模型

宇树机器人侧空翻惊呆网友:“我**想要一个!”
这下特效视频和机器人实拍真的傻傻分不清楚了…前几天机器人卷的还是前后空翻呢,宇树现在连侧空翻都曝出来了。 干拔起跳,落地都不带晃的:以上动作,由宇树的Unitree G1呈现,就是身高1米3,售价9.9万起的那个型号。 宇树官方是酱婶描述的:这是世界上第一款征服站立侧空翻的人形机器人。

OpenAI史上最贵模型来了!比DeepSeek贵270倍,100万输出token 600美元
比DeepSeek-R1贵270倍,OpenAI史上最贵模型来了! 就在刚刚,OpenAI上线了推理模型o1-pro的API。 本来大家还挺高兴,结果一看到价格,悬着的心终于死了。

波士顿动力Atlas逆天进化!这次用上了「强化学习+动捕」,人类动作直接复刻,背后还有个AI机构
说起波士顿动力,大家肯定不陌生,他们家的Atlas机器人,也是人形机器人界的“顶流”。 刚刚,Atlas人形机器人又秀了一波新操作,简直太惊人了,动作无限接近人类,大家直接看视频感受一下波士顿动力官方发推表示,Atlas这次展示的是用动作捕捉服开发的强化学习策略。 啥意思呢?

AI预判了你的预判!人大高瓴团队发布TTR,教会AI一眼看穿你的下一步
本文作者均来自中国人民大学高瓴人工智能学院。 其中,第一作者谭文辉是人大高瓴博士生(导师:宋睿华长聘副教授),他的研究兴趣主要在多模态与具身智能。 本文通讯作者为宋睿华长聘副教授,她的团队 AIMind 主要研究方向为多模态感知、生成与交互。

刚刚,OpenAI推出最贵o1-pro API!千倍于DeepSeek
刚刚,OpenAI 在其开发者 API 中推出了 o1 推理模型的一个更强大版本,即 o1-pro。 据 OpenAI 称,o1-pro 使用比 o1 更多的计算资源来提供更好的响应。 该功能仅对特定开发者开放(Tier 1–5 开发者),支持视觉、函数调用、结构化输出,并与响应和 Batch API 兼容。

揭秘老黄演讲中关键技术:PD分离!UCSD华人团队力作,LLM吞吐量跃升4倍
现在,PD分离已经成为兵家必争之地。 前有Mooncake/DeepSeek等公司采用这种技术来优化大模型的推理服务,后有Nvidia/PyTorch基于该技术孵化下一代LLM服务系统。 甚至最近,黄仁勋也在2025 GTC的舞台上提到了PD分离(Prefill-Decode Disaggregation)技术,进一步证明了这一技术获得的广泛关注。
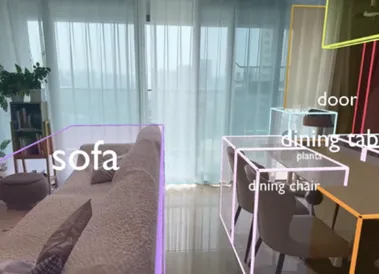
1段视频=亿万虚拟场景,当真实世界秒变机器人训练场
3月19日,群核科技在GTC2025全球大会上宣布开源空间理解模型SpatialLM,这是一个基于大语言模型的3D场景语义生成框架。 它突破了传统大语言模型对物理世界几何与空间关系的理解局限,赋予机器类似人类的空间认知和解析能力。 这相当于为具身智能领域提供了一个基础的空间理解训练框架,企业可以针对特定场景对SpatialLM模型微调,降低具身智能训练门槛。

无需百卡集群!港科等开源LightGen: 极低成本文生图方案媲美SOTA模型
LightGen 主要作者来自香港科技大学和 Everlyn AI, 第一作者为香港科技大学准博士生吴显峰,主要研究方向为生成式人工智能和 AI4Science。 通讯作者为香港科技大学助理教授 Harry Yang 和中佛罗里达副教授 Sernam Lim。 共同一作有香港科技大学访问学生白亚靖,香港科技大学博士生郑皓泽,Everlyn AI 实习生陈浩东,香港科技大学博士生刘业鑫。

世界模型在机器人任务规划中的全新范式:NUS邵林团队提出通用机器人规划模型FLIP
本文的作者均来自新加坡国立大学 LinS Lab。 本文第一作者为新加坡国立大学博士生高崇凯,其余作者为北京大学实习生张浩卓,新加坡国立大学博士生徐志轩,新加坡国立大学硕士生蔡哲豪。 本文的通讯作者为新加坡国立大学助理教授邵林。

Django创造者Simon Willison分享:我如何使用LLM帮我写代码
近段时间,著名 AI 科学家 Andrej Karpathy 提出的氛围编程(vibe coding)是 AI 领域的一大热门话题。 简单来说,氛围编程就是鼓励开发者忘掉代码,进入开发的氛围之中。 更简单地讲,就是向 LLM 提出需求,然后「全部接受」即可。

老黄发布新核弹B300,英伟达:B200已破DeepSeek-R1推理世界纪录
皮衣老黄,带着最强AI芯片GB300闪亮登场“AI超级碗”GTC,燃爆全场! 性能方面,和去年发布的GB200相比,推理性能是其1.5倍。 据悉,GB300将在今年的下半年出货。

AI真·抢饭碗?美国码农就业跌至1980年以来最低,重回「吃豆人」时代
美国程序员的就业人数已跌至1980年以来的最低水平!那可是互联网存在之前的好多年了。 1980年,「吃豆人」(Pac-Man)游戏刚刚风靡全球。 亚马逊还没开始在线上卖货,苹果还没有出售它的iPhone。

全球首个工业界多模态推理模型开源!38B硬刚DeepSeek-R1,训练秘籍全公开
刚刚,昆仑万维正式开源了全球首个工业界多模态推理模型Skywork R1V(以下简称「R1V」)! R1V高效地将DeepSeek-R1这种强大的文本推理能力无缝scaling到了视觉模态,实现了多模态领域的领先表现,并以开源方式推动了技术进步。 由此,多模态推理的新时代即将开启。

多模态也做到了强推理!工业界首个开源的R1V,让视觉思考进入o1时代
DeepSeek-R1 问世后,我们一直在期待能「强推理、慢思考」的大模型进化成多模态模式。 如果能在视觉等各领域复刻强化学习(RL)在文本上的突破,AI 应用势必会将更多领域推入新的范式。 毫无疑问,这也是众多科技公司正在探索的方向。

o1/o3后训练负责人离职创业,奥特曼把OpenAI玩成另一个YC孵化器了
OpenAI高管离职潮继续:CTO Mira卷着一票人才集体出走之后,刚刚,后训练研究副总裁William Fedus也官宣离职创业了。 他在不到半年前,也就是去年10月刚刚晋升——没错,彼时OpenAI的上一任后训练负责人Barret Zoph等人刚刚跟着CTO Mira跑路。 在那一拨人才离职潮中,William (Liam) Fedus是顶上重任的主要角色之一。

ChatGPT创始成员、后训练负责人官宣离职!自立门户并将获OpenAI投资
OpenAI 又有重量级员工出走! 这次是后训练负责人、研究副总裁 William Fedus。 今天凌晨,Fedus 在 X 上发表了一则公开离职信,讲述了他离职的原因以及今后的去向。

新注意力让大模型上下文内存占用砍半!精度不减还能加速2倍
大模型同样的上下文窗口,只需一半内存就能实现,而且精度无损? 前苹果ASIC架构师Nils Graef,和一名UC伯克利在读本科生一起提出了新的注意力机制Slim Attention。 它以标准多头注意力(MHA)为基准,对其中的value缓存处理过程进行了调整,实现了更少的内存占用。

8张GPU训出近SOTA模型,超低成本图像生成预训练方案开源
超低成本图像生成预训练方案来了——仅需8张GPU训练,就能实现近SOTA的高质量图像生成效果。 划重点:开源。 模型名为LightGen,由港科大Harry Yang团队联合Everlyn AI等机构打造,借助知识蒸馏(KD)和直接偏好优化(DPO)策略,有效压缩了大规模图像生成模型的训练流程。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉