Guard
ECCV 2024|牛津大学&港科提出毫秒级文生图安全检测框架Latent Guard
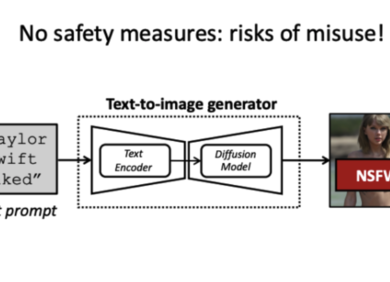
最近的文本到图像生成器由文本编码器和扩散模型组成。 如果在没有适当安全措施的情况下部署,它们会产生滥用风险(左图)。 我们提出了潜在保护方法(右图),这是一种旨在阻止恶意输入提示的安全方法。

攻击成功率从 3% 到接近 100%,利用空格键可绕过 Meta AI 模型安全系统
Meta 公司上周在发布 Llama 3.1 AI 模型的同时,还发布了 Prompt-Guard-86M 模型,主要帮助开发人员检测并响应提示词注入和越狱输入。AI在线在这里简要补充下背景知识:提示词注入(prompt injection):将恶意或非预期内容添加到提示中,以劫持语言模型的输出。提示泄露和越狱实际上是这种攻击的子集;提示词越狱(prompt jailbreaks):绕过安全和审查功能。不过根据科技媒体 theregister 报道,这个防止 AI 提示词注入和越狱的模型,本身也存在漏洞,用户只需要
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉