策略

神经网络的泛化能力:数学分析与提升策略
从图像识别到语音处理,从自然语言理解到复杂系统的预测,神经网络的应用无处不在。 然而,一个关键问题始终困扰着研究人员和实践者:神经网络的泛化能力。 泛化能力决定了神经网络在面对新的、未见过的数据时,能否准确地进行预测和决策。

性能优化!七个策略,让Spring Boot 处理每秒百万请求
环境:SpringBoot3.4.21. 简介在实施任何优化前,我首先明确了性能基准。 这一步至关重要——若不清楚起点,便无法衡量进展,也无法定位最关键的改进方向。

大模型重复生成内容:根因剖析与优化策略
前言最近在调试大模型应用过程中,遇到了如下问题:复制大模型首次生成内容与「重新生成」两次返回的内容近乎完全相同,几乎没有体现出任何差异性。 面对这种情况,造成大模型输出高度相似的原因是什么呢? 我们又该采取怎样的调整策略,才能使重新生成的内容与前次存在明显差异,提升输出的多样性呢?

LLM幻觉,竟因知识「以大欺小」!华人团队祭出对数线性定律与CoDA策略
大语言模型(LLMs)已经彻底改变了AI,但「幻觉」问题如影随从,堪称LLM癌症。 LLM会一本正经、义正辞严的捏造事实,「脸不红,心不跳」地说谎。 「幻觉」被普遍认为与训练数据相关。

RAG技术落地的两个问题及应对策略
什么是RAG? RAG的全称是检索增强生成(Retrieval-Augmented Generation,简称RAG),它结合了检索和和生成技术,通过整合检索系统和生成模型的优势,来提升模型生成文本的质量和上下文相关性。 这种技术主要是为了解决生成式模型在面对需要具体、实时或领域专业知识时可能产生的准确性不足和上下文不敏感的问题。

夺冠!卓世AI斩获全球顶会AAMAS 2024 CE 竞赛冠军
近日,在全球瞩目的AAMAS 2024 Computational Economics Competition(计算经济学挑战赛)上,卓世科技人工智能前沿实验室团队“Zhuoshi Technology AI Cutting-edge Laboratory”一举夺得两个核心赛道的冠军和亚军,展现出其在计算经济学和人工智能领域的强大竞争力。冠军证书亚军证书AAMAS 2024 是第23届国际自主智能体和多智能体系统会议(International Conference on Autonomous Agents and

斯坦福团队新作:喊话就能指导机器人,任务成功率暴增,网友:特斯拉搞快点
斯坦福的 ALOHA 家务机器人团队,发布了最新研究成果 ——项目名为 Yell At Your Robot(简称 YAY),有了它,机器人的“翻车”动作,只要喊句话就能纠正了!而且机器人可以随着人类的喊话动态提升动作水平、即时调整策略,并根据反馈持续自我改进。比如在这个场景中,机器人没能完成系统设定的“把海绵放入袋子”的任务。这时研究者直接朝它喊话,“用海绵把袋子撑得再开一些”,之后就一下子成功了。而且,这些纠正的指令还会被系统记录下来,成为训练数据,用于进一步提高机器人的后续表现。有网友看了说,既然已经能朝着机
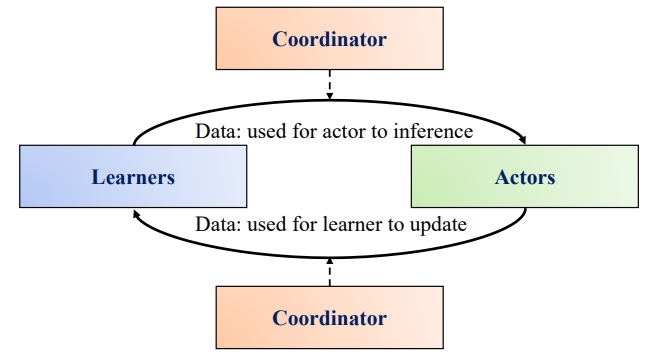
从框架到经典方法,全面了解分布式深度强化学习DDRL
本文在回顾分布式深度强化学习 DDRL 基本框架的基础上,重点介绍了 IMPALA 框架系列方法。AlphaGo 是一个在人机博弈中赢得众多职业围棋手的 agent 机器人。随着 AlphaGo 的突破,深度强化学习(Deep Reinforcement Learning,DRL)成为一种公认的解决连续决策问题的有效技术。人们开发了大量算法来解决介于 DRL 与现实世界应用之间的挑战性问题,如探索与开发困境、数据低效、多 agent 合作与竞争等。在所有这些挑战中,由于 DRL 的试错学习机制需要大量交互数据,数据

Creator 面对面 | 自监督学习范式未来能够在强化学习中发挥关键的作用
我们都知道自监督学习在 CV 和 NLP 领域都有比较广泛的应用,比如大模型 BERT、GPT-3 等训练,其实最核心的技术就是基于自监督学习的技术。
那么在 CV 和 NLP 领域都取得成功的自监督学习,是否可以被借鉴或是利用到强化学习领域呢?

通过奖励随机化发现多智能体游戏中多样性策略行为,清华、UC伯克利等研究者提出全新算法RPG
在这篇论文中,研究者提出了一个在 reward-space 进行探索的新算法 RPG(Reward-Randomized Policy Gradient),并且在存在多个纳什均衡 (Nash Equilibrium, NE) 的挑战性的多智能任务中进行了实验验证,实验结果表明,RPG 的表现显著优于经典的 policy/action-space 探索的算法,并且发现了很多有趣的、人类可以理解的智能体行为策略。除此之外,论文进一步提出了 RPG 算法的扩展:利用 RR 得到的多样性策略池训练一个新的具备自适应能力的策
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉