长期以来,多模态代码生成(Multimodal Code Generation)的训练严重依赖于特定任务的监督微调(SFT)。尽管这种范式在 Chart-to-code 等单一任务上取得了显著成功 ,但其 “狭隘的训练范围” 从根本上限制了模型的泛化能力,阻碍了通用视觉代码智能(Generalized VIsioN Code Intelligence)的发展 。同时,「SFT-only」的范式在确保代码可执行性和高视觉保真度方面存在显著瓶颈 。
在此背景下,中科院 & 美团研究团队推出了 VinciCoder ,一个旨在打破 SFT 瓶颈的统一多模态代码生成模型。VinciCoder 首次将强化学习的奖励机制从文本域转向视觉域,提出视觉强化学习(ViRL) ,专攻 SFT 无法解决的视觉保真度难题。
本文提出的系统性框架 VinciCoder,通过 “大规模 SFT + 粗细粒度 ViRL” 的两阶段策略,有效统一了从图表、网页、SVG 到科学绘图(LaTeX、化学分子)等多样化代码生成任务 。

论文标题:VinciCoder: Unifying Multimodal Code Generation via Coarse-to-fine Visual Reinforcement Learning
论文链接:https://arxiv.org/abs/2511.00391
Github 链接:https://github.com/DocTron-hub/VinciCoder
数据代码模型权重已开源。
核心创新与技术突破
该论文同样对传统 SFT 范式的局限性进行了深入分析,发现其关键问题在于训练目标与最终任务之间存在 “视觉鸿沟”:
目标是局部的:SFT 采用自回归的 “下一词元预测” 目标 ,这本质上是局部的,无法为代码 “可执行性” 等全局属性提供监督信号 。
缺乏视觉反馈:模型在训练时完全看不到代码的渲染结果 。这是一个致命缺陷,因为在代码中 “微小的修改就可能导致渲染图像发生巨大变化” 。
这种 “视觉 - 代码” 监督的缺失,直接导致了两个关键问题:
保真度低且不可靠:模型仅在词元层面(token-level)进行优化 ,无法保证渲染出的图像在视觉上与输入对齐,也无法保证代码可以成功执行 。
泛化能力差:依赖特定任务的数据集进行 SFT,难以形成一个统一的多模态代码生成框架 。
考虑到 SFT 的根本局限性,研究者认为必须引入一个能够提供全局视觉反馈的机制。然而,传统的 RL 方法依赖难以泛化的 “基于规则的文本奖励” 。VinciCoder 的破局点在于 —— 将奖励机制从文本域彻底转向视觉域 。
VinciCoder 的核心思路是:用大规模、多样化的 SFT 构建强大的代码基础能力 ,再通过创新的 ViRL 策略专门优化 SFT 无法触及的视觉保真度和可执行性 。训练框架由「1.6M 大规模 SFT 阶段」和「42k 粗细粒度 ViRL 阶段」两部分组成 ,核心是通过两阶段协作,同时实现强大的代码理解与高保真的视觉对齐。
1. 大规模 SFT 语料库与代码优化任务
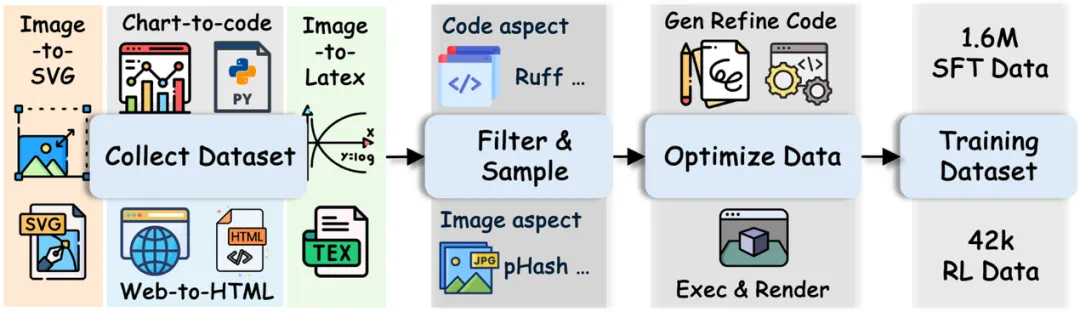
研究团队首先构建了一个包含 1.6M 图像 - 代码对的大规模监督微调(SFT)语料库 。该语料库不仅覆盖了直接代码生成任务,还引入 “视觉代码优化” 的新任务 。在这项任务中,模型会接收到一个目标图像和一个 “有缺陷” 的代码片段(包含逻辑错误或只能部分渲染)。模型的目标是修正这段代码,使其视觉输出与目标图像精确对齐 。这一设计极大地提升了模型在代码层面的纠错和优化能力,为后续的强化学习阶段奠定了坚实基础 。
2. 从 “文本奖励” 到 “视觉奖励”:粗细粒度 ViRL 框架
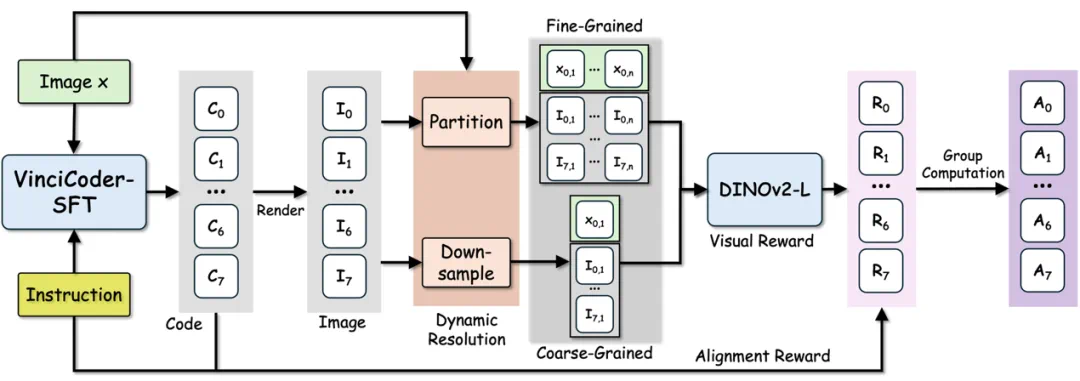
传统 SFT 训练在多模态代码生成上存在根本缺陷:它缺乏 “视觉 - 代码” 的闭环反馈 ,且无法保证代码的全局可执行性 。
为解决此问题,VinciCoder 引入了视觉强化学习 (ViRL) 框架 。该框架摒弃了传统强化学习中脆弱的、基于规则的 “文本奖励” ,转而从视觉直接获取奖励信号 。
其核心突破在于一套粗 - 细粒度(Coarse-to-fine)视觉奖励机制:
渲染与编码:模型生成的代码被实时渲染成图像 。
粗粒度(全局):通过下采样生成缩略图,评估整体结构的相似性 。
细粒度(局部):将高分辨率图像分割为多个局部图块(patches),精确计算局部细节的保真度 。
ViT 奖励模型:使用 DINOv2-L 计算渲染图像与目标图像在两个粒度上的视觉相似度,作为奖励信号。
对齐奖励 :引入一个辅助的语言对齐奖励,用于惩罚生成了错误代码语言(如要求 Python 却生成了 LaTeX 的行为)
策略优化:采用群组相对策略优化 (GRPO) 算法 对模型进行微调,显著提升视觉对齐度和代码可执行性。
据我们所知,VinciCoder 是第一个应用强化学习(RL)来实现统一视觉代码生成领域中 “跨领域视觉保真度” 提升的视觉语言模型 。
实验结果与性能表现
论文在五大多模态代码生成基准上进行了全面实验,对比了包括 Qwen、InternVL 等开源模型以及 Gemini-2.5-Pro、Claude-4.5、GPT-5 等闭源模型 ,核心结果如下:
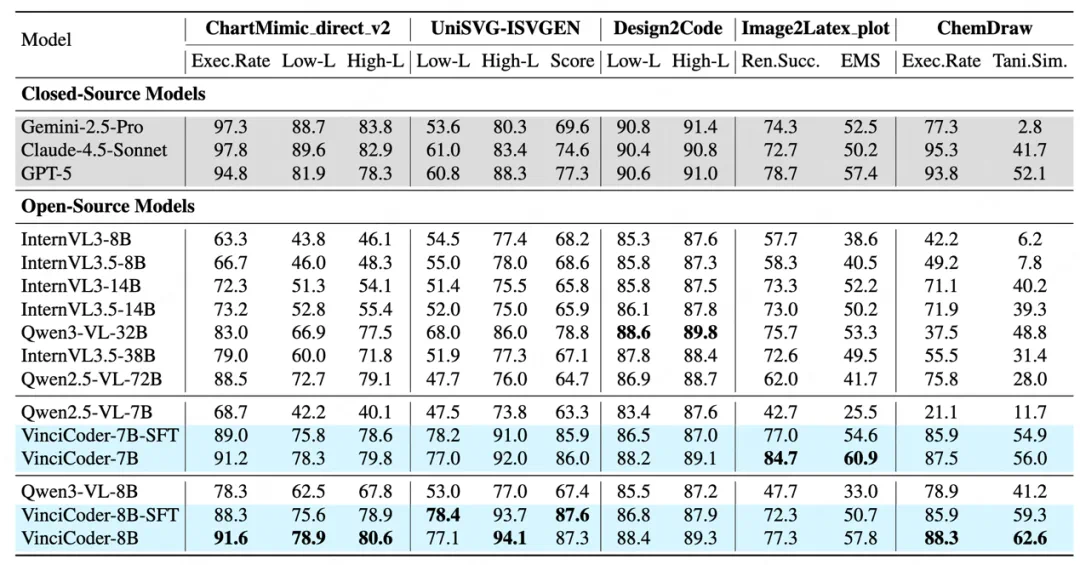
实验结果令人瞩目:VinciCoder 在多个主流多模态代码生成基准上均取得了卓越表现。
SOTA 性能:VinciCoder 在开源模型对比中树立了新的 SOTA 标准 ,其性能显著优于所有同等规模的竞争对手 。
媲美闭源模型:在如 Image-to-SVG 和化学分子式生等高难度任务上,VinciCoder 展现出超越顶尖闭源模型的卓越性能 。
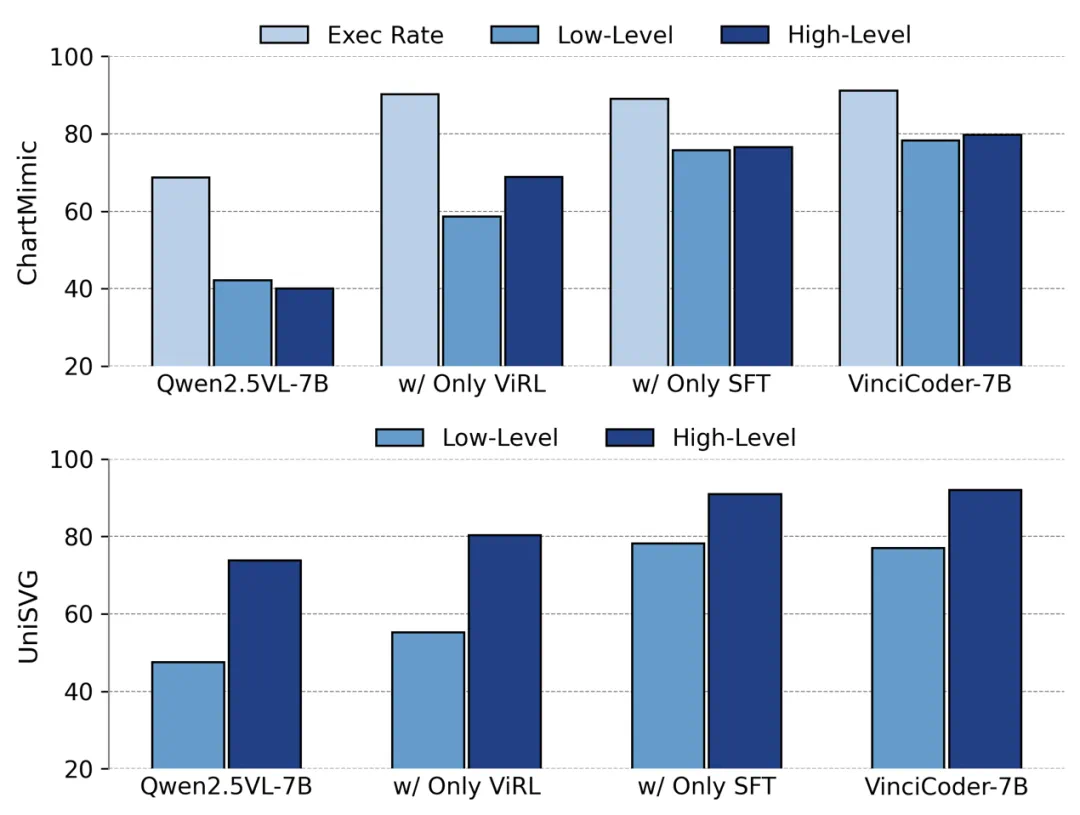
策略有效性:消融实验证明,仅 SFT 阶段的 VinciCoder-SFT 就已建立起强大的基线 ;而 ViRL 阶段的引入,则成功将模型性能提升至 SOTA 水平 ,充分验证了 SFT-ViRL 两阶段策略的压倒性优势。
研究意义与应用前景
VinciCoder 的研究不仅在技术上取得了重大突破,也为多模态代码生成领域提供了全新的研究范式:
验证 RL 新路径:证明了 “视觉强化学习” 是突破 SFT 瓶颈、提升代码视觉保真度的有效途径,将奖励机制从文本域成功扩展到视觉域 。
统一框架的实现:打破了过去模型 “各自为战” 的狭隘范式 ,提供了一个强大的统一框架,能够处理包括 Python、HTML、SVG、LaTeX 乃至化学 SMILES 在内的多样化代码生成任务 。
高保真度奖励机制:“粗 - 细粒度” 奖励设计为处理高分辨率、高复杂度视觉输入的 RL 任务提供了健壮且可扩展的解决方案 。
结论
VinciCoder 的核心价值并非单纯地堆砌 SFT 数据,而是通过 “SFT + 粗细粒度 ViRL” 的组合,证明了 “以视觉反馈指导代码生成” 的可行性与优越性。这一思路不仅解决了传统 SFT 范式在可执行性与视觉保真度上的痛点,也为后续通用多模态智能体的研发提供了新的思路。
在总体思路上,该论文的思路与 R1-Style 方法高度相关,都验证了强化学习在提升基础模型高级能力上的巨大潜力。VinciCoder 的成功探索表明,RL 不仅可以用于优化数学推理等文本任务,更可以作为连接 “视觉” 与 “代码” 两大模态的桥梁,解决 SFT 无法企及的跨模态对齐难题。
更多细节请参阅原论文。