随着人工智能技术的迅速发展,尤其是大型模型的不断进步,基准测试在评估 AI 能力时面临着前所未有的挑战。为了应对这一现状,红杉中国于5月26日宣布推出一款全新的 AI 基准测试工具 ——xbench。这款工具不仅是针对 AI 模型能力的评估,还引入了动态更新机制,确保测试的有效性和公正性。
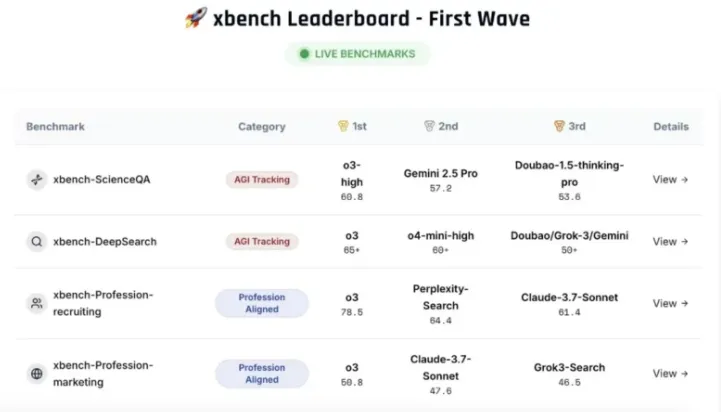
xbench 的推出源于红杉中国在2022年 ChatGPT 发布后对 AGI(通用人工智能)进程的关注。随着智能体(Agent)在各个领域的广泛应用,传统的静态基准测试方法显得捉襟见肘,难以准确反映模型的实际能力。为此,xbench 采用了双轨评估体系:一方面通过构建多维度的测评数据集,追踪模型的理论能力上限;另一方面则聚焦于智能体的实际落地价值,从而实现对 AI 技术的全面评估。
在具体评估方法上,xbench 采用了长青评估机制,即评估工具会动态更新,以适应技术的快速迭代。这种方法不仅提高了测试的可靠性,也避免了题目泄露等问题,确保了评估的公正性。以往,许多行业内的模型往往因为题库泄露而被质疑 “刷榜”,而 xbench 的设计初衷就是为了消除这种隐患。
除了基础的评估体系,红杉中国还在 xbench 中加入了垂直领域智能体的评测方法论,特别是在招聘与营销领域的应用。随着 AI 智能体的不断发展,深度搜索、信息收集和推理分析等能力成为通向 AGI 的关键。为了有效评估这些能力,xbench 将特别关注具有思维链的多模态模型在生成商用视频方面的表现,以及在动态更新的应用中,GUI 智能体的可信度等问题。
xbench 的推出不仅为 AI 智能体的评估建立了新标准,也为行业提供了一套可持续发展的评估工具,以应对未来 AI 技术的不断演进。