
如何让针对静态场景训练的 3D 基础模型(3D Foundation Models)在不增加训练成本的前提下,具备处理动态 4D 场景的能力?
来自香港科技大学(广州)与地平线 (Horizon Robotics) 的研究团队提出了 VGGT4D。该工作通过深入分析 Visual Geometry Transformer (VGGT) 的内部机制,发现并利用了隐藏在注意力层中的运动线索。
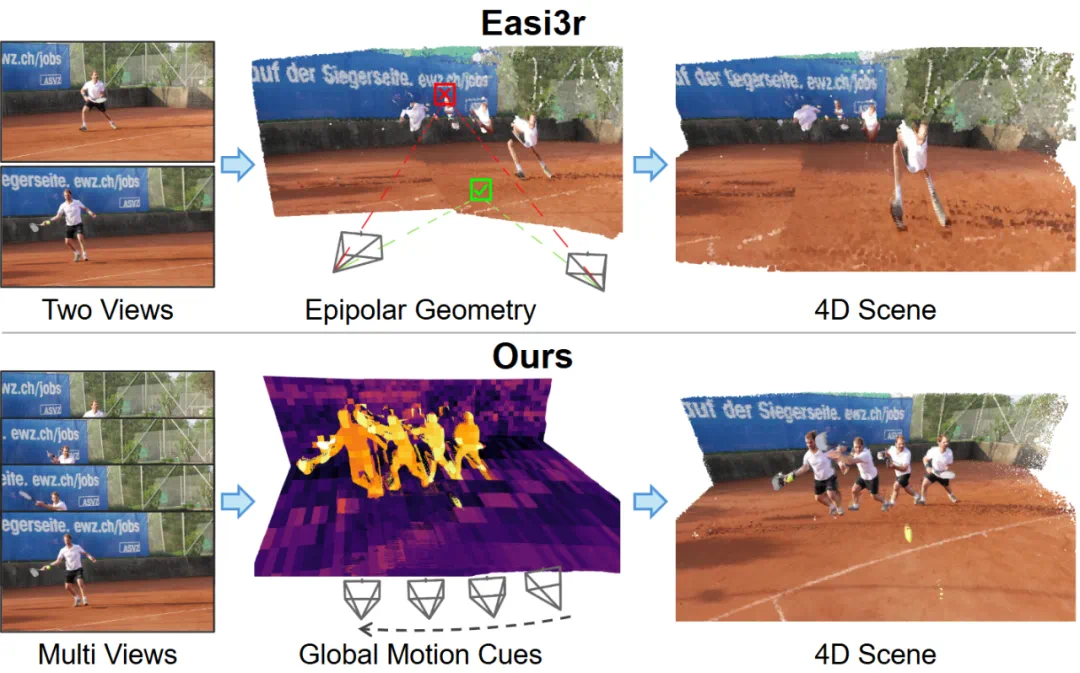

作为一种无需训练 (Training-free) 的框架,VGGT4D 在动态物体分割、相机位姿估计及长序列 4D 重建等任务上均取得了优异性能。

论文标题: VGGT4D: Mining Motion Cues in Visual Geometry Transformers for 4D Scene Reconstruction
论文链接:https://arxiv.org/abs/2511.19971
项目主页: https://3dagentworld.github.io/vggt4d/
代码链接:https://github.com/3DAgentWorld/VGGT4D
研究背景
近年来,以 VGGT、DUSt3R 为代表的 3D 基础模型在静态场景重建中表现出色。然而,面对包含移动物体(如行人、车辆)的动态 4D 场景时,这些模型的性能往往显著下降。动态物体的运动不仅干扰背景几何建模,还会导致严重的相机位姿漂移。
现有的解决方案通常面临两类挑战:
计算或训练成本高:依赖繁重的测试时优化 (Test-time Optimization) 或需要在大规模 4D 数据集上进行微调。
依赖外部先验:通常需要引入光流、深度估计或语义分割等额外模块,增加了系统的复杂性。
VGGT4D 的核心设想:能否在不进行额外训练的前提下,直接从预训练的 3D 基础模型中挖掘出 4D 感知能力?
核心洞察:VGGT 内部的潜在运动线索
研究人员对 VGGT 的注意力机制进行了可视化分析,观察到一个关键现象:VGGT 的不同网络层对动态区域表现出截然不同的响应模式。
浅层网络:倾向于捕捉语义上显著的动态物体。
深层网络:则逐渐抑制几何不一致的区域。
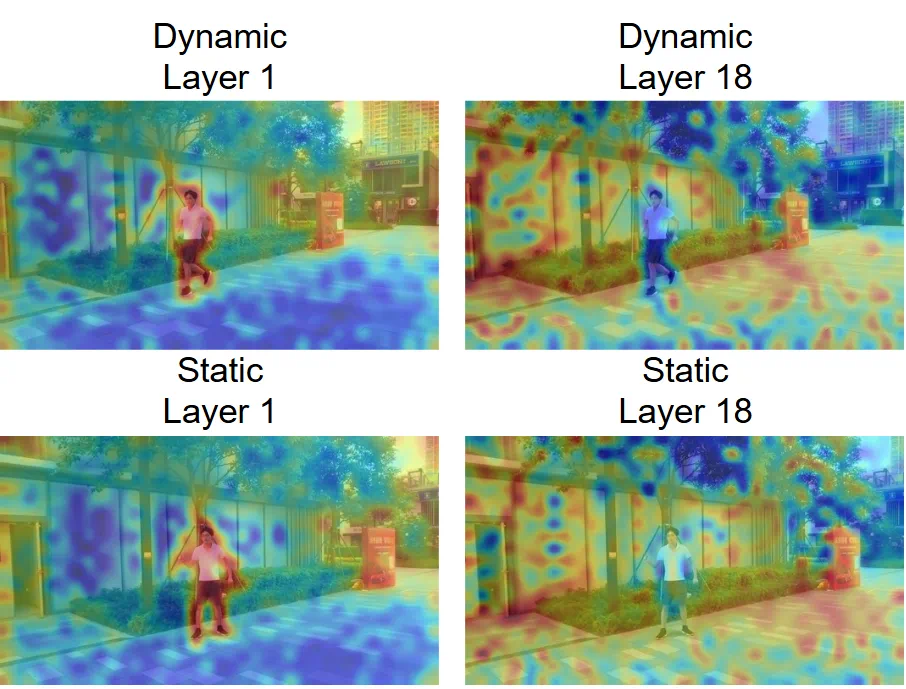
这一发现表明,VGGT 虽然是基于静态假设训练的,但其内部实际上已经 隐式编码 了丰富的动态线索。
然而,直接利用标准的注意力图 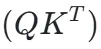 效果并不理想,因为它混合了纹理、语义和运动信息,导致信噪比低,使得 Easi3R 等基于 Epipolar 假设的方法在 VGGT 架构上失效。
效果并不理想,因为它混合了纹理、语义和运动信息,导致信噪比低,使得 Easi3R 等基于 Epipolar 假设的方法在 VGGT 架构上失效。
方法论:潜在运动线索的挖掘与解耦
VGGT4D 的核心贡献在于提出了一套无需训练的注意力特征挖掘与掩膜精修机制。该方法深入特征流形内部,利用 Gram 矩阵和梯度流实现了高精度的动静分离。
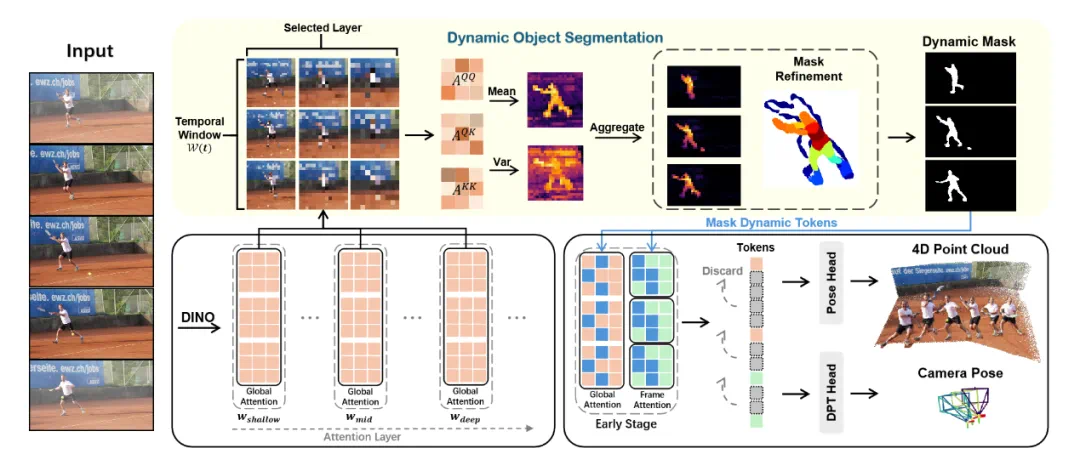
跨越投影间隙:基于 Gram 相似度的特征挖掘
研究团队首先分析了标准注意力图 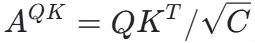 的局限性。由于 Q(Query)和 K(Key)向量来自异构的投影头,其特征分布存在天然的分布间隙(Distributional Gap),导致 Cross-Attention 主要响应语义对齐,而运动引起的微小特征扰动容易被掩盖。
的局限性。由于 Q(Query)和 K(Key)向量来自异构的投影头,其特征分布存在天然的分布间隙(Distributional Gap),导致 Cross-Attention 主要响应语义对齐,而运动引起的微小特征扰动容易被掩盖。
为解决此问题,VGGT4D 引入了自相似性 Gram 矩阵来替代。通过在同构潜在分布内计算相似度,运动引起的方差成为了主导信号。模型通过在时间窗口 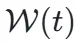 内聚合不同层级的统计矩(均值 S 与方差 V),构建了动态显著性场:
内聚合不同层级的统计矩(均值 S 与方差 V),构建了动态显著性场:
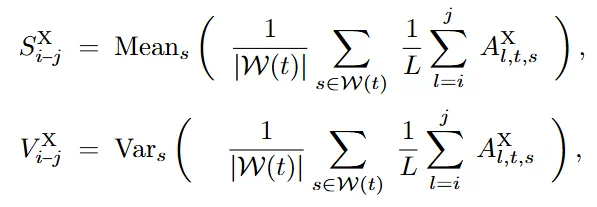
基于投影雅可比矩阵的梯度流精修
为了解决 Attention Map 分辨率不足导致的边界模糊问题,VGGT4D 引入了 投影梯度感知精修 (Projection Gradient-aware Refinement)。
定义 3D 点在视点 i 下的几何投影残差 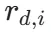 ,该残差关于 3D 坐标的梯度
,该残差关于 3D 坐标的梯度 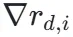 包含了极强的边界信息。由于该梯度依赖于投影雅可比矩阵(Projection Jacobians)和深度图的空间梯度,在动态物体边缘处会呈现显著的高频响应。聚合后的梯度能量函数如下所示,结合光度残差项,实现了对动态掩膜的亚像素级锐化:
包含了极强的边界信息。由于该梯度依赖于投影雅可比矩阵(Projection Jacobians)和深度图的空间梯度,在动态物体边缘处会呈现显著的高频响应。聚合后的梯度能量函数如下所示,结合光度残差项,实现了对动态掩膜的亚像素级锐化:
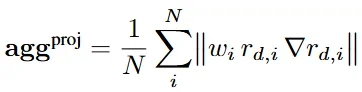
分布内早期掩膜策略(In-Distribution Early-Stage Masking)
在推理阶段,直接的全层掩膜(Full Masking)会将模型推向分布外(OOD)状态,导致性能下降。
VGGT4D 提出了一种早期阶段干预策略:仅在浅层抑制动态 Token 的 Key 向量。这种设计既在早期切断了动态信息对深层几何推理的影响,又保证了深层 Transformer Block 依然在其预训练的特征流形上运行,从而保证了位姿估计的鲁棒性。
实验验证
研究团队针对动态物体分割、相机位姿估计和 4D 点云重建三大核心任务,在六个基准数据集上进行了详尽的定量和定性评估。
核心组件评估:动态物体分割性能
实验首先评估了该方法的核心组件:动态物体分割。
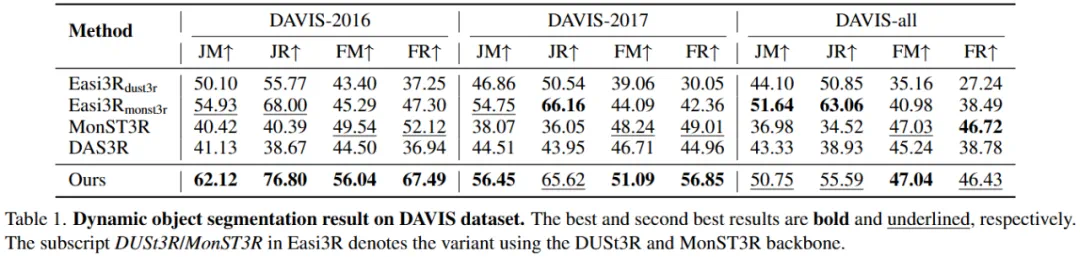
定量分析:VGGT4D 显著优于其他所有变体,在 DAVIS-2016 和 DAVIS-2017 数据集上均达到了最优性能。值得强调的是,即使没有经过任何 4D 特定的训练,该方法仅基于预训练的 VGGT 模型即可取得优异结果。虽然  在 DAVIS-all 数据集上表现出具有竞争力的召回率,但这主要得益于 MonST3R 在光流上的后训练,而 VGGT4D 无需训练。
在 DAVIS-all 数据集上表现出具有竞争力的召回率,但这主要得益于 MonST3R 在光流上的后训练,而 VGGT4D 无需训练。
定性分析:定性结果清晰地展示了基线方法的不足:Easi3R 的掩码较为粗糙且遗漏细节;DAS3R 倾向于过度分割并渗入静态背景;MonST3R 则常常分割不足。相比之下,VGGT4D 生成的掩码更加准确,且边界更加清晰。这些结果有力地验证了研究团队的假设:VGGT 的 Gram 相似度统计信息中嵌入了丰富的、可提取的运动线索。

鲁棒性验证:相机位姿估计
强大的基线与持续改进:数据表明,原始 VGGT 已经是一个非常强大的基线,其自身就优于 MonST3R、DAS3R 等许多专门的 4D 重建方法。这表明 VGGT 的预训练隐式地使其对动态物体具有一定的鲁棒性。然而,这种鲁棒性并不完美。 VGGT4D 在所有数据集上均持续改进了这一强大的 VGGT 基线。例如在 VKITTI 数据集上,VGGT4D 的 ATE 仅为 0.164,而 MonST3R 高达 2.272。
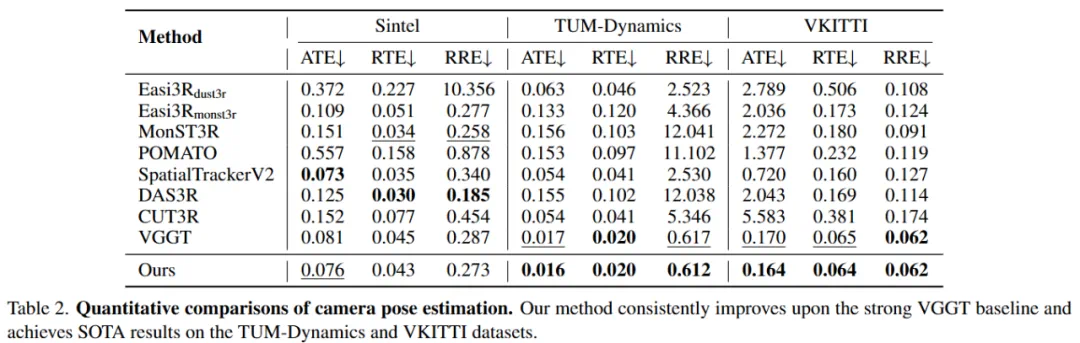
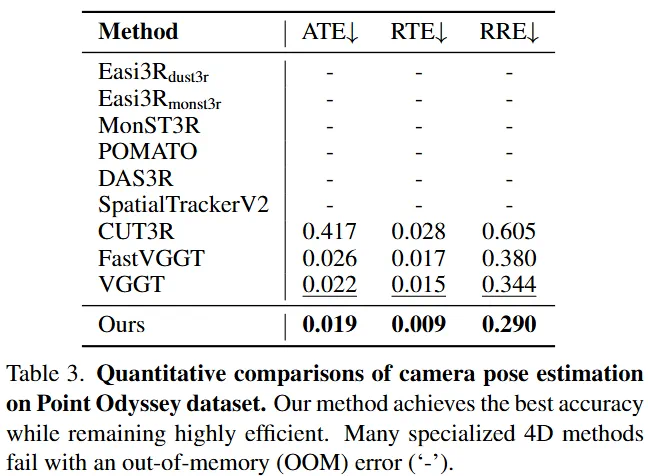
长序列鲁棒性突破:在极具挑战性的长序列 Point Odyssey 基准测试中,VGGT4D 在所有指标上均取得了最佳结果,同时保持了高度效率。许多其他 4D 方法由于内存不足(OOM)错误甚至无法在该 500 帧序列上运行。这表明 VGGT4D 提出的显式、无需训练的动态 - 静态分离方法成功地识别并消除了由运动引起的残余位姿不一致性,从而实现了更稳定、更准确的相机轨迹,尤其是在长且复杂的序列上。
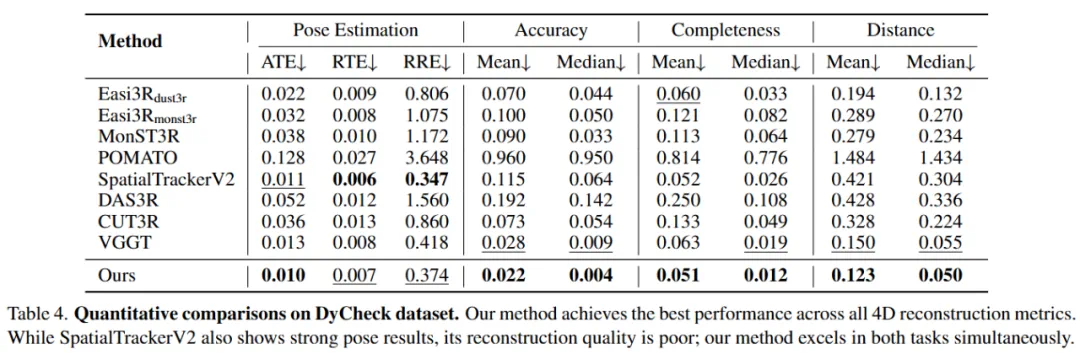
最终目标:4D 点云重建质量实验
在 DyCheck 数据集上的评估显示,VGGT4D 在所有重建指标(准确度、完整度和距离)上均取得了最佳性能。与 VGGT 基线相比,中位准确度误差从 0.009 降低到 0.004,平均距离从 0.150 降低到 0.123。这证明了该方法不仅实现了精准的动静分离,更能实质性提升几何重建质量。

结语
VGGT4D 提出了一种无需训练的新范式,成功将 3D 基础模型的能力扩展至 4D 动态场景。该工作证明了通过合理挖掘模型内部的 Gram 相似度统计特性,可以有效解耦动态与静态信息。这不仅为低成本的 4D 重建提供了新思路,也展示了基础模型在零样本迁移任务中的潜力。


