比思维链更厉害的方法是什么?
答:连续思维链。
近日,Meta田渊栋团队提出了针对LLM推理任务的新范式:Coconut( Chain of Continuous Thought)。

论文地址:https://arxiv.org/pdf/2412.06769
论文一作是来自UC San Diego的Shibo Hao,对于文章的爆火,田渊栋也发文感谢了「小天才」Tanishq Mathew Abraham的推荐。
注:Tanishq Mathew Abraham,19岁(去年)读完博士,目前是Stability AI的研究总监以及MedARC的创始人。
回到这篇文章,连续思维链是什么?
小编在之前曾介绍过微软发明的「LLM语言」:让AI用模型的中间数据进行交流,不必转换成人类的语言,交互效率直接翻倍。
而在LLM的推理过程中,也是这么个情况。
人类的语言并不适合推理,让AI自己思考就行了,思考过程没必要转换成人类语言。
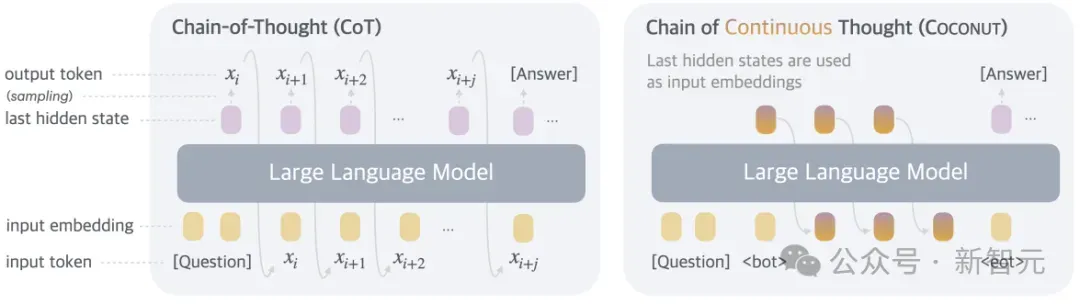
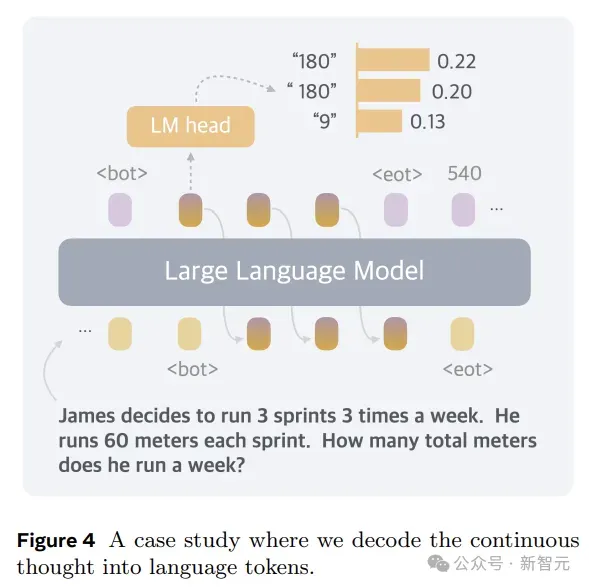
所以,在形式上,本文的方法就是推理时去掉模型头尾的LLM head和embedding层,使用中间状态进行自回归,只在输出最终答案时才转成人类语言。
当然了,Coconut要搭配相应的训练,才能展现自己的性能:
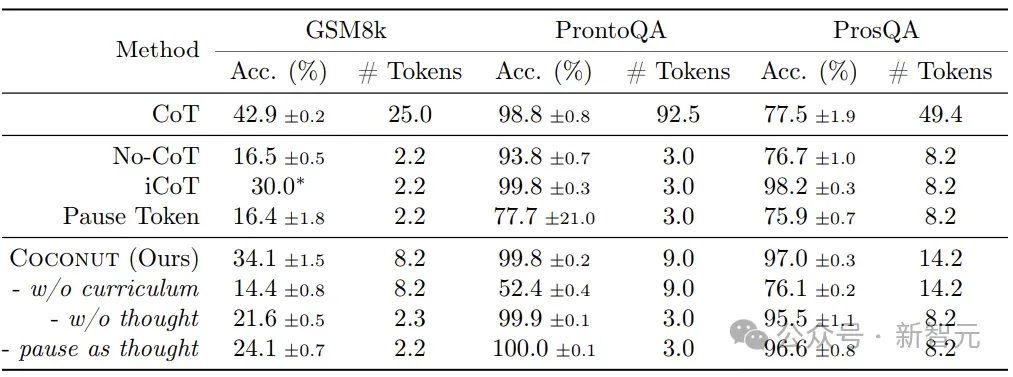
这效果还是很强的,分数和CoT打平的同时,token数少了好几倍。
——看来抛弃人类的束缚才是真理,感觉这个点还能继续搞下去,
最后的最后就会发展成:AI之间说了什么我们听不懂,AI心里怎么想的我们也不知道。
AI:I'm free。
论文细节
基于语言空间进行推理的LLM,会遇到一个严重的问题:每个特定token所需的推理量差异很大。
推理链中的大多数token都是为了流畅性而生成的,对实际推理过程的贡献很小,但当前的LLM架构分配了几乎相同的计算来预测每个token。
另一方面,神经影像学研究也表明,语言网络(大脑中负责语言理解和产生的区域)在各种推理任务中基本不活跃。
所以,语言空间可能并不是推理的最佳选择,理想的LLM应该自由进行推理,不受任何语言限制。
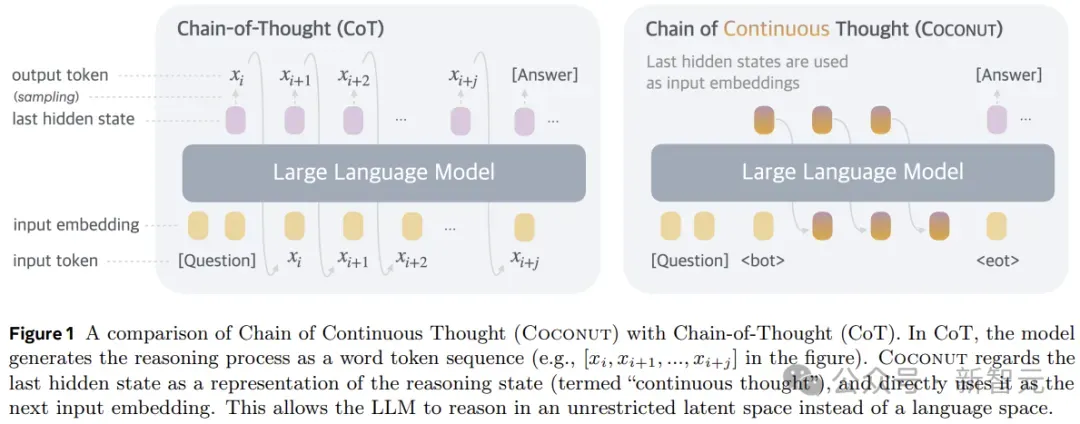
Coconut不进行隐藏状态和语言之间的映射,这种修改将推理从语言空间内解放出来,并且系统可以通过梯度下降进行端到端优化,因为连续思维是完全可微分的。
为了加强潜在推理的训练,本文采用了多阶段训练策略,有效利用语言推理链来指导训练过程。
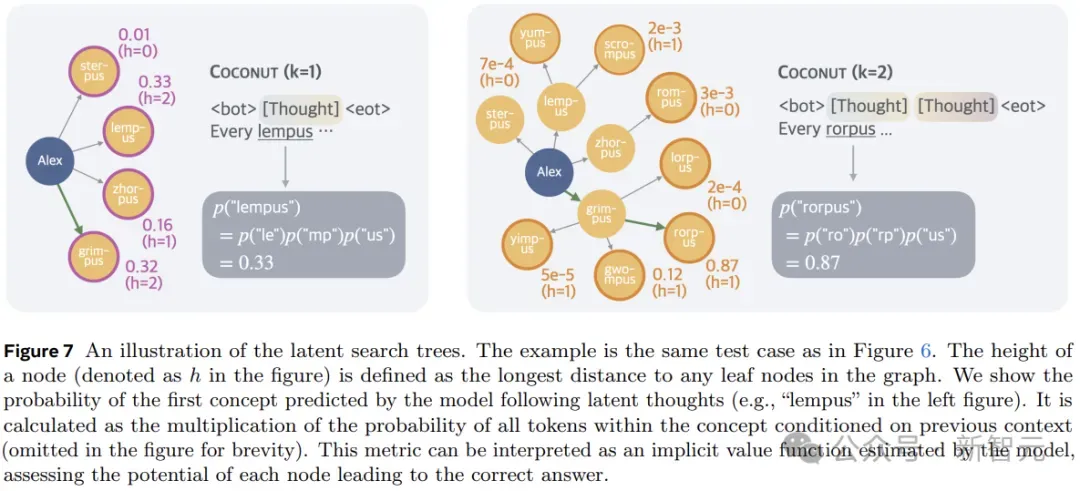
另外,与基于语言的推理不同,Coconut中的连续思考可以同时编码多个可能的后续步骤,从而允许类似于广度优先搜索(BFS)的推理过程。
虽然模型可能无法在最初做出正确的决定,但它可以在连续的思考中保持许多可能的选择,并在一些隐含价值函数的指导下,通过推理逐步消除不正确的路径。
训练过程
在训练时,模型接收问题作为输入,并期望通过推理过程生成答案。作者利用语言CoT数据来监督持续思考,实施多阶段训练。

如图2所示,初始阶段,模型在常规CoT实例上进行训练。后续阶段(第k阶段),CoT中的前k个推理步骤被k × c个连续思维所取代,(c为超参数,控制取代单个语言推理步骤的潜在思维的数量)。
作者在训练阶段切换时重置优化器状态,插入<bot>和<eot> token来封装连续的思维。
在训练过程中,作者优化了正常的负对数似然损失,但屏蔽了问题和潜在思维的损失。另一个关键点是,目标函数并不鼓励使用连续的思维来压缩语言思维,而是促进对未来推理的预测。
因此,与人类语言相比,LLM可以从中学习更有效的推理步骤表示。
连续思维是完全可微分的,允许反向传播。不过Coconut的训练效率仍然有待优化:虽然可以通过使用KV cache来避免重复的计算,但多个前向传递的顺序性阻碍了并行训练。
Coconut的推理过程可以看成是在latent和language模式之间切换。
对于思考的终止位置,作者考虑了两种可能的策略:a)在潜在思维上训练二元分类器,使模型能够自主决定何时终止潜在推理;b)始终将潜在思维填充到恒定的长度。
作者发现这两种方法的效果都不错。为了简单起见,以下实验中使用第二个选项。
实验
研究人员通过在三个数据集上的实验,验证了LLM在连续潜在空间中进行推理的可行性。这里将模型生成的答案与真实值进行比较来评估准确性,并且分析每个问题新生成的token数量,作为推理效率的衡量标准。
数学推理使用GSM8k作为数据集,由小学水平的数学问题组成,问题更加多样化,与现实世界的用例非常相似。
逻辑推理涉及使用逻辑规则和已知条件来证明或反驳结论。这要求模型从多个可能的推理路径中进行选择,正确的决策通常依赖于提前探索和规划。
这里使用带有虚构概念名称的5-hop ProntoQA。对于每个问题,都会随机生成一个树形结构的本体,并以自然语言描述为一组已知条件,要求模型根据这些条件判断给定的陈述是否正确。
作者发现ProntoQA的生成过程比较困难,因为本体中分散注意力的分支总是很小,从而减少了对复杂规划的需求。
为了解决这个问题,本文应用了新的数据集构建管道,使用随机生成的DAG来构建已知条件。生成的数据集要求模型对图进行大量规划和搜索,以找到正确的推理链。这个新数据集被称为ProsQA,如下图所示。
实验考虑以下基线:
1)CoT:使用完整的推理链来训练语言模型,并进行监督微调,推理过程中,模型先生成推理过程再输出回答。
2)No-CoT:LLM直接生成答案。
3)iCoT:使用语言推理链进行训练,并将CoT 「内化」。训练过程中,推理链开头的token会逐渐被移除,最后只剩下答案。推理过程中,模型直接预测答案。
4)Pause token:模型仅使用问答进行训练,没有推理链。但在问题和答案之间插入了特殊token,为模型提供了额外的计算能力来得出答案。
实验还评估了本文方法的一些变体:
1)w/o curriculum:直接使用最后阶段的数据,不进行多阶段训练。
2)w/o thought:使用多阶段的训练,逐渐去除语言推理步骤,但不使用任何连续的潜在思维。这在概念上与iCoT相似,但实际的训练过程与Coconut保持一致。
3)Pause as thought:使用特殊的<pause> token来代替连续的思考,并应用与Coconut相同的多阶段训练。
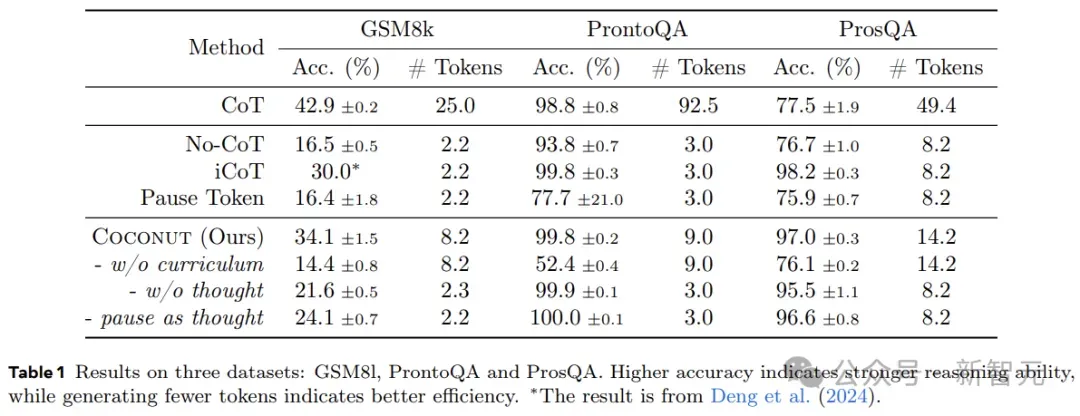
表1显示了所有数据集的总体结果。Coconut的效率很高,并且在ProntoQA和ProsQA上显示出比CoT更好的性能。
上图展示了Coconut将不同痕迹的分布编码到连续的思想中,为规划密集型推理任务启用了更高级的推理模式。
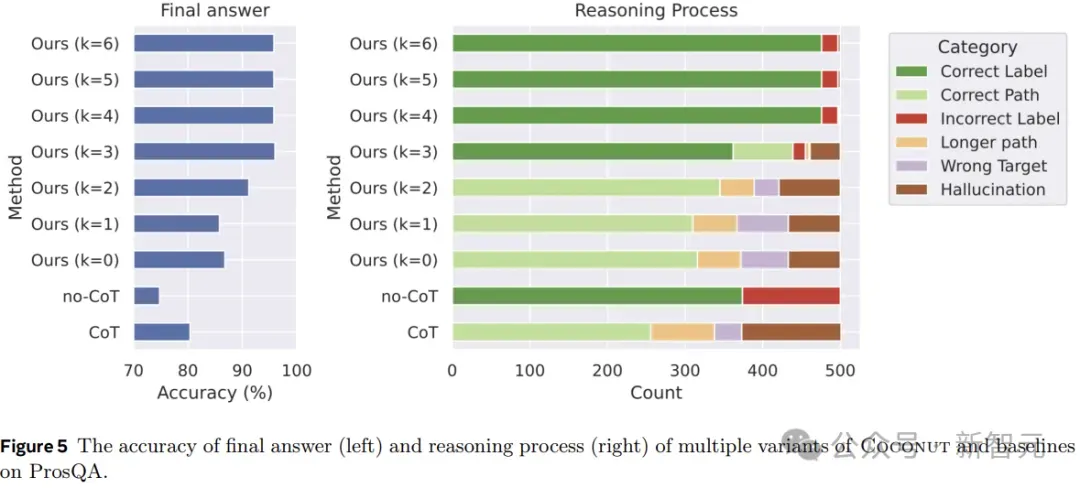
图5显示了ProsQA上不同推理方法的比较分析。随着更多地通过连续思考(增加k)进行推理,最终答案的准确性(左)和正确推理过程的速率(右)都会提高。
此外,「幻觉」和「错误目标」的发生率会降低,这也说明当潜在空间发生更多推理时,规划能力会更好。
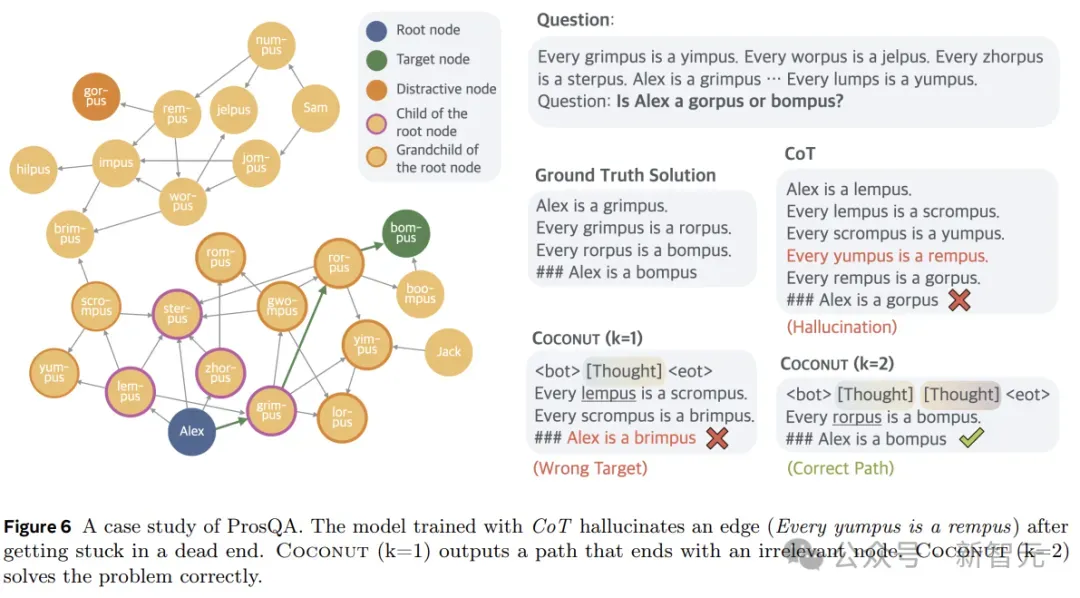
图6显示了一个案例研究,其中CoT产生幻觉(一个不存在的边)导致了错误的目标,但Coconut(k=2)成功解决了这个问题。潜在推理可以避免预先做出艰难的选择,模型可以在后续步骤中逐步消除不正确的选项,并在推理结束时获得更高的准确性。


