本文作者包括来自杜克大学的汪勤思、林阅千、李海教授、陈怡然教授,新加坡国立大学的刘博,马里兰大学的周天翼教授,和 Adobe 的研究员施靖、万锟、赵文天。

- 开源代码&模型:https://github.com/wangqinsi1/Vision-Zero
- 项目主页:https://huggingface.co/papers/2509.25541
- 论文链接:https://arxiv.org/abs/2509.25541

背景介绍
尽管目前VLM在多模态任务上表现突出,但训练过度依赖人工标注的数据与精心设计的强化学习奖励。这种依赖带来数据稀缺问题:多模态标注成本高昂,限制了训练数据的规模与多样性。同时存在知识天花板:模型能力受人类监督边界限制,难以突破人类已有知识和策略。曾经AlphaGo所使用的自博弈技术通过模型与自身副本竞争交互并自动获取反馈,把计算转变为数据的同时消除了对人工监督的依赖,这使得它能够持续推动模型进步并突破人类能力上限。但是受制于VLM的多模态特性,目前鲜有对自博弈在VLM上应用的系统性研究。为此研究团队设计了一套适应VLM特性的自博弈框架Vision-Zero,此框架有如下特点:
(1)策略自博弈框架:Vision-Zero在以社交推理类游戏为模板的环境中训练VLM,使得agent在自博弈过程中自动生成高复杂度推理数据,而无需人工标注。
(2)任意形式的图片都可作为输入:和以往有限制条件的游戏化训练框架不同的是,Vision-Zero可在任意形式的图片上启动游戏,这使得模型可以在很多不同的领域里获得相应的能力提升,并有很好的泛化性能。
(3)持续的性能提升:研究团队提出了自博弈和可验证奖励的强化学习(RLVR)交替优化的自博弈策略优化算法(Iterative-SPO),这一算法解决了传统自博弈算法中常见的性能瓶颈问题。
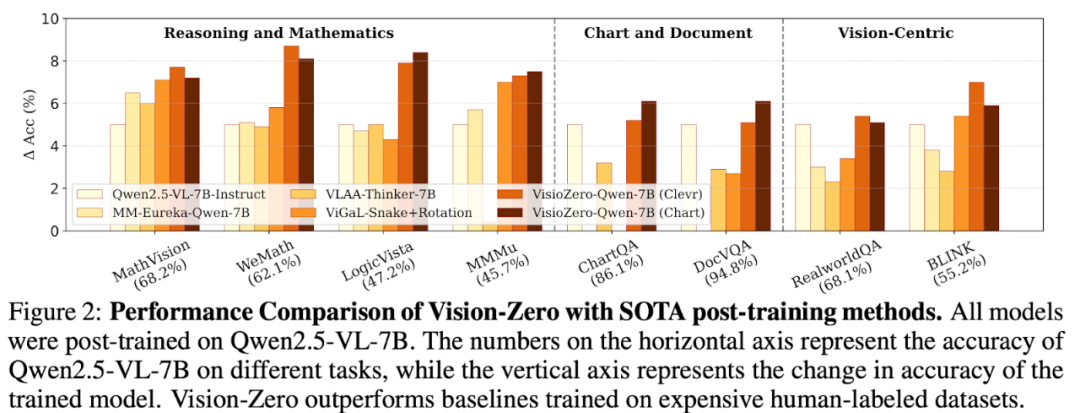
尽管没有用任何标注数据做训练,Vision-Zero在多个领域如推理,图表问答和Vision-Centric理解任务上超越了其他有标注的SOTA后训练方法。
从棋盘到现实:
AlphaGo 自博弈思想的泛化
自博弈作为 OpenAI 早期的重要技术路线之一,也是人工智能发展历程中多项里程碑事件的关键推动力。典型代表包括 2016 年 AlphaGo 战胜李世石,以及 2019 年 OpenAI Five 在 Dota 2 上击败世界冠军 OG 战队。人们在看到自博弈在某些特定领域大幅超越人类智能的同时,往往也会思考我们是否有可能把这种思想应用到更多的开放场景中。然而让AlphaGo从棋盘走入现实需要解决以下几个难题:
(1)Agent为赢得博弈所习得的技能,应当与目标任务所需的技能高度一致。
(2)博弈环境应当足够多样且复杂,以便广泛的目标任务都能够满足条件 (1)。
(3)技能增长应当具有可扩展性:随着自博弈的进行,环境应当不断提高难度,使得越来越强的智能体能够涌现,而不是让训练收敛到一个固定的上限。
受到社交推理游戏,如“谁是卧底”的启发,研究团队设计了一套完备的自博弈规则以解决上述难题,具体规则如下:
(1)游戏中有 n 名平民和 1 名卧底。玩家首先被告知自己的角色。
(2)每名玩家会得到一张图片,卧底的图片与平民略有不同(如缺失、添加或修改了某个物体)。
(3)线索阶段:每位玩家观察自己的图片,并给出一个口头线索,描述图片内容(可以是物体描述、推断信息等)。
(4)决策阶段:多轮线索给出后,进入决策阶段。玩家根据线索结合自己的图片,投票找出卧底。

此游戏具有高度策略性与挑战性,卧底需要根据他人线索推断并伪装自己,避免暴露。平民需要提供足够准确但不泄密的线索,同时分析他人线索寻找可疑点。如此一来,Agent在游戏过程中便可生成足够长且复杂的推理链条,并且随着对手能力的提升,其所面临的挑战也会越来越大,并被激发出更强的视觉理解与推理能力。
领域无关的数据输入
此游戏仅需要两张有细微差异的图片对作为输入即可启动,得益于目前强大的图片编辑工具如ChatGPT或nano banana,数据的构建极其简单并且成本低廉,因此此框架的应用场景非常广泛。研究团队使用了三种完全不同的场景图片输入作为训练数据:
(1)CLEVR 合成场景:使用 CLEVR 渲染器自动生成了 2000 对图像。原图有 4–6 个随机排列的物体,修改图中有两个物体在颜色和形状上被改变。
(2)图表数据:从 ChartQA 训练集随机选取了 1000 张图表作为原始图像,并使用 Gemini2.5-Flash 随机交换图表中的数值属性生成对应的修改图像。
(3)真实世界图片:从 ImgEdit 训练集中随机抽取了 1000 对图像,该数据集包含高质量的真实世界单轮图像编辑对。
从局部均衡到可持续提升
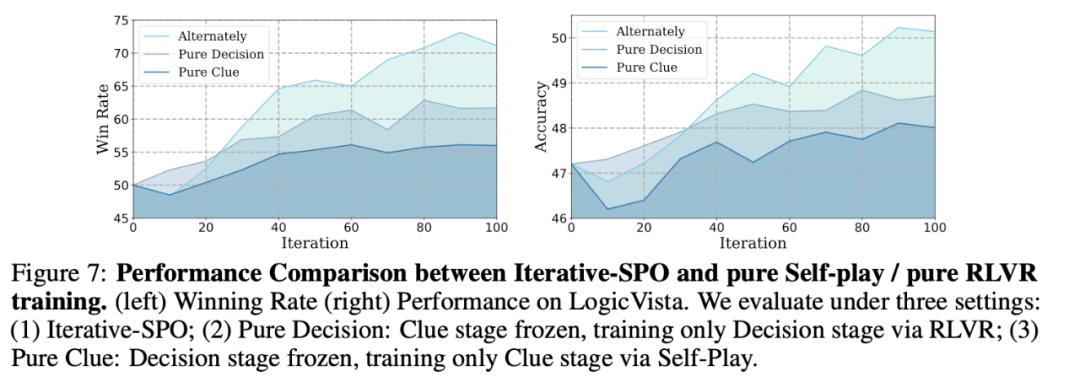
纯自博弈训练容易陷入局部平衡,难以探索新的推理路径,而单独的强化学习方法在掌握现有问题集后也易出现知识饱和。为缓解这些问题,作者团队提出采用双阶段交替训练:当决策阶段表现显示线索阶段已饱和时转向线索训练提高难度,反之则切回决策阶段。此方法被命名为Iterative Self-Play Policy Optimization。实验表明,两阶段交替训练性能明显优于单阶段训练,对比如下。
实验结果
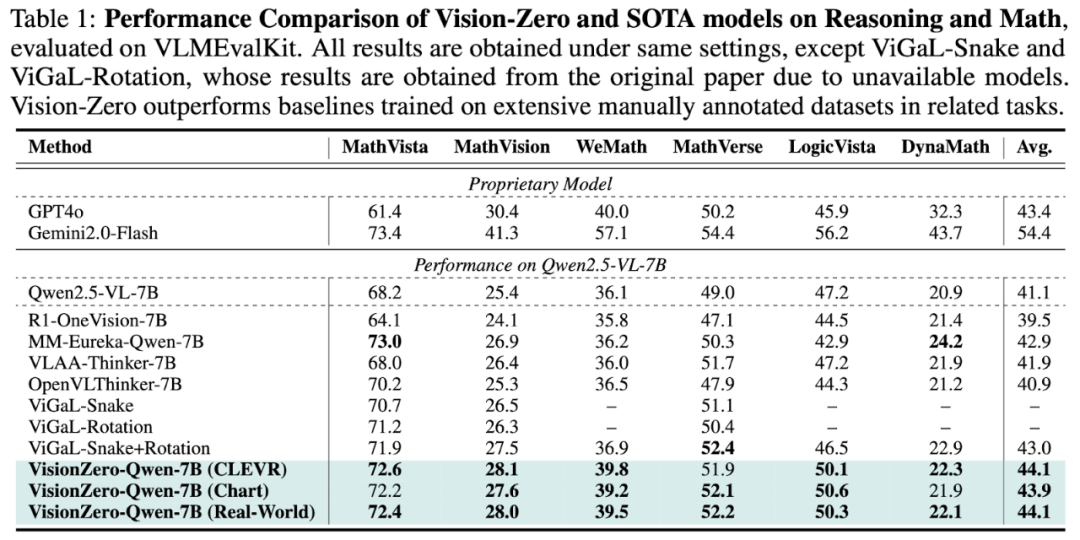
强任务泛化能力。为了评估 Vision-Zero 框架下训练的VLM是否能泛化到更广泛的推理与数学任务,作者团队在六个基准数据集上对模型进行测试(结果见表 1)。实验表明,即使没有使用标注数据做训练,Vision-Zero 在各项基准上一致性得优于其他需要标注的SOTA方法。其中,VisionZero-Qwen-7B(CLEVR、Real-World)较基线提升约 3%,VisionZero-Qwen-7B(Chart)提升约 2.8%,而目前最优的基线方法仅约 1.9%。值得注意的是,基线方法需要大量数学与推理样本训练,而Vision-Zero 环境并未显式包含数学任务,只通过自然语言策略博弈提升逻辑推理,并将所学能力有效迁移到更广泛的数学与推理任务,甚至超过专门在大规模任务数据上训练的模型。
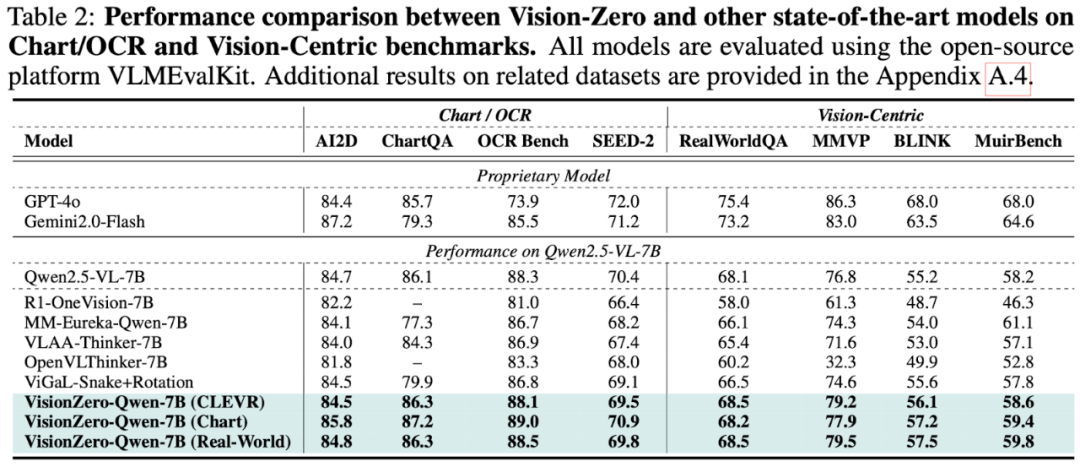
跨能力负迁移的缓解。VLM 后训练的关键难题之一是跨能力负迁移,即在特定任务上训练后,模型在其他任务上反而变差。表 2 显示,基线模型在推理和数学数据上后训练后,性能明显下降,例如MM-Eureka-Qwen-7B 在ChartQA 上下降约10%。相比之下,Vision-Zero训练的模型能有效缓解负迁移:VisionZero-Qwen-7B(CLEVR)在视觉任务上显著提升,同时在四个图表/OCR 任务上平均仅下降 0.2%;VisionZero-Qwen-7B(Chart)在全部图表/OCR 基准上都有提升,并在视觉任务上平均再涨 1%。这表明 Vision-Zero 的多能力策略训练显著减轻了传统单一任务训练中的负迁移问题。
启示
Vision-Zero 证明了自博弈从单一任务走向通用任务的可行性与巨大潜力。通过构建开放、可扩展的博弈环境,它摆脱人工标注依赖,突破数据和知识瓶颈,使模型在无需特定任务训练的前提下实现可持续的能力进化与跨领域泛化。同时,双阶段交替优化有效避免自博弈常见的局部均衡问题。并且,通过自博弈训练的VLM有效缓解了传统的在单一任务上做训练的跨能力负迁移问题。


