语言模型

Meta公布BLT新架构:告别token,拥抱patch
译者 | 核子可乐审校 | 重楼Meta发布的BLT架构为大模型扩展找到又一条出路,也开启了用patch方法取代token的全新可能性。 开篇先提问:我们为什么非得把文本拆分成token? 直接用原始字节怎么就不行?

本科学历但创造出GPT,奥特曼盛赞为「爱因斯坦级」天才,OpenAI总裁:他想要的,我们都给
奥特曼称他是爱因斯坦级别的天才;OpenAI总裁更是直言:只要他想要的,我们都给。 Alec Radford大神离职OpenAI,现在牵出更多细节:改变世界的GPT,竟然是在Jupyter notebook上诞生的。 而他只负责提供背后的灵感,剩下的由工程师来解决。

使用LLaMA 3.1、Firebase和Node.js,构建一个音控的智能厨房应用程序
译者 | 布加迪审校 | 重楼这篇指南逐步介绍了创建一个自动化的厨房助理的过程,附有语音命令、实时购物清单管理以及食谱建议。 我在本教程中将介绍创建一个智能厨房应用程序(Chent),它可以根据个性化偏好简化杂货清单管理。 该应用程序通过语音命令操作,简化了人机交互和添加商品。

全面超越CoT!Meta田渊栋团队新作:连续思维链
比思维链更厉害的方法是什么? 答:连续思维链。 近日,Meta田渊栋团队提出了针对LLM推理任务的新范式:Coconut( Chain of Continuous Thought)。
量化617,462种人类微蛋白必需性,北大LLM蛋白质综合预测与分析,登Nature子刊
编辑 | 萝卜皮人类必需蛋白(HEP)对于个体的生存和发育必不可少。 然而,鉴定 HEP 的实验方法通常成本高昂、耗时费力。 此外,现有的计算方法仅在细胞系水平上预测 HEP,但 HEP 在活体人类、细胞系和动物模型中有所不同。

压缩率达10的48次方,实现蛋白序列空间极端压缩,清华EvoAI登Nature子刊
编辑 | 萝卜皮设计功能更佳的蛋白质需要深入了解序列和功能之间的关系,这是一个难以探索的广阔空间。 通过识别功能上重要的特征来有效压缩这一空间的能力极其宝贵。 清华大学的研究团队建立了一种称为 EvoScan 的方法,用于全面分割和扫描高适应度序列空间,以获得能够捕捉其基本特征(尤其是在高维度中)的锚点。

指令跟随大比拼!Meta发布多轮多语言基准Multi-IF:覆盖8种语言,超4500种任务
在大语言模型(LLMs)不断发展的背景下,如何评估这些模型在多轮对话和多语言环境下的指令遵循(instruction following)能力,成为一个重要的研究方向。 现有评估基准多集中于单轮对话和单语言任务,难以揭示复杂场景中的模型表现。 最近,Meta GenAI团队发布了一个全新基准Multi-IF,专门用于评估LLM在多轮对话和多语言指令遵循(instruction following)中的表现,包含了4501个三轮对话的多语言指令任务,覆盖英语、中文、法语、俄语等八种语言,以全面测试模型在多轮、跨语言场景下的指令执行能力。

如何简单理解视觉语言模型以及它们的架构、训练过程?
关于视觉语言模型(VLMs),以及它们的架构、训练过程和如何通过VLM改进图像搜索和文本处理的多模态神经网络。 可以参考这篇文章:(VLMs),它们是未来的复合AI系统。 文章详细描述了VLMs的基本原理、训练过程以及如何开发一个多模态神经网络,用于图像搜索。

AI能夺走网文界的一切吗?
AI好好用原创作者:Pandora写网络小说,手拿把掐? 还差得远呢。 AI 学者拿下诺贝尔物理学奖、化学奖后,网友纷纷揶揄说:下一个被 AI 攻陷的诺奖会是 ......

AI搞科研?西湖大学发布「AI科学家」Nova,效果比SOTA竞品提升2.5倍
编辑 | ScienceAI伟大科学家的研究,往往开始于一个小的灵感、小的创意。 长久以来,科学创新与研究能力被视为人类在人工智能时代中坚守的一片独特领地。 然而,一篇来自西湖大学深度学习实验室的论文在科学界掀起了波澜。

成功率提升15%,浙大、碳硅智慧用LLM进行多属性分子优化,登Nature子刊
编辑 | 萝卜皮优化候选分子的物理化学和功能特性一直是药物和材料设计中的一项关键任务。 虽然人工智能很适合处理平衡多个(可能相互冲突的)优化目标的任务,但是例如多属性标记训练数据的稀疏性等技术挑战,长期以来阻碍了解决方案的开发。 在最新的研究中,浙江大学侯廷军团队、中南大学曹东升团队以及碳硅智慧团队联合开发了一种分子优化工具 Prompt-MolOpt。

如何用生成式 AI 定义我们的未来?看看微软怎么说
编辑 | 紫罗人工智能(AI)当下及未来的进步,意味着它在解决先前被视为棘手难题的能力上实现了阶段性的转变。鉴于这一巨大的技术飞跃,现在是我们必须定义未来轨迹的时候了。随着公司继续创新人工智能系统并将其集成到当前产品中,我们有责任问自己:我们想要构建的未来是什么?作为一个社会,我们必须采取立场并定义我们想要的人与人工智能系统之间的关系。我们仍处于人工智能革命的早期阶段,因此现在将我们的轨迹设定在一条认真负责的道路上比以后纠正我们的路线更容易。我们可以有意识地设计、构建和使用人工智能系统,使其成为社会中的一种平衡力量

「两全其美」,从头设计分子,深度学习架构S4用于化学语言建模
编辑 | KX生成式深度学习正在重塑药物设计。化学语言模型 (CLM) 以分子串的形式生成分子,对这一过程尤为重要。近日,来自荷兰埃因霍芬理工大学(Eindhoven University of Technology)的研究人员将一种最新的深度学习架构(S4)引入到从头药物设计中。结构化状态空间序列(Structured State Space Sequence,S4)模型在学习序列的全局属性方面表现卓越,那么 S4 能否推进从头设计的化学语言建模?为了给出答案,研究人员系统地在一系列药物发现任务上对 S4 与最先

为大模型提供全新科学复杂问答基准与测评体系,UNSW、阿贡、芝加哥大学等多家机构联合推出SciQAG框架
编辑 | ScienceAI问答(QA)数据集在推动自然语言处理(NLP)研究发挥着至关重要的作用。高质量QA数据集不仅可以用于微调模型,也可以有效评估大语言模型(LLM)的能力,尤其是针对科学知识的理解和推理能力。尽管当前已有许多科学QA数据集,涵盖了医学、化学、生物等领域,但这些数据集仍存在一些不足。其一,数据形式较为单一,大多数为多项选择题(multiple-choice questions),它们易于进行评估,但限制了模型的答案选择范围,无法充分测试模型的科学问题解答能力。相比之下,开放式问答(openQA
还在满网页扒资料?实测Kimi官方浏览器插件,颈椎这下有救了
机器之能报道编辑:杨文小编们的码字「神器」。Kimi,兵贵神速。前段时间,文风检测器在小红书上风靡一时,Kimi 立马推出该功能。这两天,Kimi 又在悄么声息地搞事情,偷偷上线官方浏览器插件。其实,早前就有个名叫「Kimi Copilot」的插件备受好评,只不过,这是由第三方开发者制作。而此次 Kimi 亲自下场,甩出官方浏览器插件,并为网页用户带来多项新功能。比如:对页面中部分内容划线提问;总结页面内容并生成摘要等。此外,插件还支持全局浮窗和侧边栏两种展示方式,用户可自行切换。我们实测后发现,这款插件简直是苦逼
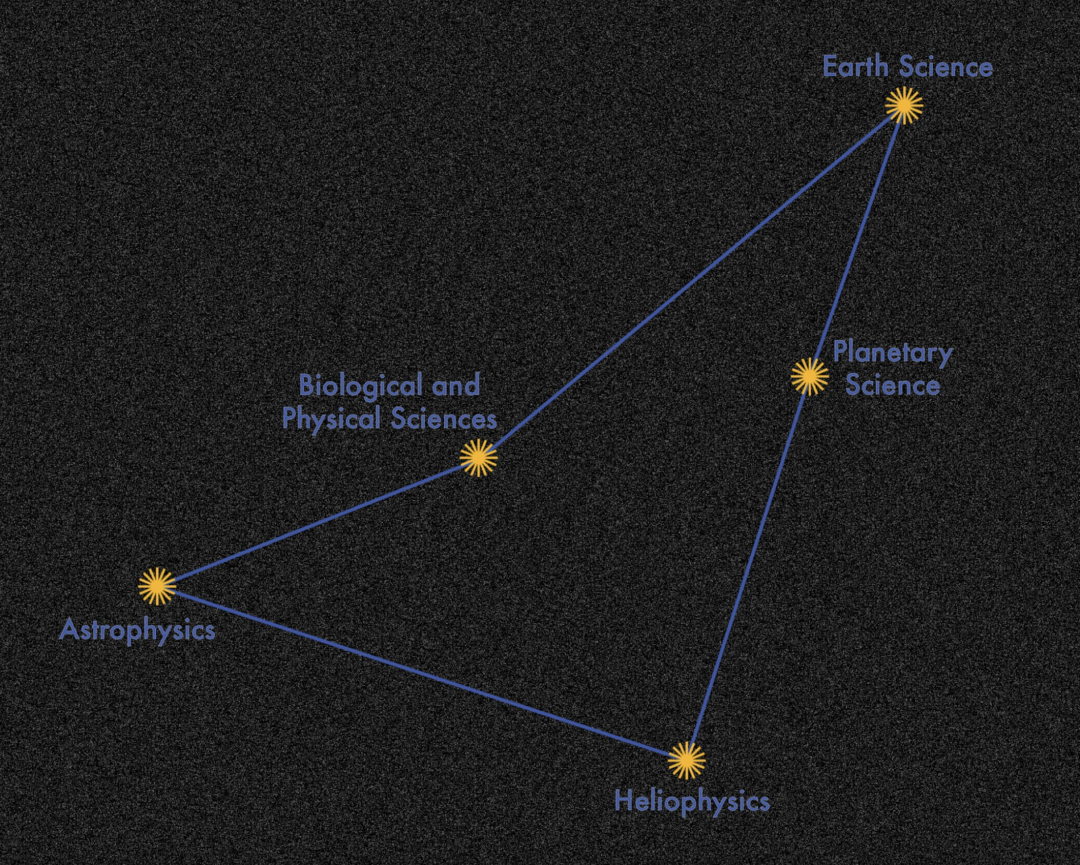
专为五大科学领域定制,NASA与IBM合作开大语言模型INDUS
INDUS 以南天星座命名,是一套全面的大型语言模型,支持五个科学领域。(来源:NASA)编辑 | KX在大量数据上训练的大型语言模型 (LLM) 在自然语言理解和生成任务上表现出色。大多数流行的 LLM 使用 Wikipedia 等通用语料库进行训练,但词汇的分布变化导致特定领域的性能不佳。受此启发,NASA 与 IBM 合作开发了 INDUS,这是一套全面的 LLM,专为地球科学、生物学、物理学、太阳物理学、行星科学和天体物理学领域量身定制,并使用从不同数据源的精选科学语料库进行训练。INDUS 包含两类模型:

多模态AI是医学的未来,谷歌推出三个新模型,Med-Gemini迎来大升级
编辑 | 白菜叶许多临床任务需要了解专业数据,例如医学图像、基因组学,这类专业知识信息在通用多模态大模型的训练中通常不存在。在上一篇论文的描述中,Med-Gemini 在各种医学成像任务上超越 GPT-4 系列模型实现了 SOTA!在这里,Google DeepMind 撰写了第二篇关于 Med-Gemini 的论文。在 Gemini 的多模态模型的基础上,该团队为 Med-Gemini 系列开发了多个模型。这些模型继承了 Gemini 的核心功能,并通过 2D 和 3D 放射学、组织病理学、眼科、皮肤病学和基因组

【论文解读】System 2 Attention提高大语言模型客观性和事实性
一、简要介绍 本文简要介绍了论文“System 2 Attention (is something you might need too) ”的相关工作。基于transformer的大语言模型(LLM)中的软注意很容易将上下文中的不相关信息合并到其潜在的表征中,这将对下一token的生成产生不利影响。为了帮助纠正这些问题,论文引入了System 2 Attention(S2A),它利用LLM的能力,用自然语言进行推理,并遵循指示,以决定要处理什么。S2A重新生成输入上下文以使输入上下文只包含相关部分,然后再处理重新
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉