大模型

腾讯混元大模型核心论文曝光:Scaling law、MoE、合成数据以及更多
随着 ChatGPT 的横空出世,大语言模型能力开始在各项领域(传统 NLP、数学、代码等)得到广泛验证,目前已经深刻影响到腾讯混元团队日常生活的方方面面。 腾讯混元团队长期致力于大语言模型的探索之路,大模型生产的各个环节开展研究创新以提升其基础能力,并将混元大模型的能力跟业务做深度结合,让生成式 AI 成为业务增长的放大器。 大语言模型的设计、训练和优化是一项复杂的系统工程,涉及到模型结构创新、训练范式优化、数据获取和评测设计、关键能力提升和挑战性问题的解决等方方面面。

首个可保留情感的音频 LLM:Meta 重磅开源 7B-Spirit LM,一网打尽“音频 + 文本”多模态任务
Meta 开源了一个基础多模态语言模型 Spirit LM,基于一个 70 亿参数的预训练文本语言模型,交错使用文本和语音数据进行训练,使模型能够自由地混合文本和语音,在任一模态中生成语言内容。

写给小白的大模型入门科普
什么是大模型? 大模型,英文名叫Large Model,大型模型。 早期的时候,也叫Foundation Model,基础模型。

没有思考过 Embedding,谈何 RAG,更不足以谈 AI大模型
今天,我们来聊聊 AI 大模型,有一个非常重要概念 "Embedding"。 你可能听说过它,也可能对它一知半解。 如果你没有深入了解过 Embedding,那你就无法真正掌握 RAG 技术,更不能掌握 AI 大模型精髓所在。

405B大模型也能线性化!斯坦福MIT最新研究,0.2%训练量让线性注意力提分20+
生产级大模型应用线性注意力的方法,来了。 线性Attention(包括RNN系列),再也不用困在几B参数的范围内娱乐了。 一套方法,即可线性化现有各种量级的Transformer模型,上至Llama 3.1 405B,也只需要十来张显卡在两天内搞定!

昆仑万维推出“天工大模型 4.0”4o 版及实时语音助手 Skyo,号称可克服大模型幻觉
今天上午,昆仑万维宣布推出“天工大模型4.0”4o版(Skywork 4o)以及新产品“实时语音对话助手Skyo”。

年度世界互联网科技大奖公布,腾讯Angel机器学习平台获领先科技奖
11月19日,2024年世界互联网大会领先科技奖在乌镇发布,腾讯Angel机器学习平台凭借其卓越的技术积累、创新的关键技术和广泛的应用场景,荣获本年度领先科技奖。 腾讯Angel 机器学习平台,突破了万亿级模型分布式训练和推理以及大规模应用部署等难题,率先实现大模型技术从底层硬件到关键软件技术的自主研发,在业务场景广泛应用,显著推动实体产业和数字经济发展,提升社会效率。 世界互联网大会领先科技奖由世界互联网大会主办,旨在奖励全球年度最具领先性的互联网科技成果,倡导互联网技术国际交流合作。

LLM为何频频翻车算术题?研究追踪单个神经元,「大脑短路」才是根源
由于缺少对运行逻辑的解释,大模型一向被人称为「黑箱」,但近来的不少研究已能够在单个神经元层面上解释大模型的运行机制。 例如Claude在2023年发表的一项研究,将大模型中大约500个神经元分解成约4000个可解释特征。 而10月28日的一项研究,以算术推理作为典型任务,借鉴类似的研究方法,确定了大模型中的一个模型子集,能解释模型大部分的基本算术逻辑行为。
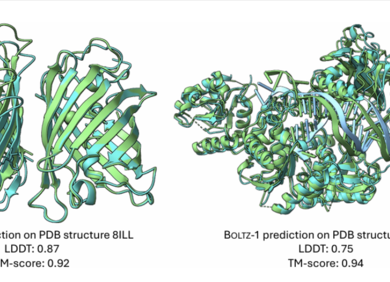
AlphaFold3级性能、开源、可商用,MIT团队推出生物分子预测模型Boltz-1
图示:来自测试集的靶标上的 Boltz-1 的示例预测。 (来源:论文)编辑 | 萝卜皮2024 年 11 月 18 日,麻省理工学院(MIT)的研究人员宣布推出 Boltz-1,这是一个开源模型,旨在准确模拟复杂的生物分子相互作用。 Boltz-1 是第一个完全商业化的开源模型,在预测生物分子复合物的 3D 结构方面达到 AlphaFold3 级精度。

视频大模型无损提速:删除多余token,训练时间减少30%,帧率越高效果越好 | NeurIPS
把连续相同的图像块合并成一个token,就能让Transformer的视频处理速度大幅提升。 卡内基梅隆大学提出了视频大模型加速方法Run-Length Tokenization(RLT),被NeurIPS 2024选为Spotlight论文。 在精度几乎没有损失的前提下,RLT可以让模型训练和推理速度双双提升。

大模型时代下的私有数据安全与利用
一、大模型时代下的数据安全与利用问题众所周知,大模型是当前研究的热点之一,且已成为当前发展的主流趋势。 我们团队最近的研究方向从传统的联邦学习转变为探索这一范式在大模型时代的新拓展,即基于知识迁移的联邦学习。 我们认为在大模型时代,这种新的联邦学习模式非常适用。

大模型容易忽视的安全,火山方舟早就「刻」进了基因
大模型时代,企业使用云上模型的痛点有哪些? 你可能会说模型不够精准,又或者成本太高,但这些随着AI技术的快速发展,在不远的将来或许都不再是问题。 比如成本,自豆包大模型首次将价格带进“厘”时代以来,行业纷纷跟进,企业客户从此不再为使用模型的成本过度高昂而烦扰。

简单了解大模型(LLM)智能体,传统软件工程思维依然适用
说到大模型应用的理想态,我相信很多人都可以想到《钢铁侠》里面的贾维斯,可以根据环境、天气、对手火力等情况,给钢铁侠提供决策指导或者自主决策。 大模型Agent就是人们希望借助大模型实现的类似于贾维斯一样智能助手能力,它具备环境感知能力、自主理解、决策制定以及行动执行的能力。 在实现Agent架构过程中,有很多思维方式和传统软件工程思维是相似的。

今日最热论文:Scaling Law后继乏力,量化也不管用,AI大佬齐刷刷附议
几十万人关注,一发表即被行业大佬评为“这是很长时间以来最重要的论文”。 哈佛、斯坦福、MIT等团队的一项研究表明:训练的token越多,需要的精度就越高。 例如,Llama-3在不同数据量下(圆形8B、三角形70B、星星405B),随着数据集大小的增加,计算最优的精度也会增加。
如何使用Hugging Face Transformers微调F5以回答问题?
译者 | 布加迪审校 | 重楼使用Hugging Face Transformers对T5模型进行微调以处理问题回答任务很简单:只需为模型提供问题和上下文,它就能学会生成正确的答案。 T5是一个功能强大的模型,旨在帮助计算机理解和生成人类语言。 T5的全称是“文本到文本转换器”。

Seed校招博士自述:我为什么选择来字节做大模型
原文来自知乎博主张逸霄对“大家能分享一下当前博士就业的情况吗”的回答。 人在英国,刚过答辩。 今年拿了腾讯 AI Lab(青云计划)、字节跳动(Seed) ,国外有之前实习的 Sony Research 和 Yamaha 的 return offer,国外也有正在面试的 Adobe 和 Meta。

类Sora模型到底懂不懂物理?字节完成系统性实验,图灵奖得主杨立昆赞转!
Sora爆火以来,“视频生成模型到底懂不懂物理规律”受到热议,但业界一直未有研究证实。 近日,字节跳动豆包大模型团队公布最新论文,研究历时8个月,围绕“视频生成模型距离世界模型有多远”首次在业界完成系统性实验并给出明确结论:视频生成模型可以记忆训练案例,但暂时还无法真正理解物理规律,做到“举一反三”。 图灵奖得主、Meta首席AI科学家杨立昆点赞并转发了该研究,表示“结论不令人意外,但很高兴终于有人做了这个尝试!

达摩院发布八观气象大模型:精度达1小时1公里,率先落地新能源场景
11月6日,阿里巴巴达摩院(湖畔实验室)在北京举行决策智能产品发布会,正式发布八观气象大模型,在全球气象模型基础上引入区域多源数据,时空精度最高可达1公里*1公里*1小时。 通过大幅提升对温度、辐照、风速等关键气象指标的预测性能,八观气象大模型率先落地新能源占比高的新型电力系统,助力国网山东电力调控中心成功预测了多次极端天气,新能源发电功率、电力负荷预测准确率分别提升至96%和98%以上。 传统上,气象学家们根据物理规律,将大气运动变化编写成一系列数学物理方程再进行数值计算,耗费大量算力资源,且受到物理模型的瓶颈制约,难以快速、高效地满足各行业不同准确率、分辨率的天气预需求。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉