大神Karpathy都忍不住投资的AI初创,带来首个实时扩散视频生成!
用扫帚当麦克风,用盒子当混音台,无需昂贵设备就能开一场沉浸式直播。

喜欢游戏类型但不喜欢游戏的画面?简单,实时给它改个风格是不是就舒服多了~

以上,就是AI初创公司Decart的最新视频模型MirageLSD的演示效果,这是首个实现零延迟无限实时视频生成的AI模型。
只要你有想象力,Mirage就能实时生成视频流,为你打造专属的魔法世界~
输入支持直播、游戏、视频通话、相机拍摄、点播等多种形式,可以说是能转尽转了。
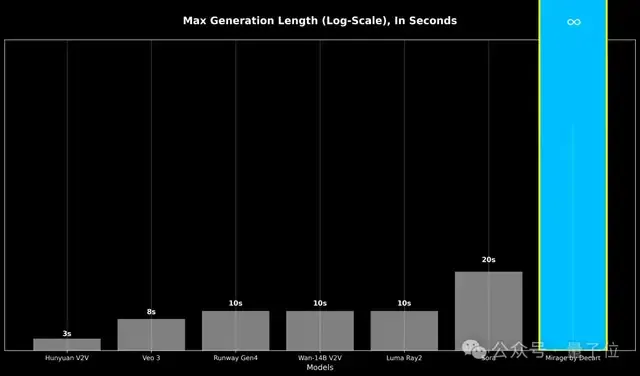
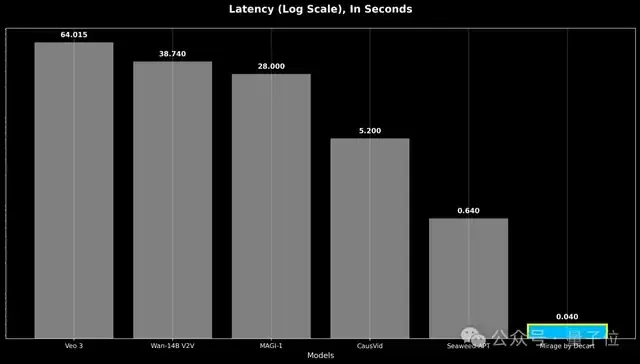
主要是Mirage和其他等待时间很久但只能生成5-10秒视频的模型不一样,它没有时长限制,延迟还降到了40毫秒以下,说是零延迟也不为过吧。
响应速度比之前的模型快16倍,实现了每秒24帧的实时视频生成,还允许在视频生成过程中进行持续的提示、转换和编辑。
做到了“你随时想,我随时转”!
于是,AI大神卡帕西也出来力挺:实时!
同时他还透露自己也是Decart的天使投资人(非常小)。

接下来让我们看看Mirage是如何做到的。
攻克了传统自回归视频模型中“误差累积”的核心难题
MirageLSD采用Decart自定义的实时流扩散模型Live-Stream Diffusion(LSD),LSD能够在逐帧生成内容的同时保持时间连贯性。
在视频生成过程中,由于自回归模型每一帧都依赖于前一帧,一个位置偏移的阴影或者一种纹理错误的细节这些瑕疵会随着时间的推移而不断累积,这种误差积累会使模型逐渐偏离训练。
当前的视频模型在生成超过20-30秒的内容时,会因为误差累积而导致严重质量下降,所以一些模型只能生成固定长度的短视频。
MirageLSD能够实现无限生成的核心就在于解决了传统自回归视频模型中“误差累积”这一关键瓶颈。
它采用逐帧的因果自回归结构处理数据,每帧生成仅依赖先前已生成的帧和用户提示,而非完整视频序列,这种模式为连续生成无限时长视频奠定了基础。
同时依托Diffusion Forcing技术,让模型在训练中学会独立对单帧去噪,无需依赖完整视频上下文,保证了逐帧生成的连贯性。

针对传统自回归模型中微小误差随时间叠加导致画面失真的问题,MirageLSD通过历史增强策略解决:训练时向输入的历史帧中主动添加模拟模型可能生成的伪影(如噪声、畸变),使模型学会预判并纠正这些缺陷。
此外,在推理阶段明确告知模型“历史帧可能不准确”,可以让它保持对误差的警惕性,持续调用训练中学习的纠正能力。
并且之前的模型都需要几分钟的处理时间才能生成几秒钟的内容,以分块的方式生成视频还引入了不可避免的延迟,从而不能实现实时互动。
MirageLSD采用改进的Transformer模型架构,搭配专门设计的视觉编码器、改进的位置编码以及针对长时间交互序列优化的结构,来快速处理输入和生成输出。
同时,对生成部分的扩散模型部分应用先进的蒸馏策略,在保证生成质量的前提下有效提升运行速度,借助KV缓存技术支持的长上下文窗口,让模型能记住之前的状态信息,避免因频繁处理大量历史数据导致延迟。
在核心集成帧级提示词处理机制,可即时解析玩家的键盘指令和自然语言提示,快速转化为相应操作。
动态输入系统则能以超低延迟处理玩家输入,无论是生成新元素还是改变环境都能迅速响应。
此外,视觉更新通过全双工通信通道流回,输入与输出并行处理,消除了数据传输和处理中的延迟;采用“垂直训练”流程让模型深入学习相关规则与模式,减少了生成过程中的计算开销和错误尝试,进一步间接提升了实时性能。
实现了“抖一抖衣服就能换装”、“棍子变发光武器”之类的操作。

MirageLSD由位于美国加州的初创公司Decart打造,该公司成立于2023年。
2024年,Decart推出了自己的第一款模型Oasis,这是首个实时生成式AI开放世界模型。

Oasis支持实时交互,能实现每秒20帧零延迟的生成效率。
由此看来,MirageLSD如今每秒24帧的效率也有所提升。
团队还表示将定期发布MirageLSD的升级模型和新增功能,包括面部一致性、语音控制和精确物体控制等,逐步提升用户体验。
体验链接:https://mirage.decart.ai/
参考链接: [1]https://x.com/DecartAI/status/1945947692871692667 [2]https://x.com/karpathy/status/1945979830740435186


