In the modern fashion industry, Video Virtual Try-On (VVT) has gradually become an important component of user experience. This technology aims to simulate the natural interaction between clothing and human body movements in videos, showcasing realistic effects during dynamic changes. However, current VVT methods still face multiple challenges such as spatial-temporal consistency and preservation of clothing content.
To address these issues, researchers proposed MagicTryOn, a virtual try-on framework based on a large-scale video diffusion transformer (Diffusion Transformer). Unlike traditional U-Net architectures, MagicTryOn uses the Wan2.1 video model, adopting diffusion transformers with comprehensive self-attention mechanisms to jointly model spatial-temporal consistency in videos. This innovative design enables the model to more effectively capture complex structural relationships and dynamic consistency.
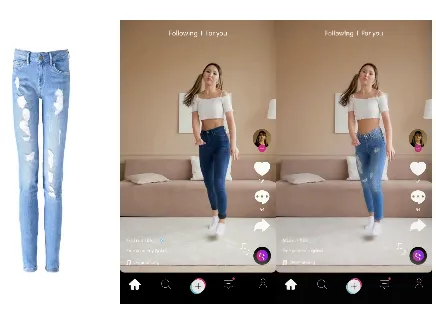
In the design of MagicTryOn, researchers introduced a coarse-to-fine clothing retention strategy. In the coarse stage, the model integrates clothing markers during the embedding phase, while in the refinement stage, it combines various clothing-related conditional information such as semantics, textures, and outlines, thereby enhancing the expression of clothing details during denoising. Additionally, the research team proposed a mask-based loss function to further optimize the realism of the clothing region.
To verify the effectiveness of MagicTryOn, researchers conducted extensive experiments on multiple image and video try-on datasets. The results show that this method outperforms the current state-of-the-art technologies in comprehensive evaluations and can be well generalized to practical scenarios.
In specific applications, MagicTryOn performs particularly well in scenarios involving significant motion, such as dance videos. These scenes not only require clothing consistency but also temporal and spatial coherence. By selecting two dance videos from the Pexels website, researchers successfully evaluated MagicTryOn's performance in situations involving significant motion.
MagicTryOn represents new progress in virtual try-on technology, combining advanced deep learning techniques and innovative model designs, demonstrating its great potential in the fashion industry.
Project: https://vivocameraresearch.github.io/magictryon/
Key points:
🌟 MagicTryOn adopts diffusion transformers, improving the spatial-temporal consistency of video virtual try-ons.
👗 Introduces a coarse-to-fine clothing retention strategy, enhancing the representation of clothing details.
🎥 Performs excellently in scenarios involving significant motion, successfully showcasing the natural interaction between clothing and body movements.