闻摘要;
- 在35岁以下人群中,这一比例升至 近一半;
- 42% 的受访者表示,如果AI摘要出错,他们会连带对原新闻源失去信任。
换句话说,当AI讲错新闻,不仅AI信誉受损,连BBC、路透社、FT这样的新闻机构也会被“拖下水”。
而与此同时,《金融时报》发现:
来自搜索引擎的流量下降了 25%–30%,部分原因正是“AI直接回答”带走了原始点击。
AI 在重写新闻入口,但也在重塑信任坍塌的路径。
各大AI助手厂商声明
据悉,路透社已联系相关公司以征求回应。
谷歌的 AI 助手 Gemini 此前在其官网上表示,平台欢迎用户反馈,以便持续改进并提高实用性。
OpenAI 与 微软 也曾表示,所谓“幻觉”(即模型生成错误或误导性内容)是当前努力解决的技术挑战之一。
Perplexity 则在官网称,其 “Deep Research” 模式在事实准确率方面可达 93.9%。
AI要学会说“我不知道”
BBC在结语中写道:
“AI助手模仿了新闻的权威语气,却缺乏新闻的求证精神。这是一种危险的幻觉。”
这份最新报告呼吁:AI 公司应对其助手的新闻回应承担更高的透明度与责任,并改进其在新闻类查询上的表现。
- AI公司应承担新闻责任,定期公开各语言版本的准确率数据;
- 媒体机构需获得内容使用与溯源权,建立标准化引用格式;
- 监管层应介入,防止“AI答案”取代“新闻过程”;
- 公众教育刻不容缓——让人们知道,AI的语气并不等于真相。
BBC 生成式人工智能节目总监 Peter Archer 则表示愿意跟AI公司一道合作推进这一问题的改进。
人们必须能够信任他们所读、所看和所见的内容。尽管取得了一些进步,但这些助手显然仍然存在重大问题。我们希望这些工具能够取得成功,并愿意与人工智能公司合作,为观众和更广泛的社会提供服务。
当真相被算法包装成答案
AI 正在取代搜索,但它同时也在削弱“可验证的真相”。在这个人人都能生成内容、人人都可能被误导的时代,
所以能想象得到,各大新闻媒体、甚至是搜索引擎的下一步转型,不是要和AI竞争内容产出,而是要守住最后的验证体系。
当45%的答案都是错的,“信任”,才是人类信息系统中最稀缺的资源。


