TaoAvatar 是由阿里巴巴淘宝 Meta 技术团队研发的 3D 真人数字人技术,这一技术能在手机或 XR 设备上实现 3D 数字人的实时渲染以及 AI 对话的强大功能,为用户带来逼真的虚拟交互体验。
它是如何实现的呢?本文将为您揭秘 TaoAvatar 背后的黑科技!同时在今天,我们正式宣布开源了 3D 真人数字人应用:MNN-TaoAvatar!目前应用源码已同步发布在 MNN 的 GitHub 仓库,开发者可自行下载安装和体验,欢迎大家和我们一起交流讨论,共同探索 AI 数字人技术的无限可能。
什么是 TaoAvatar?
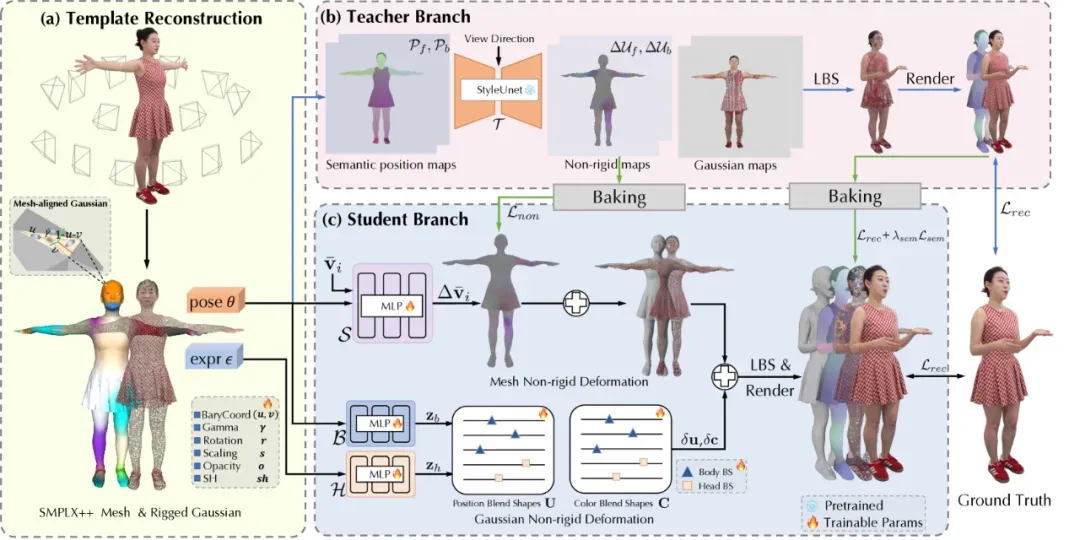
TaoAvatar 是淘宝在数字人技术领域取得的最新突破,更多详细的研究成果已经发表在相关论文。

- 论文标题:TaoAvatar: Real-Time Lifelike Full-Body Talking Avatars for Augmented Reality via 3D Gaussian Splatting
- 论文地址:https://arxiv.org/abs/2503.17032v1
- 开源地址:https://github.com/alibaba/MNN/blob/master/apps/Android/MnnTaoAvatar/README_CN.md
TaoAvatar 基于先进的 3D 高斯泼溅技术,提供了一套全身互动式的真人数字人解决方案。它通过多视角视频的输入,可以迅速生成具有高逼真度的数字人形象,这些形象不仅能够精准地捕捉到细腻的面部表情和手势动作,甚至连衣物细微的褶皱以及头发的自然摆动都能清晰呈现,带来一种自然而真实的视觉体验。
值得一提的是,TaoAvatar 还同时显著降低了数字人建模的成本,大幅提高了建模效率,从而为数字人的规模化应用提供了基础。在中国三维视觉大会上,TaoAvatar 凭借其卓越的性能和广泛的适用性,成功入选「最佳演示 Demo 候选」,吸引了业界的广泛关注,成为数字人技术研究领域的一个亮点。
什么是 MNN-TaoAvatar?
MNN-TaoAvatar 是我们推出的一款开源的 3D 数字人应用,它集成了多项领先的 AI 技术,支持实时 3D 数字人语音交互,使用户能够在手机上实现与数字人的自然交流,仿佛真的在与一个「活生生」的人交谈。MNN-TaoAvatar 不仅能够在手机端流畅运行,还完美兼容了 XR 设备。如下是在 Android 手机及 Apple Vision Pro 设备上的体验效果:
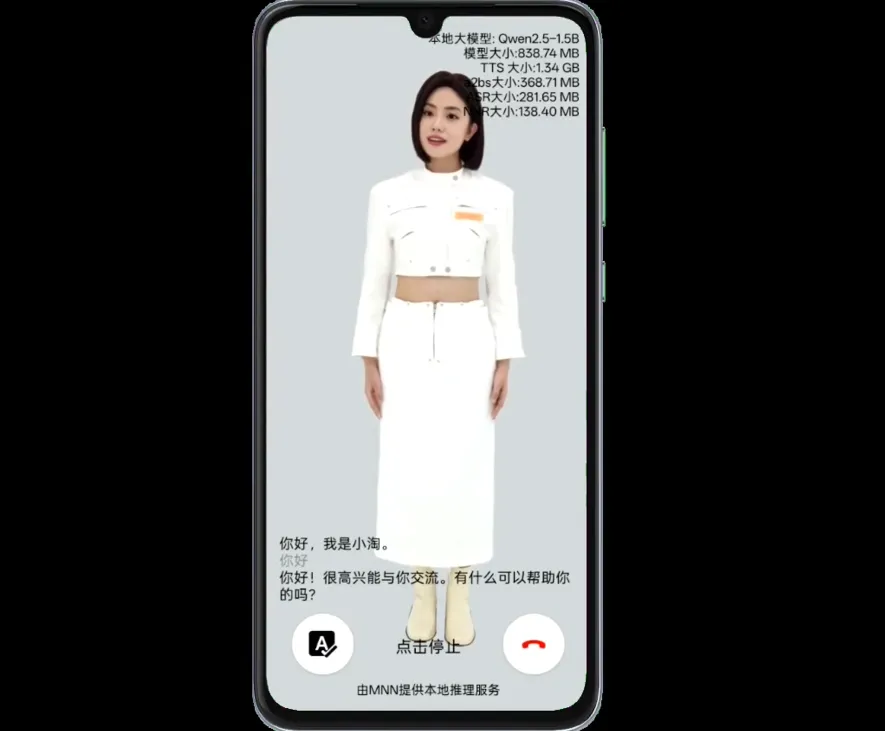

MNN-TaoAvatar 集成了多项关键技术,包括精准的语音识别能力,能够准确理解你的每一句话;先进的大语言模型,可以深入理解你的意图和情感;以及自然流畅的语音合成技术,能够以自然流畅的方式进行回应。更令人惊艳的是,它能够根据语音实时驱动面部表情的变化,从而带来更加生动真实的对话体验。
这一切的背后,是最新算法模型提供的强大支持。基于端侧 AI 推理引擎 MNN,我们研发了一系列的核心模块,包括运行大语言模型的 MNN-LLM、语音识别模型的 MNN-ASR、语音合成模型的 MNN-TTS,以及数字人渲染的 MNN-NNR。
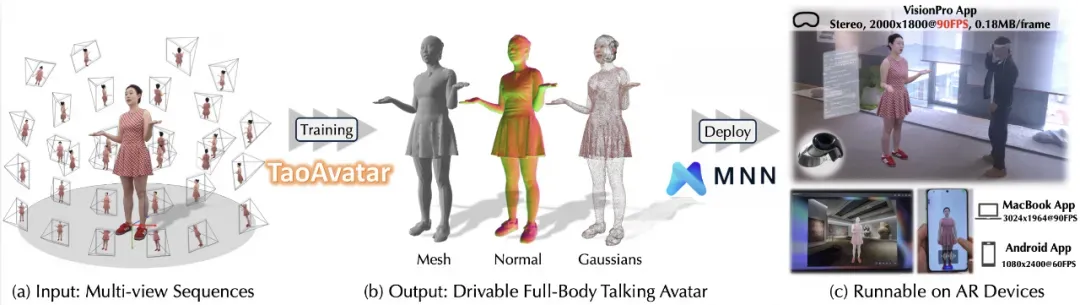
现阶段市面上的数字人方案很多,但基于 MNN 运行的 TaoAvatar 有哪些独特优势呢?
目前大多数主流的数字人方案主要基于云端 AI 算法,这些方案需要依赖强大的服务器和高性能显卡资源,才能完成 ASR(Audio-Speech-Recognize,语音识别)、TTS(Text-To-Speech,语音生成)以及 A2BS(Audio-To-BlendShape,音频驱动面部表情)等复杂处理任务。即便一些开源方案支持本地运行,往往也需要配备较为高端的硬件。
例如需搭载 RTX 3090 或更高规格显卡的设备,才能确保流畅地执行推理和渲染任务。相比之下,MNN-TaoAvatar 则能够在仅一部手机上即可运行上述所有算法模型以及 3D 模型,展现出极高的效率和便捷性。
MNN-TaoAvatar 具有两个核心优势:端侧实时对话和端侧实时渲染。
端侧实时对话
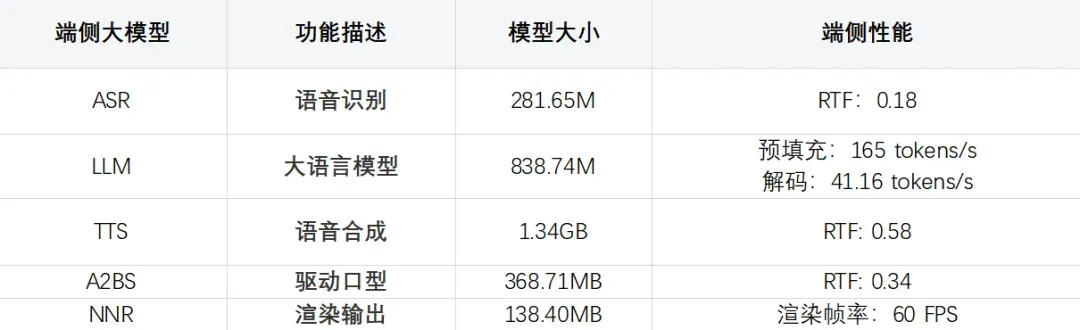
首先,为了实现端侧的实时对话,需要将 ASR(自动语音识别)、TTS(文本转换语音)和 A2BS(口型驱动)的综合 RTF(Real Time Factor,实时因素)控制在 1 以内,即能在 1 秒内生成 1 秒长度的语音,RTF 值越小生成速度越快。通过持续优化,我们取得了以下突破:
- 将 281 MB 的端侧 ASR 模型的 RTF 优化到了 0.18,实现了用户语音在端侧的实时转文本;
- 端侧大语言模型预填充速度最快可达 165 token/s,解码速度可达 41 token/s,确保了流畅的文本内容生成;
- 将 1.34 GB 的端侧 TTS 模型 RTF 优化至 0.58,实现了文本到语音的实时合成与播放。
端侧实时渲染
为了让数字人的面部动作更为自然,渲染过程主要分为两个关键步骤:首先,根据语音输入,通过算法模型精准提取面部表情动作的系数,然后将表情系数和数字人 3D 模型的预录数据进行融合,最终借助 NNR 渲染器完成高质量渲染。这两部分我们做到的性能如下:
- 成功将 368 MB 的端侧 A2BS 模型的 RTF 优化至 0.34,实现了实时语音到面部表情系数的转换。
- 通过自主研发的高性能 NNR 渲染器,达到了对 25 万点云模型以每秒 60 帧(FPS)的流畅渲染速度,确保了动画的顺滑自然。
上文提及的具体端侧模型的功能及我们做到的技术指标如下(基于搭载高通骁龙 Snapdragon 8 Elite芯片的智能手机测试结果):
MNN-TaoAvatar 整体流程
在用户尚未输入语音的情况下,MNN-TaoAvatar 会利用 MNN-NNR 来渲染默认的数字人模型姿态,生成闭唇、静态表情或者预设动作的画面。一旦用户开始语音输入,系统将按以下流程运行:
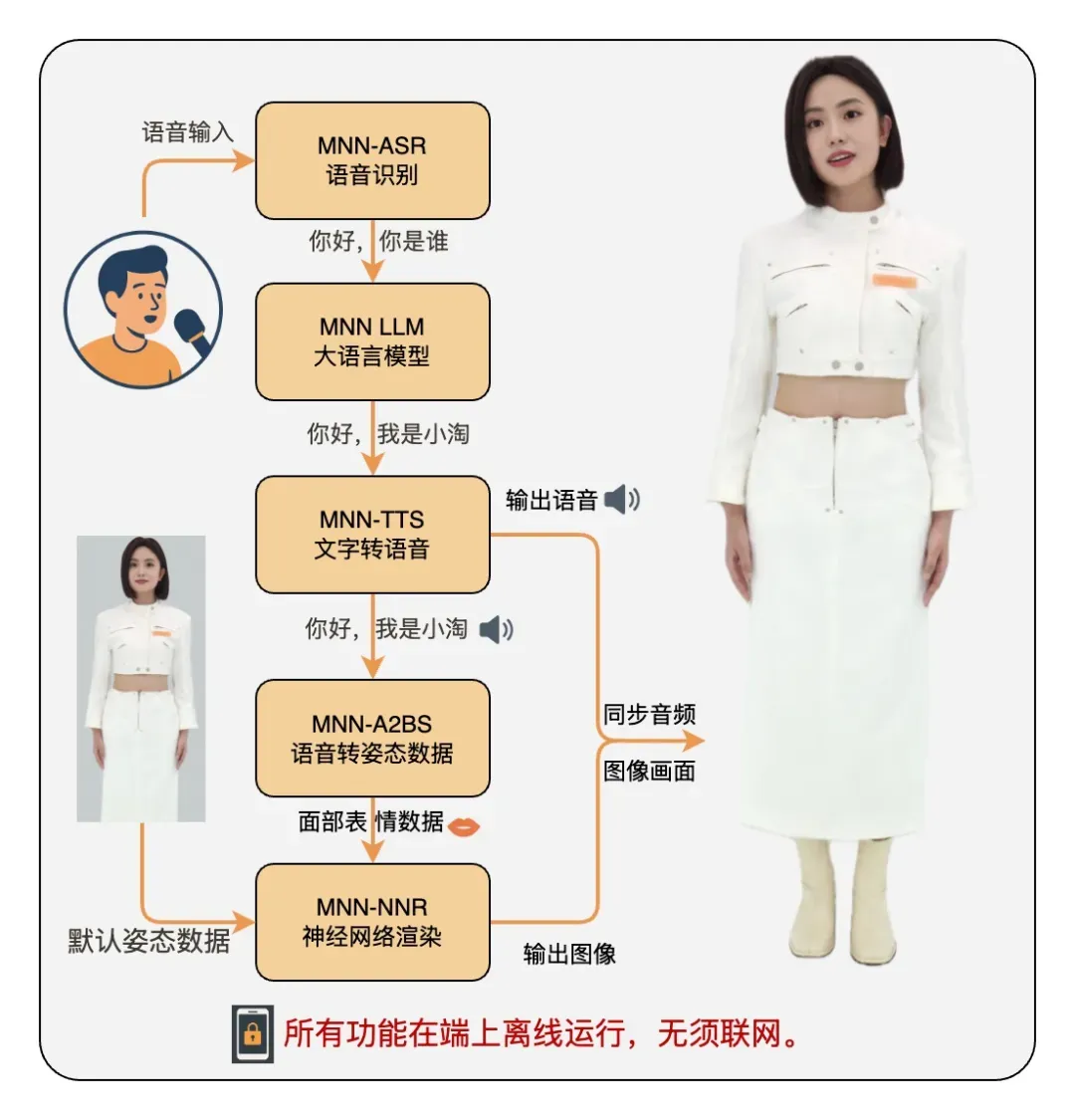
MNN-TaoAvatar 运行关键流程
基于这一流程,用户便能够与一个自然流畅、表情生动的数字人进行实时对话了。在该流程的背后,MNN 框架在技术实现和性能优化上做出了大量的努力。接下来,我们将深入探讨 MNN-TaoAvatar 的技术架构及其关键优化点。
MNN-TaoAvatar 关键技术
MNN-TaoAvatar 是基于 MNN 引擎构建而成的,它集成了 MNN-LLM、MNN-NNR 以及 Sherpa-MNN(包括 MNN-ASR 和 MNN-TTS)等多种算法模块。下图展示了这些模块在应用中的架构示意:
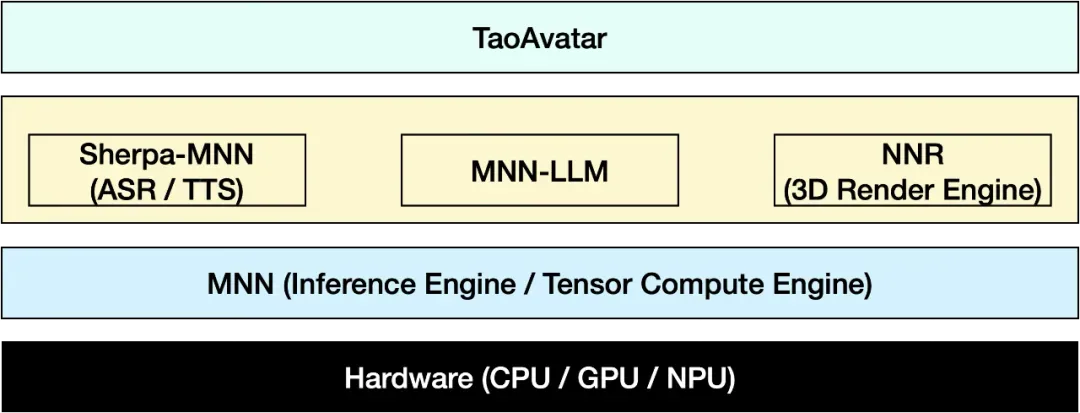
MNN-TaoAvatar 架构示意图
MNN:轻量级 AI 推理引擎
MNN(Mobile Neural Network)是一款功能强大的开源、跨平台 AI 模型推理引擎。

MNN 架构示意图
它的核心优势如下:
- 高性能推理:支持 CPU/GPU/NPU 等多种异构计算方式,能够轻松满足增强现实/虚拟现实(AR/VR)、语音识别以及大型语言模型(LLM)等需要快速响应的实时应用;
- 跨平台兼容:支持 C++、Python、Java 和 JavaScript 等多种语言接口,并与主流系统平台无缝集成;
- 模型轻量化:内置了量化与剪枝工具,有效压缩了模型大小,大幅节省内存空间并缩短加载时间。
MNN-LLM:移动端部署大模型
MNN-LLM 是基于 MNN 之上开发的 MNN-Transformer 模块的一个子功能模块,用于支持大语言模型与文生图等 AIGC 任务。它包含以下关键技术:
- 模型导出工具:能一键将主流 LLM/Diffusion 模型转换为 MNN 格式,大大简化了模型的部署和使用过程;
- 模型量化机制:将大型模型如 Qwen2.5-1.5B 从原来的 5.58 GB 压缩至 1.2 GB,同时保持较快的解码速度,达到每秒 45 个 token;
- KV 缓存/LoRA 支持:利用 KV 缓存技术,MNN-LLM 显著提升了对话响应的速度;LoRA 技术的应用也使得模型能够灵活适配不同的任务场景,而无需重新训练整个模型,从而降低了计算资源的消耗。
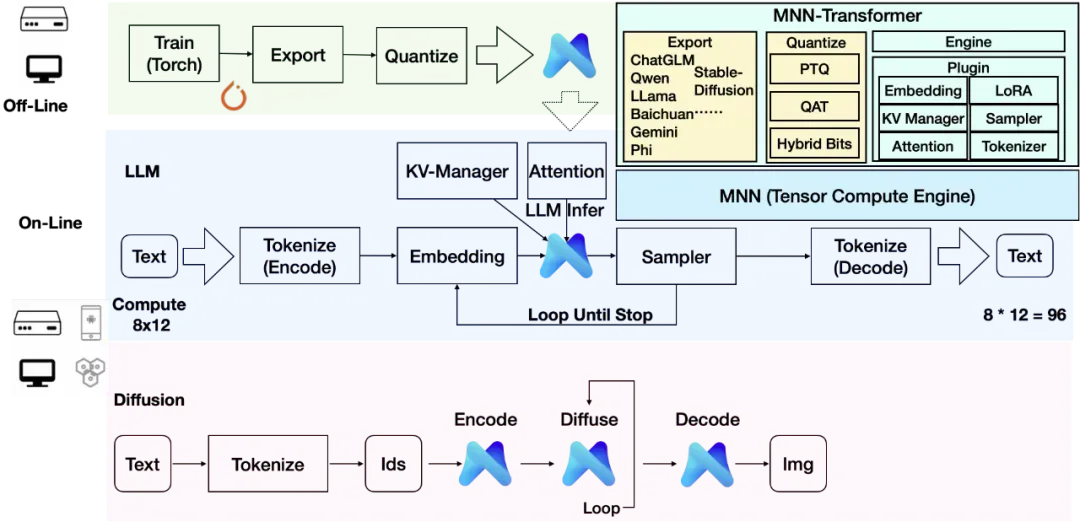
MNN-Transformer 架构示意图
MNN-Transformer 由三个核心部分构成:导出工具、量化工具以及插件与引擎。
- 导出工具负责将各类大型模型转化为 MNN 格式,并创建必要的资源包;
- 量化工具能有效减少 MNN 模型的体积,从而降低运行时的内存,加快执行速度;
- 插件与引擎模块则提供了 LLM/Diffusion 运行时所需的关键功能,如分词、KV 缓存管理以及 LoRA 等。
在小米 14 手机(搭载高通骁龙 8 Gen 3 芯片)上进行的测试中,MNN-LLM 展现了卓越的 CPU 性能。其预填充速度相较于 llama.cpp 提高了 8.6 倍,较 fastllm 更是提升了 20.5 倍。在解码速度方面,MNN-LLM 同样表现优异,分别达到了 llama.cpp 的 2.3 倍和 fastllm 的 8.9 倍。
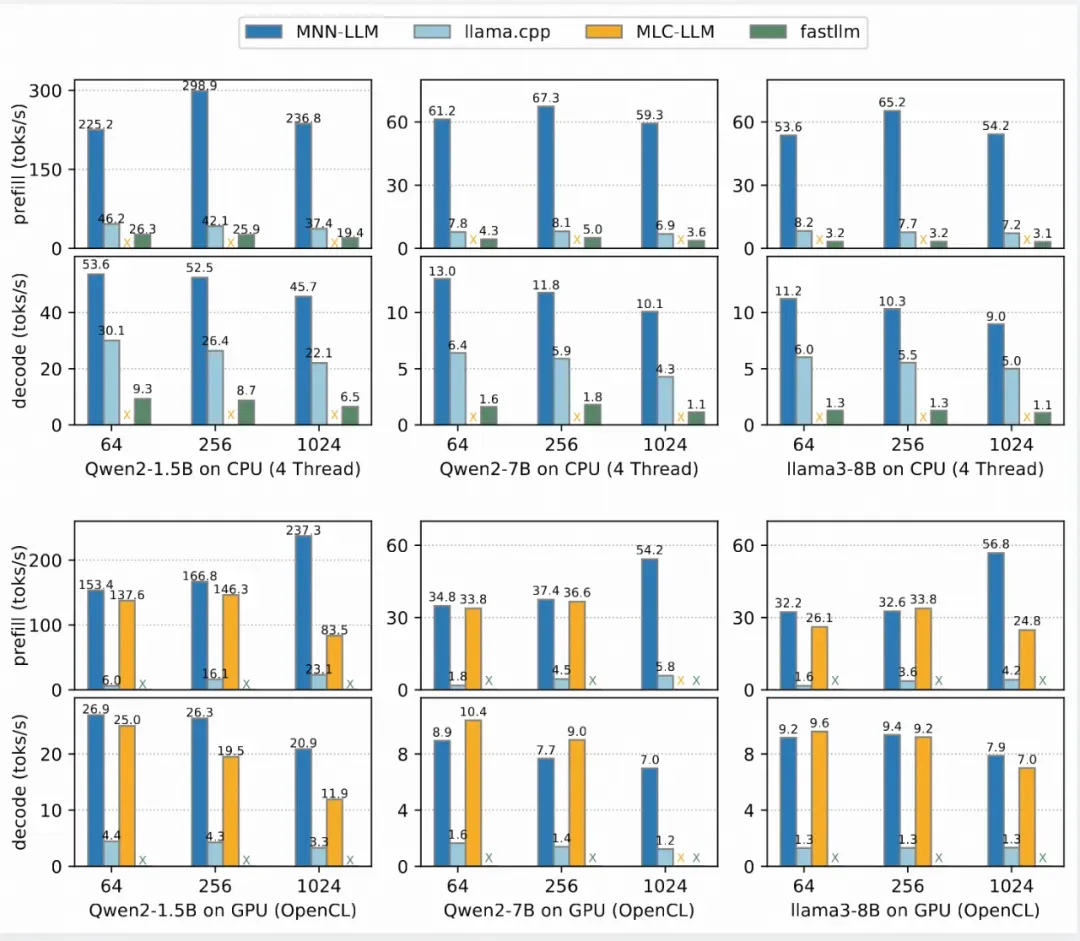
MNN-LLM Benchmark
Sherpa-MNN:离线语音智能新方案
为提升语音识别在端侧上的表现,MNN 团队对原始 sherpa-onnx 框架进行了深度优化,推出 Sherpa-MNN,它支持 ASR(自动语音识别)和 TTS(文本转语音)算法,并具备如下优势:
- 性能翻倍:在 MacBook Pro M1 上(基于 arm64 架构),单线程运行经过量化处理的流式 ASR 模型(具体模型为 sherpa-onnx-streaming-zipformer-bilingual-zh-en-2023-02-20)。在这一测试中,onnxruntime 的 RTF(实时因子)为 0.078,而 MNN 的 RTF 仅为 0.035,相比于 onnxruntime 快出一倍。
- 包体积更小:在功能相同、性能更优的情况下,MNN 的体积仅为 onnxruntime 的五分之一(对于 Android arm64 架构,MNN 的体积为 3.3 MB,而 onnxruntime 则需 15 MB)。
MNN-NNR:高效神经网络渲染引擎
MNN-NNR 是 TaoAvatar 的核心 3D 渲染引擎,专为在移动设备上实时渲染高质量数字人模型而设计。其核心的技术优势如下:
- 开发简便:通过将算法与渲染过程解耦,开发者可以更专注于算法的创新与优化。使用 PyTorch 训练的模型可以轻松导出为 NNR 模型并部署,无需深厚的图形编程经验。
- 极致轻量:通过将计算逻辑离线「编译」为深度学习模型和渲染图,运行时只需要执行深度学习模型和渲染图,因此整个包体大小极小(以 Android 为例,仅需 200k)。并且首次集成后,几乎无需变更。业务功能的扩展由离线编译器处理,算法的迭代只需更新 NNR 文件即可,实现了算法迭代与引擎集成的解耦。
- 高性能:结合 MNN 的高效执行能力,MNN-NNR 通过引入「Dirty 机制」和免拷贝技术,确保了渲染过程的高效执行,从而实现流畅的渲染效果。
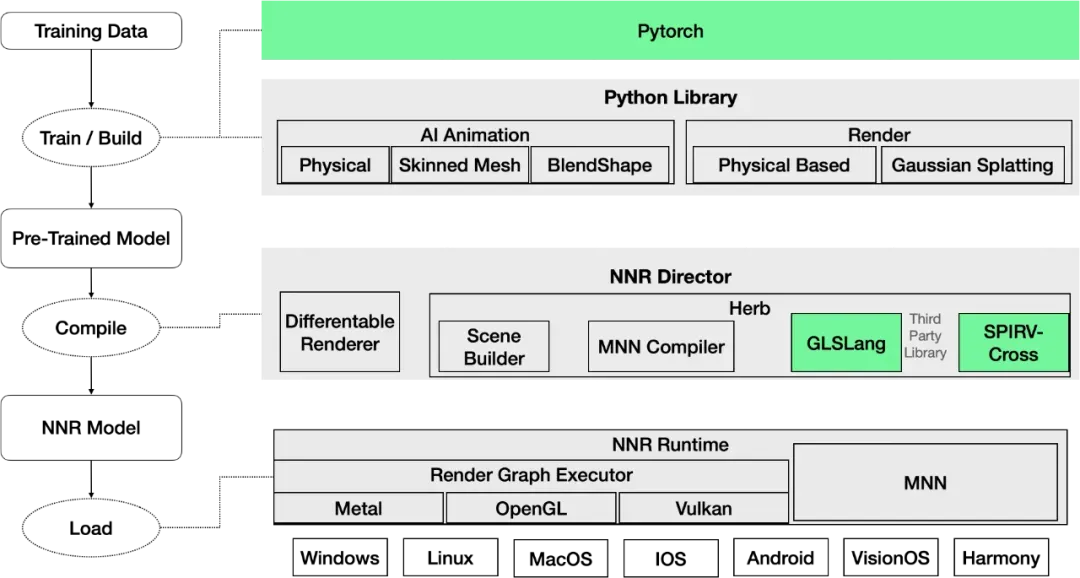
MNN-NNR 架构示意图
为了让数字人模型能够实现高效的渲染,我们进行了以下几项深度优化:
- 数据同步优化
为了消除数据同步所需的时间,我们让所有模型都在 MNN GPU 后端上运行,并在 NNR Runtime 中配置 MNN 所使用的 GPU 后端与渲染共享同一个上下文。这样,MNN Tensor 的数据就直接存储在 GPU 内存中。NNR Runtime 实现了直接读取 MNN Tensor GPU 内存的方案,无需进行数据拷贝即可直接用于渲染,从而免除了数据同步的时间。
- 调度优化
在 NNR Runtime 中,我们实现了「Dirty 机制」,每一帧只运行输入数据发生变化的 MNN 模型。在 TaoAvatar 场景中,深度模型包括 Base Deformer、Aligner、Deformer、Color Compute 和 Sort 等。由于动态高斯数字人重建所需的图像是以 20 帧/秒的速度采集的,为了保持高斯数字人动作的平滑性和一致性,驱动高斯数字人动作的参数只需以 20 fps 的频率设置即可。
因此,Base Deformer、Aligner 和 Deformer 只需以 20 fps 的频率运行。在视角变化不大的情况下,也不需要每帧都对高斯点进行排序,所以 Sort 模型通过另一个开关来控制运行。这样,每帧实际运行的模型就只剩下 Color Compute,从而大幅降低了整体的运行时间。
- 模型运行时间优化
对于使用 MNN 编译器的模型,将输入数据进行 fp16 压缩,可以提升 50% 的性能。
对于高斯排序,MNN 实现了基于 GPU 的基数排序算法,并且利用 autotuning 技术,确保在各类 GPU 上都能达到最佳性能。
在这些优化的加持下,MNN-NNR 成功实现了在动画模型仅以较低频率(如 20 fps)更新的情况下,画面依然能够以 60 fps 的流畅度进行输出。
3D 高斯数字人:小模型也能高质量
传统高斯点云重建成本高、存储体积大,而 TaoAvatar 采用了全新的多重优化方案:
- StyleUnet+MLP 混合建模:通过一个功能强大的 StyleUnet 教师网络,学习复杂的姿势变化,并将这些信息高效地「烘焙」到轻量级的 MLP 学生网络中,极大降低了计算成本。
- 动态高斯点云技术:将单帧重建的静态高斯点云,升级成为可复用多帧数据的动态高斯点云技术。这不仅显著提升了渲染效果的稳定性与清晰度,还显著减少了渲染过程中的闪烁现象。
- 高压缩率资产压缩算法:在 25 万点云的量级下,模型文件大小仅约 160 MB,非常适合在端侧设备上部署。
通过相同素材重建得到的数字人模型,在不同高斯点云数量下,会呈现出不同的清晰度、模型体积和渲染性能。为了找到最佳的平衡点,我们进行了多种不同点云数量模型的测试:

经过综合对比,25 万高斯点云的数字人是终端侧部署的最佳配置方案,它不仅确保了渲染时的高清晰度,还将单个 ID 的存储空间精妙地控制在 100 到 200 MB 之间。
使用说明
硬件要求
虽然我们已经进行了大量的优化工作,但由于需要将多个模型集成到手机中,所以对手机性能还是有一定要求的。以下是 MNN-TaoAvatar 的推荐配置:
- 需要高通骁龙 8 Gen 3 或同等性能 CPU。
- 需要至少 8 GB 内存用于模型运行。
- 需要至少 5 GB 空间用于存放模型文件。
⚠️ 性能不足的设备可能会遇到卡顿、声音断续或功能受限哦。
快速体验
想要亲自体验一下吗?只需按照以下简单的步骤操作即可。
首先克隆项目代码:
复制git clone https://github.com/alibaba/MNN.git cd apps/Android/Mnn3dAvatar
然后构建并部署:
连接你的安卓手机,打开 Android Studio 点击「Run」,或执行:
复制/gradlew installDebug
通过这两个步骤,你就可以在自己的手机上体验 MNN-TaoAvatar 数字人应用了!赶快来试一试吧。
相关资源以及参考链接:
TaoAvatar Github 下载:https://github.com/alibaba/MNN/blob/master/apps/Android/MnnTaoAvatar/README_CN.md
TaoAvatar 论文:https://arxiv.org/html/2503.17032v1
MNN LLM论文:https://arxiv.org/abs/2506.10443
TaoAvatar模型合集:https://modelscope.cn/collections/TaoAvatar-68d8a46f2e554a
LLM模型:Qwen2.5-1.5B MNN:https://github.com/alibaba/MNN/tree/master/3rd_party/NNR
TTS模型:bert-vits2-MNN:https://modelscope.cn/models/MNN/bert-vits2-MNN
基础TTS模型:Bert-VITS2:https://github.com/fishaudio/Bert-VITS2
声音动作模型:UniTalker-MNN:https://modelscope.cn/models/MNN/UniTalker-MNN
基础声音动作模型:UniTalker:https://github.com/X-niper/UniTalker
神经渲染模型:TaoAvatar-NNR-MNN:https://modelscope.cn/models/MNN/TaoAvatar-NNR-MNN
ASR模型:Sherpa 双语流式识别模型:https://modelscope.cn/models/MNN/sherpa-mnn-streaming-zipformer-bilingual-zh-en-2023-02-20
china3dv live demo滑动可以看到 TaoAvatar:http://china3dv.csig.org.cn/LiveDemo.html


