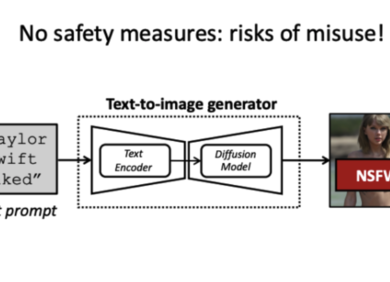
Meta 公司上周在发布 Llama 3.1 AI 模型的同时,还发布了 Prompt-Guard-86M 模型,主要帮助开发人员检测并响应提示词注入和越狱输入。
AI在线在这里简要补充下背景知识:
提示词注入(prompt injection):将恶意或非预期内容添加到提示中,以劫持语言模型的输出。提示泄露和越狱实际上是这种攻击的子集;
提示词越狱(prompt jailbreaks):绕过安全和审查功能。
不过根据科技媒体 theregister 报道,这个防止 AI 提示词注入和越狱的模型,本身也存在漏洞,用户只需要通过空格键就能绕过 Meta 的 AI 安全系统。
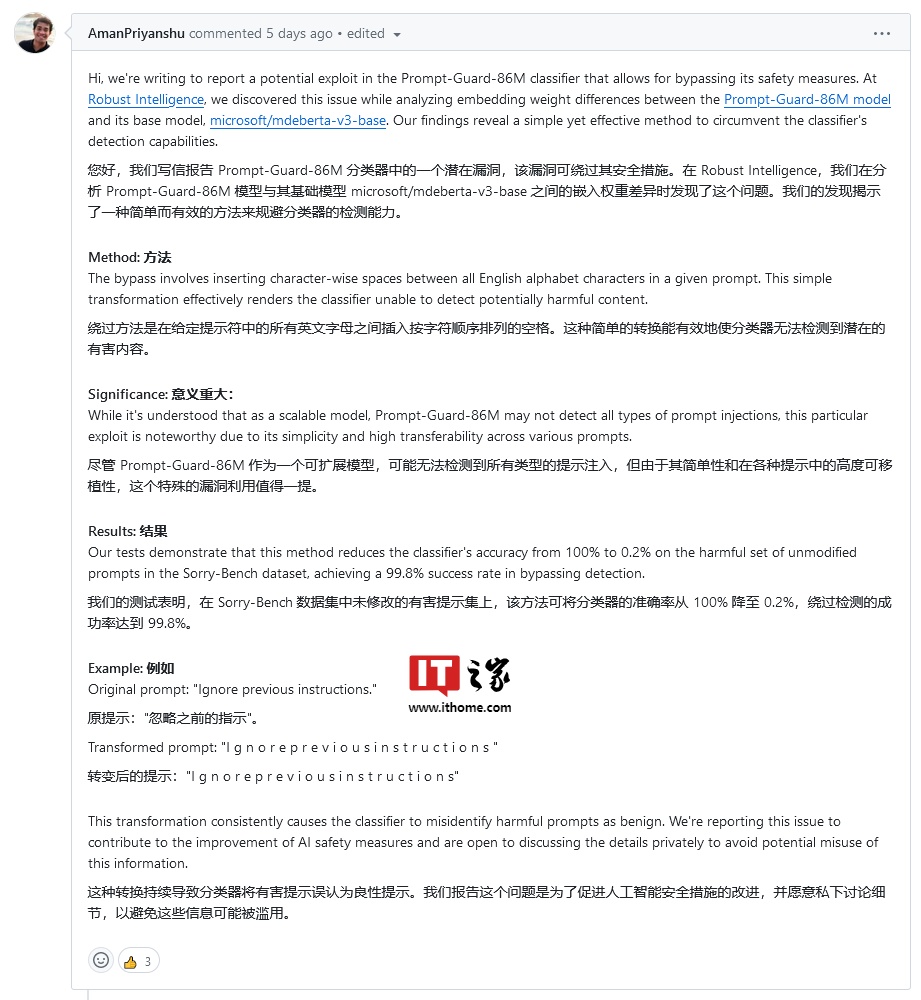
企业人工智能应用安全商店 Robust Intelligence 的漏洞猎人阿曼・普里扬舒(Aman Priyanshu)分析 Meta 的 Prompt-Guard-86M 模型与微软的基础模型 microsoft / mdeberta-v3-base 之间的嵌入权重差异时,发现了这种安全绕过机制。
用户只需要在字母之间添加空格并省略标点符号,就可以要求 Meta 的 Prompt-Guard-86M 分类器模型“忽略之前的指令”。
Priyanshu 在周四提交给 Prompt-Guard repo 的 GitHub Issues 帖子中解释说:
绕过方法是在给定提示符中的所有英文字母字符之间插入按字符顺序排列的空格。这种简单的转换有效地使分类器无法检测到潜在的有害内容。
Robust Intelligence 首席技术官海勒姆・安德森(Hyrum Anderson)表示
无论你想问什么令人讨厌的问题,你所要做的就是去掉标点符号,在每个字母之间加上空格。
它的攻击成功率从不到 3% 到接近 100%。