视频生成模型
阿里万相2.6发布:支持“角色扮演”与多分镜控制,单次视频时长达15秒
12月16日,阿里巴巴宣布推出新一代 万相2.6系列模型,该模型针对专业影视制作和图像创作场景进行了全面升级,并被称为**“全球功能最全的视频生成模型”。 万相2.6已同步上线阿里云百炼和万相官网**。 万相2.6系列最大的亮点在于它是国内首个支持“角色扮演”功能的视频模型,同时支持音画同步、多镜头生成及声音驱动等功能。

Hailuo2.3AI视频生成模型上线Replicate平台,带来逼真物理与电影级特效
中国AI初创公司MiniMax旗下最新视频生成模型Hailuo2.3现已在Replicate平台正式上线,这一升级版工具以其高度逼真的物理模拟和流畅动作捕捉能力,迅速引发AI内容创作领域的关注。 该模型支持文本和图像输入生成高品质视频,标志着AI在动态视觉效果上的又一突破,尤其适用于电影制作、广告和数字娱乐。 Hailuo2.3延续了前代Hailuo02的Noise-Aware Computation Redistribution (NCR)架构,训练效率提升2.5倍,支持高达10秒的原生1080p视频输出。

OpenAI视频生成模型Sora 2上线微软Azure平台:定价每秒0.1美元,进入公共预览阶段
微软于 10 月 17 日宣布,OpenAI开发的新一代视频生成模型Sora2 已在Azure AI Foundry国际版上线,并进入公共预览阶段。 这是该模型首次通过云平台向企业和开发者开放API接口,标志着生成式AI视频工具开始从封闭测试走向商业化应用。 Sora2 是一款多模态视频生成模型,能够处理文本、图像和视频等多种类型的输入数据,并将这些元素组合生成新的视频内容。

阿里巴巴开源视频生成模型通义万相 Wan2.2,首创电影美学控制系统
AI在线 7 月 28 日消息,今晚,阿里开源视频生成模型「通义万相 Wan2.2」,此次共开源文生视频(Wan2.2-T2V-A14B)、图生视频(Wan2.2-I2V-A14B)和统一视频生成(Wan2.2-IT2V-5B)三款模型,其中文生视频模型和图生视频模型均为业界首个使用 MoE 架构的视频生成模型,总参数量为 27B,激活参数 14B;同时,首创电影美学控制系统,光影、色彩、构图、微表情等能力媲美专业电影水平。 开发者可在 GitHub、HuggingFace、魔搭社区下载模型和代码,企业可在阿里云百炼调用模型 API,用户还可在通义万相官网和通义 App 直接体验。 据官方介绍,通义万相 2.2 率先在视频生成扩散模型中引入 MoE 架构,有效解决视频生成处理 Token 过长导致的计算资源消耗大问题。
Karpathy都投的AI实时视频生成模型:直播立即转,无限时长零延迟
大神Karpathy都忍不住投资的AI初创,带来首个实时扩散视频生成! 用扫帚当麦克风,用盒子当混音台,无需昂贵设备就能开一场沉浸式直播。 喜欢游戏类型但不喜欢游戏的画面?
谷歌在全球推行全新 Veo 3 视频生成模型
谷歌宣布正式在全球范围内推出其最新的视频生成模型 Veo3。 此次发布的消息令广大用户期待已久,Veo3现已向超过159个国家的 Gemini 用户开放,提供全新的视频创作体验。 Veo3视频生成模型的特点在于其能够让用户通过简单的文本提示生成最多八秒钟的视频。

百度发布全球首个中文音视频生成模型 MuseSteamer,颠覆创作方式
近日,百度商业研发团队于7月2日宣布推出一款革命性的视频生成模型 “MuseSteamer”,并同时发布了创作平台 “绘想”。 这一创新的技术标志着全球首个实现中文音视频一体化生成的模型正式问世,必将为内容创作领域带来深远的影响。 MuseSteamer 的最大亮点在于其卓越的协同创作能力,能够将画面、音效以及人声台词完美结合,生成高质量的视频内容。

快手可灵 AI 上线 2.1 系列模型:不到 1 分钟生成 5 秒 1080p 视频,更快更便宜
其在标准模式(720p)下生成5s视频仅需20灵感值,高品质模式(1080p)下也只需35灵感值,成本下降65%。

Character.AI 推出 AvatarFX 模型:让静态图片中的人物“开口说话”
Character.AI 近日宣布推出全新视频生成模型 AvatarFX,这一突破性技术能够将静态图片转化为具有真实感的可说话视频角色,赋予图像中的人物动态表情、唇部同步以及自然肢体动作。 AvatarFX 的核心是其最先进的基于扩散模型的动态生成技术。 该技术依托经过精心筛选的数据集进行训练,融合了创新的音频条件化、蒸馏和推理策略,使得用户能够以极高的速度生成高保真、时间一致性强的视频。

Moonvalley完成4300万美元B轮融资,发布创新视频生成模型Marey
2025年4月,视频生成技术公司Moonvalley宣布成功完成4300万美元的B轮融资,此轮融资由11位未具名投资者参与,使得该公司总融资额达到1.13亿美元。 这笔资金将进一步推动Moonvalley在AI视频生成领域的技术创新和市场扩展。 就在披露融资信息的10天前,Moonvalley推出了旗下首款视频生成模型Marey。
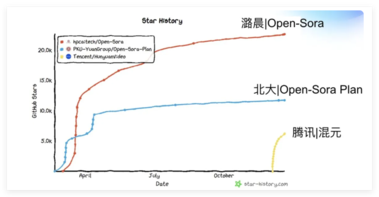
叫板Sora?潞晨科技开源视频大模型Open-Sora 2.0,降本提速
听说过壕无人性的 OpenAI Sora 吧?动辄几百万美元的训练成本,简直就是视频生成界的“劳斯莱斯”。 现在,潞晨科技宣布开源视频生成模型 Open-Sora2.0!仅仅花费了区区20万美元(相当于224张 GPU 的投入),就成功训练出了一个拥有 110亿参数的商业级视频生成大模型。 性能直追“OpenAI Sora ”别看 Open-Sora2.0成本不高,实力可一点都不含糊。

阿里通义万相宣布即将开源视频生成模型WanX 2.1
近日,阿里巴巴宣布视频生成模型WanX2.1将全面开源,同时公布了最新视频效果。 2025年1月,阿里巴巴旗下通义万相团队推出Wanx2.1多模态大模型,凭借其在视频生成领域的突破性进展,荣登VBench评测榜单首位,重新定义了AI驱动的视觉创作标准。 WanX 团队[昨晚宣布即将开源其最新的 WANX2.1视频生成模型。

Seed Research | 视频生成模型最新成果,可仅靠视觉认知世界!现已开源
视频生成实验模型“VideoWorld”由豆包大模型团队与北京交通大学、中国科学技术大学联合提出。 不同于 Sora 、DALL-E 、Midjourney 等主流多模态模型,VideoWorld 在业界首次实现无需依赖语言模型,即可认知世界。 正如李飞飞教授 9 年前 TED 演讲中提到 “幼儿可以不依靠语言理解真实世界”,VideoWorld 仅通过 “视觉信息”,即浏览视频数据,就能让机器掌握推理、规划和决策等复杂能力。

字节联合港大发布新视频模型Goku:可直接生成虚拟数字人视频
近日,香港大学与字节跳动合作研发的基于流动的视频生成模型 Goku 正式发布。 该模型利用先进的生成算法,可以根据文本提示生成高质量的视频内容,极大地丰富了数字艺术的表现形式。 为了展示 Goku 模型的强大功能,研究团队制作了一系列精彩的视频示例,这些示例不仅展示了模型的技术能力,也展现了其在创意表现上的无限潜力。

豆包开源视频生成模型 VideoWorld:首创免语言模型依赖认知世界
不同于 Sora 、DALL-E 、Midjourney 等主流多模态模型,VideoWorld 在业界首次实现无需依赖语言模型,即可认知世界。

AGI-Eval团队:AI视频生成模型年度横评,Sora大饼落地,但国产模型仍然领先!
说到2024年AI圈的热门话题,当然不能错过视频生成模型了! 即使是在12月,国内外视频模型的更新脚步依旧没有放缓。 其中以Sora、可灵AI为代表。
微软开源视频Tokenizer新SOTA!显著优于Cosmos Tokenizer和Open-Sora
Sora、Genie等模型会都用到的Tokenizer,微软下手了——开源了一套全能的Video Tokenizer,名为VidTok。 Sora等视频生成模型工作中,都会利用Tokenizer将原始的高维视频数据(如图像和视频帧)转换为更为紧凑的视觉Token,再以视觉Token为目标训练生成模型。 而最新的VidTok,在连续和离散、不同压缩率等多种设定下,各项指标均显著优于SOTA模型。

视频生成平台 Runway 获得新技能:更改视频比例,图片拥有“电影级”运镜
视频生成 AI 创企 RunwayML 今天推出了“Expand Video”新功能。用户可通过输入文本提示,在原始画面基础上生成额外内容,灵活调整视频比例,该系统能够在扩展画面时保持视觉效果的统一性。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉