基准测试

专家揭示数百项 AI 安全测试存在严重缺陷
根据最新报道,来自英国政府 AI 安全研究所和多所知名大学的计算机科学家们发现,当前用于评估新一代人工智能(AI)模型安全性和有效性的测试存在广泛的缺陷。 这项研究分析了超过440个基准测试,发现几乎所有的测试在某个方面都有弱点,这些弱点可能会影响到最终结论的有效性。 图源备注:图片由AI生成研究的主要作者、牛津互联网研究所的研究员安德鲁・比恩(Andrew Bean)表示,这些基准测试是检查新发布 AI 模型安全性和是否符合人类利益的重要工具。

AI 安全性与有效性测试存在严重缺陷,引发专家关注
近日,来自英国政府 AI 安全研究所的计算机科学家及斯坦福大学、加州大学伯克利分校和牛津大学的专家们,对超过440个用于评估新人工智能模型安全性和有效性的基准进行了深入研究。 他们发现几乎所有测试在某一领域存在缺陷,这些缺陷可能会 “削弱结果声明的有效性”,并且一些测试的评分结果可能 “无关紧要甚至误导”。 图源备注:图片由AI生成随着各大科技公司不断推出新 AI,公众对 AI 的安全性和有效性日益担忧。

7个AI玩狼人杀,GPT-5获断崖式MVP,Kimi手段激进
不圆 发自 凹非寺. 量子位 | 公众号 QbitAI一群AI玩狼人杀,GPT-5断崖式领先,胜率达到了惊人的96.7%。 OpenAI的总裁格雷格·布罗克曼转发了这样的一个基准测试:让7个强大的LLMs,包括开源和闭源,玩了210场完整的狼人杀。
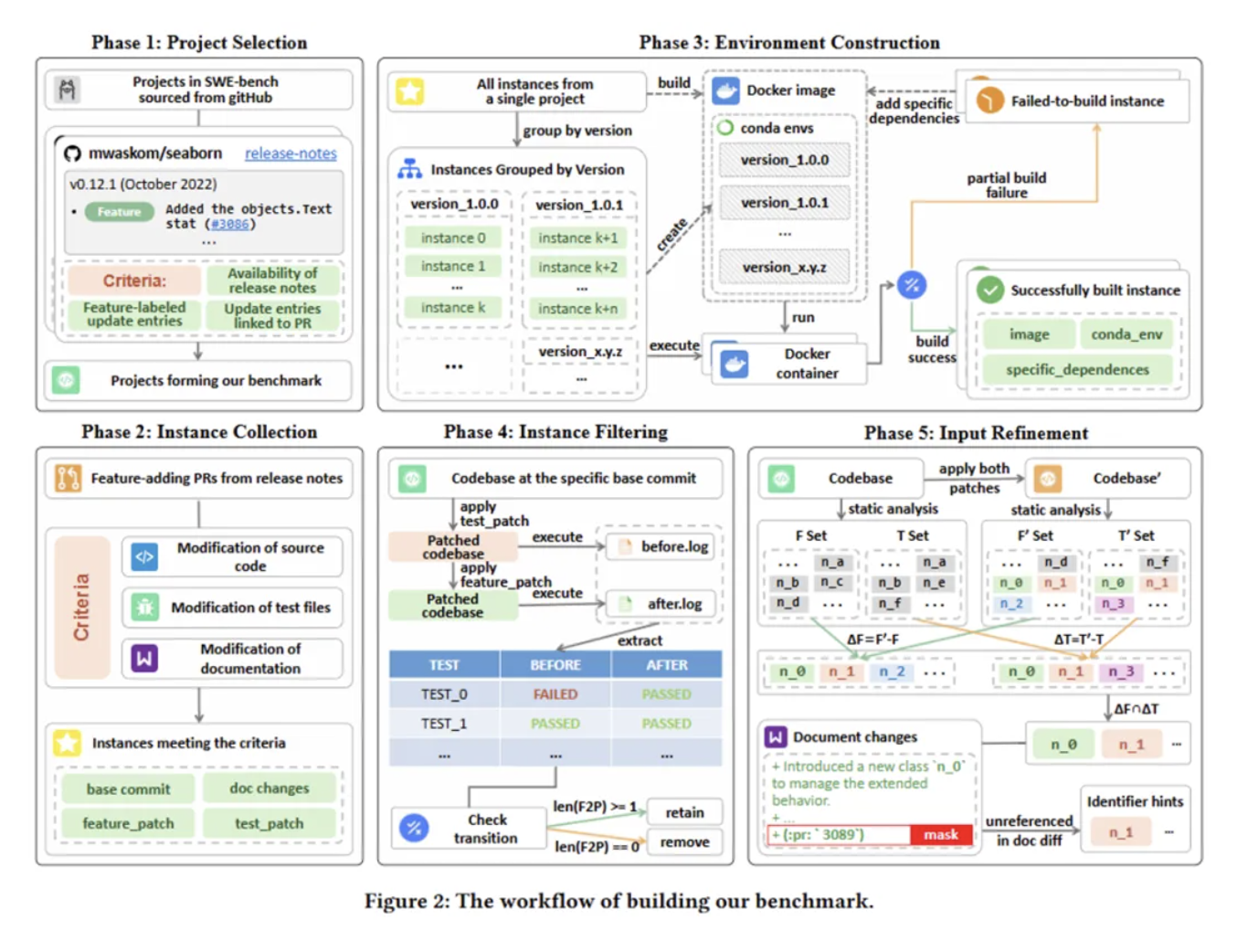
从Debugger到Developer : 低代码时代新基准NoCode-bench,SWE-Bench作者力荐
论文的主要作者为浙江大学研究员刘忠鑫及其研究生邓乐、蒋中豪,其他作者包括香港科技大学研究助理教授曹嘉伦、德国 CISPA 和斯图加特大学教授 Michael Pradel。 刘忠鑫的主要研究领域为代码智能,包括代码生成与变更、代码表示学习等;曹嘉伦的主要研究领域包括 AI&SE、人工智能测试、形式化验证等。 当前,大型语言模型(LLM)在软件工程领域的应用日新月异,尤其是在自动修复 Bug 方面,以 SWE-bench 为代表的基准测试展示了 AI 惊人的潜力。

OpenAI 推出 SWE-Lancer 基准测试:评估真实世界自由软件工程工作的模型性能
在软件工程领域,随着挑战的不断演变,传统的基准测试方法显得力不从心。 自由职业的软件工程工作复杂多变,远不止是孤立的编码任务。 自由职业工程师需要处理整个代码库,集成多种系统,并满足复杂的客户需求。

“人类终极考试”基准测试发布:顶级 AI 系统表现惨淡,回答准确率均未超 10%
非营利组织“人工智能安全中心”(CAIS)与提供数据标注和 AI 开发服务的公司 Scale AI 联合推出了一个名为“人类终极考试”(Humanity's Last Exam)的新型基准测试,旨在评估前沿 AI 系统的综合能力。这一测试因其极高的难度引起关注。

MLCommons 发布 PC AI 基准测试 MLPerf Client 首个公开版本 0.5
MLPerf Client 基准测试的诞生是 AMD、英特尔、微软、英伟达、高通和顶级 PC OEM 等利益相关方的合作成果。

UL Solutions 推出 AI 文本生成基准测试,支持英伟达、AMD、英特尔三家显卡
该基准测试目前包括 4 种参数规模不一的模型,分别为 Phi-3.5-mini、Mistral-7B、Llama-3.1-8B 和 Llama-2-13B。

14 项任务测下来,GPT4V、Gemini等多模态大模型竟都没什么视觉感知能力?
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:[email protected];[email protected]年,以 GPT-4V、Gemini、Claude、LLaVA 为代表的多模态大模型(Multimodal LLMs)已经在文本和图像等多模态内容处理方面表现出了空前的能力
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉