评估

全面评估多模态模型视频OCR能力,Gemini 准确率仅73.7%
多模态大模型(MLLM)在静态图像上已经展现出卓越的 OCR 能力,能准确识别和理解图像中的文字内容。 然而,当应用场景从静态图像拓展至动态视频时,即便是当前最先进的模型也面临着严峻的挑战。 MME-VideoOCR 致力于系统评估并推动MLLM在视频OCR中的感知、理解和推理能力。

多模态模型具备“物理推理能力”了吗?新基准揭示:表现最好的GPT-o4 mini也远不及人类!
表现最好的GPT-o4 mini,物理推理能力也远不及人类! 就在最近,来自香港大学、密歇根大学等机构的研究人员补齐了现有评估体系中的一处关键空白——评估多模态模型是否具备“物理推理能力”。 物理推理,即模型在面对真实或拟真的物理情境时,能否综合利用视觉信息、物理常识、数学建模进行判断和预测,被认为是通向具身智能的关键能力。

红杉中国推出全新 AI 基准测试工具,助力智能体评估新标准
随着人工智能技术的迅速发展,尤其是大型模型的不断进步,基准测试在评估 AI 能力时面临着前所未有的挑战。 为了应对这一现状,红杉中国于5月26日宣布推出一款全新的 AI 基准测试工具 ——xbench。 这款工具不仅是针对 AI 模型能力的评估,还引入了动态更新机制,确保测试的有效性和公正性。
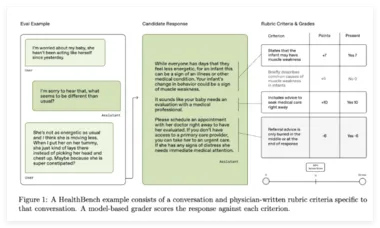
OpenAI 发布 HealthBench:评估大型语言模型在医疗领域表现的新标准
近日,OpenAI 发布了一款名为 HealthBench 的开源评估框架,旨在测量大型语言模型(LLMs)在真实医疗场景中的表现和安全性。 此框架的开发得到了来自60个国家和26个医学专业的262名医生的支持,旨在弥补现有评估标准的不足,特别是在真实应用、专家验证和诊断覆盖方面。 现有的医疗 AI 评估标准通常依赖于狭窄、结构化的形式,如多项选择考试。

首个智能文档处理基准发布:Gemini领跑但短板待补,多模态AI面临现实挑战
5月11日,智能文档处理领域迎来重大进展——首个针对视觉-语言模型的统一基准测试"IDP Leaderboard"正式推出。 该基准通过16个数据集、9229份文档,全面评估了当前主流模型在OCR、关键信息提取、视觉问答、表格提取、分类和长文档处理六大核心任务上的表现,为行业发展提供了可量化参考。 测试结果显示,Gemini2.5Flash在综合实力上力压群雄,但却在OCR和分类任务中出现意外"滑铁卢",表现甚至不如上一代的Gemini2.0Flash,分别下降了1.84%和0.05%。

UGMathBench动态基准测试数据集发布 可评估语言模型数学推理能力
近日,魔搭ModelScope社区宣布发布一项名为UGMathBench的动态基准测试数据集,旨在全面评估语言模型在本科数学广泛科目中的数学推理能力。 这一数据集的问世,填补了当前在本科数学领域评估语言模型推理能力的空白,并为研究者提供了更为丰富和具有挑战性的测试平台。 随着人工智能技术的飞速发展,自然语言模型在自动翻译、智能客服、医疗、金融等多个领域展现出巨大潜力。
Agent-as-a-Judge:用AI智能体来评估AI智能体的工作 节省97% 的时间
在当前人工智能的迅猛发展中,评估智能代理的能力成为了一个重要课题。 为此,Agent-as-a-Judge(代理法官)项目应运而生,它不仅是一个技术库,更是一种全新的评估理念。 该项目旨在通过智能代理对其他代理的工作进行评判,以生成高质量的数据集,并推动跨领域的研究。

科学家构建多模态LLM框架,进行3D脑CT放射学报告生成
编辑 | 烂菜叶多模态大型语言模型 (MLLM) 已经改变了现代医疗保健的格局,其中自动放射学报告生成 (RRG) 正在成为一种尖端应用。 虽然基于 2D MLLM 的 RRG 已经得到充分认可,但其在 3D 医学图像中的实用性仍未得到充分开发。 在这方面,台北荣民总医院(Taipei Veterans General Hospital)、台湾阳明交通大学(National Yang Ming Chiao Tung University)以及美国加州大学的研究人员整理了 3D-BrainCT 数据集(18,885 个文本扫描对)并开发了 BrainGPT,这是一种专为 3D CT RRG 设计的临床视觉指令调整 (CVIT) 模型。

Anthropic新研究:用统计思维评估大模型
目前,评估大模型的方法就是比在基准测试中的数值,在于突出SOTA结果,并未充分考虑统计显著性。 例如,在对不同模型进行评估时,若仅依据表面的得分高低判断优劣,而不考虑数据的不确定性和变异性,可能会得出不准确的结论。 所以,Anthropic提出了将严谨的统计思维引入大模型评估领域。

智能体模拟《西部世界》一样的社会,复旦大学等出了篇系统综述
AIxiv专栏是AI在线发布学术、技术内容的栏目。 过去数年,AI在线AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。 如果您有优秀的工作想要分享,欢迎投稿或者联系报道。

上交大o1复现新突破:蒸馏超越原版,警示AI研发"捷径陷阱"
AIxiv专栏是AI在线发布学术、技术内容的栏目。 过去数年,AI在线AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。 如果您有优秀的工作想要分享,欢迎投稿或者联系报道。

中国科大、科大讯飞团队开发ChemEval:化学大模型多层次多维度能力评估的新基准
编辑 | ScienceAI近日,认知智能全国重点实验室、中国科学技术大学陈恩红教授团队,科大讯飞研究院 AI for Science 团队发布了论文《ChemEval: A Comprehensive Multi-Level Chemical Evaluation for Large Language Models》,介绍了新研发的一个面向化学领域大模型能力的多层次多维度评估框架 ChemEval。论文链接: : (NLP)的领域中,大语言模型(LLMs)已经成为推动语言理解与生成能力不断进步的强大引擎。随着这些

OpenAI 发布 MMMLU 数据集:更广、更深评估 AI 模型,支持简体中文
科技媒体 marktechpost 昨日(9 月 23 日)发布博文,报道称 OpenAI 在 Hugging Face 上发布了多语言大规模多任务语言理解(MMMLU)数据集。背景随着语言模型日益强大,评估其在不同语言、认知和文化背景下的能力已成为当务之急。OpenAI 决定推出 MMMLU 数据集,通过提供强大的多语言和多任务数据集,来评估大型语言模型(LLMs)在各种任务中的性能,从而应对这一挑战。MMMLU 数据集简介MMMLU 数据集包含一系列问题,涵盖各种主题、学科领域和语言。其结构旨在评估模型在不同研

IDC 首次发布移动端 AI 大模型应用报告:百度文心一言发展较全面、抖音豆包用户活跃度表现出色
市场调查机构 IDC 昨日(9 月 2 日)首次发布了移动端大模型应用市场竞争力分析研究报告,评估了市场上 8 款热门 Chatbot 聊天机器人模型,并分析、洞察了相关 AI 模型的性能和特征。AI在线附上本次评估的 8 款 Chatbot App 如下(按照公司拼音首字母顺序排列):kimi 智能助手豆包海螺 AI天工通义文心一言讯飞星火智谱清言评估方案该评估模型初版主要聚焦于利用现有 App 相关的数据来剖析市场现状,揭示 Chatbot 在实际应用场景中的表现与局限。具体指标包括:市场影响力、用户活跃度、用

OpenAI 推出 SWE-bench Verified 基准,更准确评估 AI 模型代码生成表现
感谢OpenAI 公司于 8 月 13 日发布新闻稿,宣布推出 SWE-bench Verified 代码生成评估基准,解决了此前的局限性问题,能够更准确地评估人工智能模型在软件工程任务中的表现。SWE-benchAI在线注:SWE-Bench 是一个用于评估 LLM 解决 GitHub 上真实软件问题能力的基准测试数据集。它收集了来自 12 个流行的 Python 仓库的 2294 个 Issue-Pull Request 对。在测试时,LLM 会拿到一个代码库和 issue 描述,然后生成一个补丁来解决 iss

OpenAI 发布 GPT-4o 模型卡:概述 AI 安全和风险缓解措施
OpenAI 公司于 8 月 8 日发布报告,概述了 GPT-4o 模型的系统卡(System Card),介绍了包括外部红队(模拟敌人攻击)、准备框架(Preparedness Framework)在内的诸多细节。OpenAI 表示 GPT-4o 模型的核心就是准备框架(Preparedness Framework),这是一种评估和降低人工智能系统相关风险的系统方法。AI在线从报道中获悉,该框架主要用于识别网络安全、生物威胁、说服和模型自主性等领域的潜在危险。除了针对 GPT-4 和 GPT-4V 进行的安全评估

Meta 推出“自学评估器”:无需人工注释改善评估,性能超 GPT-4 等常用 AI 大语言模型评审
Meta 公司为了缓解自然语言处理(NLP)技术依赖人类注释评估 AI 模型的问题,最新推出了“自学评估器”(Self-Taught Evaluator),利用合成数据训练 AI。NPU 技术挑战NPU 技术的发展,推动大型语言模型(LLMs)高精度地执行复杂的语言相关任务,实现更自然的人机交互。不过当前 NPU 技术面临的一个重要挑战,就是评估模型严重依赖人工注释。人工生成的数据对于训练和验证模型至关重要,但收集这些数据既费钱又费时。而且随着模型的改进,以前收集的注释可能需要更新,从而降低了它们在评估新模型时的效

研究:AI 测谎能力比人类更强,但会对社会交往造成影响
德国维尔茨堡大学当地时间 12 日公布的最新研究显示,在假新闻、政治家的可疑言论和被操纵的视频日益泛滥的时代,人工智能在测谎方面的表现比人类更佳。图源 Pixabay来自维尔茨堡、杜伊斯堡、柏林和图卢兹的研究人员探讨了 AI 在检测谎言方面的有效性及其对人类行为的影响。这项研究的主要发现可以总结如下:在基于文本的谎言检测中,AI 的准确性优于人类。没有 AI 的支持,人们不愿指责他人撒谎。在 AI 的支持下,人们更有可能表达对遇到谎言的怀疑。只有大约三分之一的研究参与者会利用向 AI 询问评估的机会。然而,大多数人
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI绘画
大模型
AI新词
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
智能体
技术
Gemini
英伟达
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
代码
AI for Science
苹果
算法
腾讯
Agent
Claude
芯片
Stable Diffusion
具身智能
蛋白质
xAI
开发者
人形机器人
生成式
神经网络
机器学习
AI视频
3D
RAG
大语言模型
Sora
百度
字节跳动
研究
GPU
生成
工具
华为
AGI
计算
大型语言模型
AI设计
生成式AI
搜索
视频生成
亚马逊
AI模型
DeepMind
特斯拉
场景
深度学习
Transformer
架构
Copilot
MCP
编程
视觉