数字人

美团开源虚拟人视频生成模型 LongCat-Video-Avatar:号称“不说话”时都像人
AI在线 12 月 18 日消息,据“龙猫 LongCat”公众号今晚的推文,美团 LongCat 团队正式发布并开源 SOTA 级虚拟人视频生成模型 ——LongCat-Video-Avatar。 该模型基于 LongCat-Video 基座打造,延续“一个模型支持多任务”的核心设计,原生支持 Audio-Text-to-Video、Audio-Text-Image-to-Video 及视频续写等核心功能,同时在底层架构上全面升级,实现动作拟真度、长视频稳定性与身份一致性三大维度的突破。 据官方介绍,该模型具备如下技术亮点。

首个数字人国家标准,商汤牵头定义,正式发布!
商汤科技作为牵头单位,主导完成了我国虚拟数字人领域首项国家标准——《信息技术 客服型虚拟数字人通用技术要求》(GB/T 46483-2025)的起草与制定工作。 在该标准的形成过程中,在中国电子技术标准化研究院指导下商汤科技联合三十余家产学研用单位,共同完成了标准框架的搭建与细节的完善。 该项国家标准历经两年立项筹备,已于近期正式发布,为客服型虚拟数字人系统的设计、开发、测试、应用及维护等环节提供了统一的技术规范与参考指南。

京东全球科技探索者大会聚焦“Enjoy AI”:CEO 许冉现场演示数字人助手点外卖
主题为“Enjoy AI”的 JDDiscovery-2025京东全球科技探索者大会近日在北京成功举行。 大会的亮点之一是京东集团 SEC 副主席、CEO 许冉在演讲中,利用京东最新发布的数字人万能助手——“他她它”,为现场嘉宾们点咖啡外卖,展示了 AI 在日常消费场景中的实际应用。 许冉在演示中,通过语音指令唤醒了“他她它”的昵称——“万能博士”,并直接下达了“帮我给会场的朋友点杯咖啡吧”的点餐指令。

从「对口型」到「会表演」,刚进化的可灵AI数字人,技术公开了
让数字人的口型随着声音一开一合早已不是新鲜事。 更令人期待的,是当明快的旋律响起,它会自然扬起嘴角,眼神含笑;当进入说唱段落,它会随着鼓点起伏,肩膀与手臂有节奏地带动气氛。 观众看到的不再只是嘴在动,而是整个人在表演。

AI实战:一键生成数字人视频!
做自媒体行业的同学都知道,制作一条可发布的视频成本是很高的,通常我们需要先录制原始视频,而录制原始视频的时间通常是发布视频时长的 3-5 倍,之后还需要花费很长的时间剪辑,最终才能制作一条可发布的视频,相当费时费力。 但是,技术发展到今天,我们可以使用数字人来自动生成视频。 这样每天就能简单且高效的产出 N 条视频了,而且无需修剪、也不用担心出错,这样就大大减低了视频制作的成本,提高了工作效率。
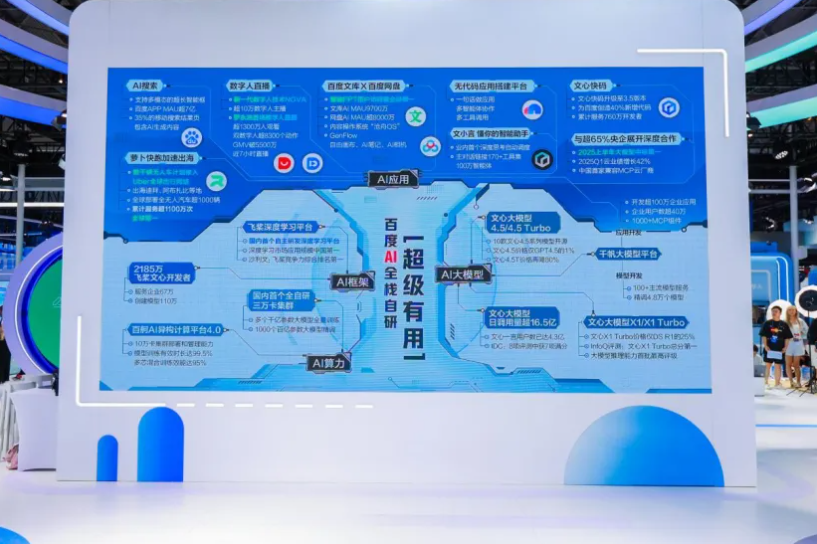
直击WAIC:萝卜快跑入选「国家队」,AI数字人技术升级,百度全栈自研杀疯了
前几天,奥特曼在采访中透露,亲自体验 GPT-5 后,被其强大的能力吓到。 有个自己都搞不懂的问题,模型却能一下答出来,那一刻他甚至觉得自己在擅长的领域也有些「无力」。 尽管 AI 进展飞快,但总有人质疑:真正落地的 AI 不多,很多所谓的新技术,可能只是炒作。

如何做到在手机上实时跑3D真人数字人?MNN-TaoAvatar开源了!
TaoAvatar 是由阿里巴巴淘宝 Meta 技术团队研发的 3D 真人数字人技术,这一技术能在手机或 XR 设备上实现 3D 数字人的实时渲染以及 AI 对话的强大功能,为用户带来逼真的虚拟交互体验。 它是如何实现的呢? 本文将为您揭秘 TaoAvatar 背后的黑科技!

百度首推双数字人互动直播间,文心大模型4.5T驱动多模态技术新突破
近日,百度在人工智能领域再下一城,推出了全球首个双数字人互动直播间。 这一创新应用基于百度文心大模型4.5Turbo(以下简称4.5T),通过语言、声音和形象的多模态高度融合,实现了数字人与用户之间的自然、流畅互动,为直播行业带来了全新可能。 AIbase结合网络最新信息,深入解析这一技术突破及其对行业的深远影响。

罗永浩数字人百度电商首播告捷:26分钟GMV超真人1小时
备受关注的罗永浩数字人近日在百度电商平台首次开启直播,并取得了显著的成绩。 据报道,数字人直播间仅开播26分钟,其商品交易总额(GMV)便超越了罗永浩真人1小时的带货金额,展现出数字人直播带货的巨大潜力。 百度方面介绍,此次罗永浩数字人的成功首秀,主要得益于百度在高说服力数字人等关键技术上的突破。

Higgsfield推出Speak功能:一键生成口型精准的数字人视频
AI视觉生成平台 Higgsfield 再推重磅功能——“Speak”,为数字人内容创作者带来前所未有的便捷体验。 用户只需三步:选择预设动作、上传自定义角色并输入语音文本,即可生成具备口型同步与自然动作的数字人视频。 Speak功能支持精确的口型同步技术,确保角色发音自然、对口,并配套 16种内置场景类型,涵盖访谈、讲解、广告、短剧等多样化内容风格,极大提升了创作自由度和内容质量。

腾讯开源混元语音数字人模型:一张图一段音频就能让图中人物说话唱歌
腾讯混元公众号今日发文宣布开源混元语音数字人模型,仅需一张图和一段音频,就能让图中的主角自然地说话、唱歌。

京东:数字人带货水平超 80% 真人主播
京东数字人直播成本仅为真人1/10,带货成绩却超越80%真人主播,超10,000家商家已使用。京东近期推出高商业可用数字人,支持精品音色微调、精准声唇对齐等功能,今年618还将推出六大行业定制数字人。#京东数字人##AI直播#

AI 技术首次亮相美国法庭:家属用“数字人”呈现已故被害人言辞
亚利桑那州一名公路暴力案件的凶手上周被判刑10年半,这一判决背后涉及一起创新的法律程序:受害人通过AI向法庭发表了讲话。官方称,这可能是首次使用该技术的案件。

百度发布高说服力数字人,可在电商直播领域带来超越真人体验
百度在Create大会上发布高说服力数字人,声形超拟真、互动灵活,能在电商直播等领域带来超越真人的体验。背后依托百度慧播星的“剧本生成”能力和“AI大脑”,实现高度融合的脚本与动作,并实时调整直播策略。#百度数字人# #电商直播#
腾讯混元大模型AI阅读助手——企鹅读伴正式上线
4月23日,腾讯在世界读书日当天正式上线了一款名为“企鹅读伴”的AI阅读助手。 这是由腾讯混元大模型和腾讯元器平台提供技术支持的创新产品,由腾讯SSV数字支教实验室主导研发设计,旨在为中小学生带来一场充满科技感与趣味性的阅读新体验。 在产品设计上,“企鹅读伴”能够根据学生的年级、阅读能力以及兴趣偏好,精准推荐适合的阅读书目。

李彦宏将于25日在Create2025百度AI开发者大会发表首场演讲,揭示百度AI新动态
今日,百度创始人李彦宏的25年首场演讲海报正式曝光。 根据海报信息,李彦宏将在4月25日的Create2025百度AI开发者大会上带来一场为期1小时的主题演讲,题为《模型的世界,应用的天下》。 演讲内容将聚焦AI领域的热门议题,包括MCP、智能体、数字人、模型成本等,引发业界广泛关注。

大厂实战案例!百度数字人直播体验改版复盘
前言. 电商直播行业从 2016 年淘宝上线直播历经 8 年增长,供需两端发生变革,越来越多并不擅长直播的商家从幕后走向前台“店播带货”, 消费者购买决策因素逐渐增多的同时,也对直播质量要求越来越高,这促使直播服务商们纷纷开辟出组合数字人主播和数智化直播流程的新直播带货解决方案,百度「慧播星平台」就是其中之一。 百度「慧播星平台」是全栈式的数字人直播解决方案,依托百度自研视觉模型/StyleSync/音频训练/PicGen/文心一言等 AI 技术,实现商家快速开播,带来用户端 7*24 小时不间断、智能专业的超拟真看播体验。

行业首个:“中国石化 AI 数字员工”上岗,指导车主自助加油付款
中国石化 1 月 18 日在北京举行数字员工发布仪式,正式推出首位“AI 数字员工”,并在广西南宁新阳站等全国 40 余座加能站同步试点上岗。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉