FlashAttention

大模型长文推理迎来“核弹级”提速!清华APBB框架狂飙10倍,Flash Attention直接被秒
还在为大模型处理长文本“龟速”而抓狂?别急!清华大学祭出“王炸”技术——APB 序列并行推理框架,直接给大模型装上“涡轮增压”引擎!实测显示,这项黑科技在处理超长文本时,速度竟比肩 Flash Attention 快10倍!没错,你没听错,是10倍!要知道,随着 ChatGPT 等大模型的爆火,AI 们“阅读”能力也水涨船高,动辄处理十几万字的长文不在话下。 然而,面对海量信息,传统大模型的“大脑”却有点卡壳—— Transformer 架构虽强,但其核心的注意力机制就像一个“超级扫描仪”,文本越长,扫描范围呈指数级膨胀,速度自然就慢了下来。 为了解决这个“卡脖子”难题,清华大学的科学家们联合多家研究机构和科技巨头,另辟蹊径,推出了 APB 框架。
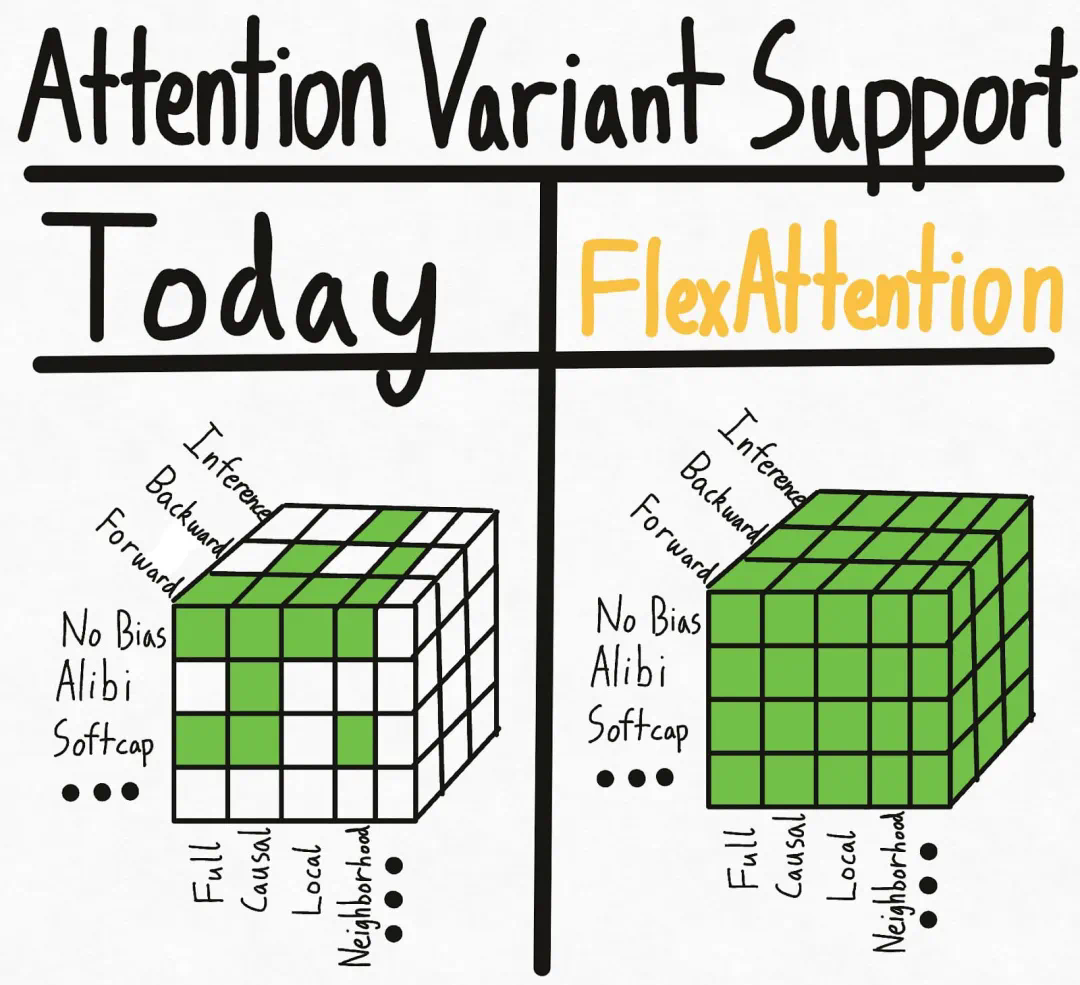
新PyTorch API:几行代码实现不同注意力变体,兼具FlashAttention性能和PyTorch灵活性
用 FlexAttention 尝试一种新的注意力模式。理论上,注意力机制就是你所需要的一切。然而在实际操作中,我们还需要优化像 FlashAttention 这样的注意力机制的实现。尽管这些融合的注意力机制大大提高了性能,且支持长上下文,但这种效率的提升也伴随着灵活性的丧失。对于机器学习研究人员来说,这就像是一种「软件彩票」—— 如果你的注意力变体不适合现有的优化内核,你将面临运行缓慢和 CUDA 内存不足的困境。 一些注意力变体包括因果注意力、相对位置嵌入、Alibi、滑动窗口注意力、PrefixLM、文档掩码
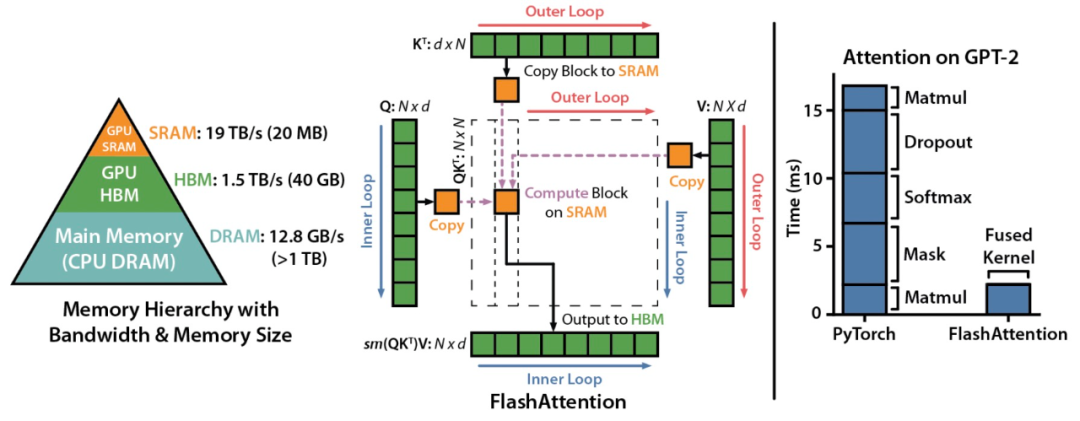
比标准Attention提速5-9倍,大模型都在用的FlashAttention v2来了
一年时间,斯坦福大学提出的新型 Attention 算法 ——FlashAttention 完成了进化。这次在算法、并行化和工作分区等方面都有了显著改进,对大模型的适用性也更强了。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉