从图像识别到语音处理,从自然语言理解到复杂系统的预测,神经网络的应用无处不在。
然而,一个关键问题始终困扰着研究人员和实践者:神经网络的泛化能力。
泛化能力决定了神经网络在面对新的、未见过的数据时,能否准确地进行预测和决策。
本文将深入探讨神经网络的泛化能力,从数学的角度进行分析,并提出有效的提升策略,帮助读者更好地理解和应用神经网络。
PART1.泛化能力的数学定义
首先,我们用一个简单的例子来解释泛化能力。假设你正在训练一个神经网络模型来识别猫和狗的图片。在训练过程中,模型看到了大量的猫和狗的图片,并学会了区分它们。
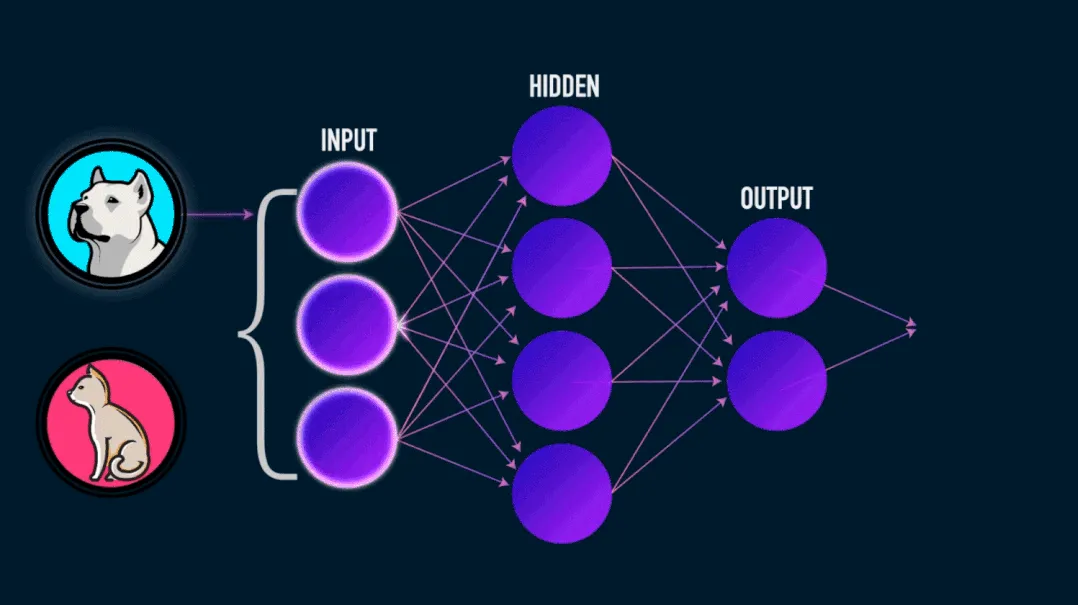 图片
图片
但是,当模型遇到一张它从未见过的猫的图片时,它能否正确地识别出这是一只猫呢?这就是泛化能力所关注的问题。
泛化能力是指神经网络在新的、未见过的数据上表现的能力。
在数学上,泛化能力可以通过泛化误差来定义。泛化误差是指神经网络在真实数据分布上的误差,即网络在所有可能的数据上的平均误差。用公式表示为:

以下是衡量模型泛化能力的常见指标:
1. 测试误差:测试误差是衡量泛化能力最直接的方法。它是在独立的测试数据集上计算的误差。
 图片
图片
测试数据集是网络在训练过程中从未见过的数据,因此测试误差能够很好地反映网络在新数据上的表现。
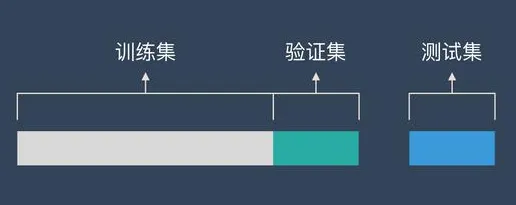
2. 交叉验证误差:交叉验证是一种更稳健的评估方法。它将数据集分成多个子集,每次用其中一个子集作为测试集,其余子集作为训练集。
 图片
图片
通过多次训练和测试,计算平均误差来评估网络的泛化能力。这种方法可以减少测试误差的偶然性,更准确地反映网络的泛化性能。
3. 泛化误差的估计:在实际应用中,我们通常无法直接计算泛化误差,因为它涉及到对真实数据分布的期望。
 图片
图片
但是,我们可以通过一些统计方法来估计泛化误差。例如,使用 Hoeffding 不等式可以给出泛化误差的一个概率上界,帮助我们了解网络泛化能力的可靠性。
PART2.影响泛化能力的因素分析
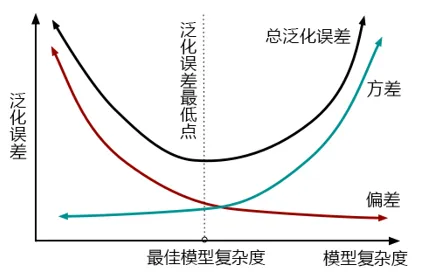
模型的泛化能力是衡量其在未见过的新数据上表现能力的关键指标,而模型复杂度、数据质量与数量、训练算法与优化策略是影响泛化能力的三个主要因素。以下是对这些因素的详细分析:
1.设计思想
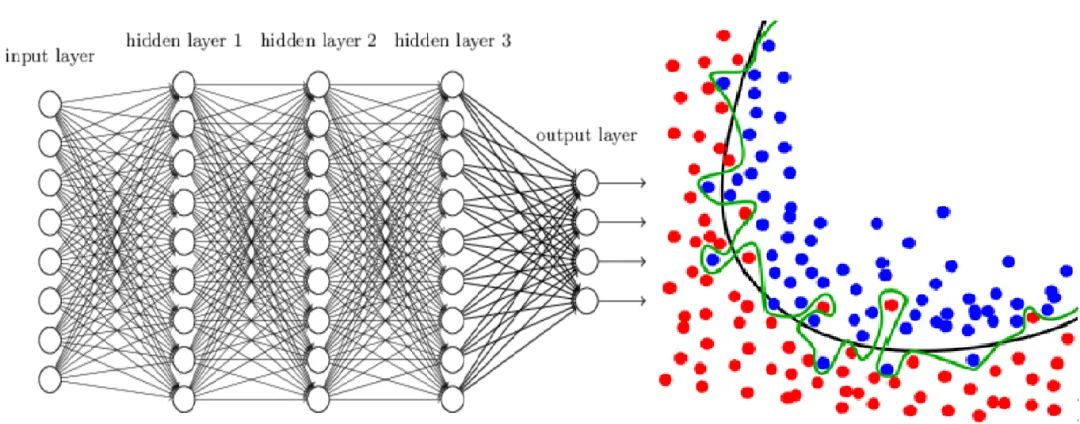
模型复杂度是影响泛化能力的关键因素之一。一个复杂的神经网络模型,如深度很大的网络或参数数量很多的网络,具有很强的拟合能力。
它可以完美地拟合训练数据,甚至包括数据中的噪声。然而,这种过度拟合会导致网络在新的数据上表现不佳。
 图片
图片
例如,一个过拟合的网络可能会将训练数据中的某些特定特征误认为是分类的依据,而在测试数据中这些特征可能并不存在,从而导致错误的预测。
另一方面,如果模型过于简单,也可能导致泛化能力不足。
这种情况下,网络无法捕捉到数据中的复杂模式,从而在训练数据和测试数据上都表现不佳。
 图片
图片
例如,一个只有几层的简单神经网络可能无法有效地学习到图像中复杂的纹理和形状特征,导致分类错误率较高。
2.数据质量与数量
高质量的数据对于神经网络的泛化能力至关重要。数据质量包括数据的准确性、完整性和代表性。
如果数据中存在错误或缺失值,或者数据不能很好地代表真实世界的情况,那么网络的泛化能力将受到严重影响。
 图片
图片
例如,在一个医疗诊断任务中,如果训练数据中的病例不完整或存在错误诊断,那么网络可能会学习到错误的模式,导致在实际应用中误诊。
数据数量也是影响泛化能力的重要因素。一般来说,数据量越大,网络的泛化能力越强。
更多的数据可以提供更丰富的信息,帮助网络更好地学习数据中的模式和规律。
例如,在一个语言模型中,大量的文本数据可以帮助网络学习到语言的复杂结构和语义关系,从而在生成文本或翻译文本时表现得更好。
3.训练算法与优化策略
不同的训练算法对神经网络的泛化能力有不同的影响。
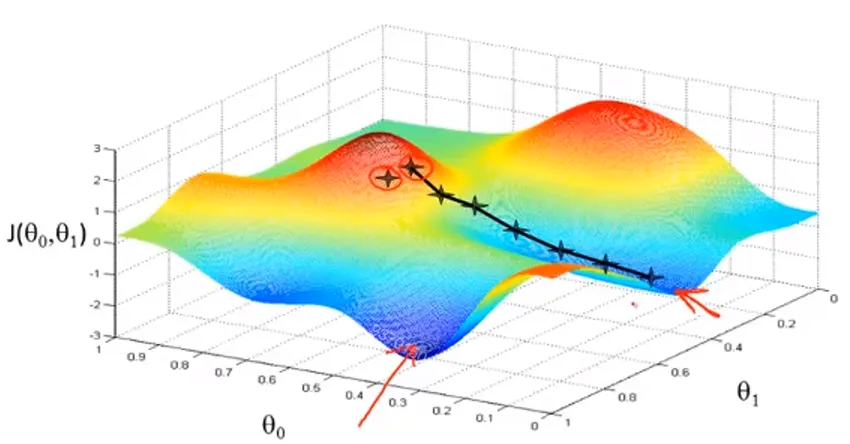 图片
图片
例如,随机梯度下降(SGD)算法在训练过程中引入了随机性,这有助于网络跳出局部最优解,找到更全局的最优解,从而提高泛化能力。
而一些更复杂的优化算法,如 Adam 或 RMSprop,虽然在训练速度上可能更快,但在某些情况下可能会导致网络过拟合。
正则化技术是提高泛化能力的重要手段。常见的正则化方法包括 L1 和 L2 正则化。
L1 正则化通过在损失函数中加入参数的绝对值来惩罚模型的复杂度,促使网络学习到更稀疏的参数。
 图片
图片
L2 正则化则通过加入参数的平方来惩罚模型的复杂度,使网络的参数更平滑。
这些正则化技术可以有效地防止网络过拟合,提高泛化能力。
PART3.提升泛化能力的数学策略
为了提升模型的泛化能力,可以采用以下数学策略:数据增强、正则化、早停法。
这些策略从不同的角度出发,通过增加数据的多样性、限制模型的复杂度以及合理控制训练过程,有效地提高了模型在未见过的新数据上的表现。
1.正则化
如上所述,L1 和 L2 正则化是两种常用的模型正则化方法。
通过对模型参数的范数进行约束,有效地防止模型过度拟合训练数据,使模型在新数据上具有更好的泛化能力。
Dropout 则是另一种特殊的正则化技术。
在训练过程中,Dropout 随机地丢弃网络中的一些神经元,使网络在每次训练时都使用不同的子网络。
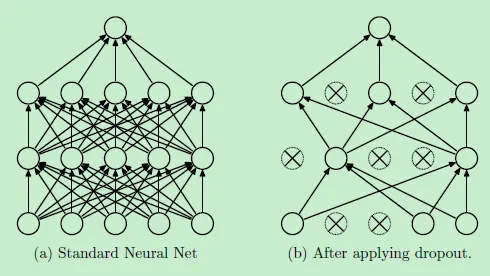 图片
图片
这种方法可以防止神经元之间的共适应,提高网络的泛化能力。
例如,在一个深度神经网络中,使用 Dropout 可以使网络在训练过程中学习到更鲁棒的特征,从而在测试数据上表现更好。
2.早停法
早停法是一种在训练过程中提前停止训练的方法,以防止网络过拟合。其基本原理是通过监控网络在验证集上的误差,在误差开始上升时停止训练。
从数学角度来看,早停法可以通过监控验证误差的变化来实现。
假设验证误差为 验证,训练误差为 训练,那么早停法的目标是找到一个合适的停止点 ,使得 验证 最小化。具体来说,早停法可以通过以下步骤实现:
- 初始化网络参数 。
- 在每个训练步骤 上,计算训练误差 训练 和验证误差 验证。
- 如果 验证 在连续 个步骤上没有下降,则停止训练,返回当前的网络参数 。
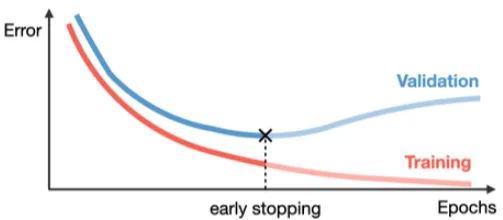 图片
图片
如上图,当网络开始过拟合时,验证误差会逐渐增加,而训练误差会继续下降。
所以,通过早停法在网络过拟合之前停止训练,可以有效地防止网络过拟合,提高泛化能力。同时,也可以节省训练时间,提高训练效率。
3.数据增强
数据增强是一种通过生成新的训练数据来提高泛化能力的方法。它的基本原理是通过对原始数据进行变换,如旋转、缩放、裁剪、颜色调整等,生成新的数据样本。
从数学角度来看,数据增强可以通过数据分布的扩展来描述。
假设原始数据的分布为 原始,通过数据增强生成的新数据的分布为 增强,那么数据增强的目标是使 增强 更接近真实数据分布 真实。
这些新的数据样本在一定程度上模拟了真实世界中的数据变化,从而帮助网络学习到更鲁棒的特征。
 图片
图片
例如,在图像识别任务中,通过对图像进行旋转和缩放,网络可以学习到物体在不同角度和大小下的特征,从而在面对新的图像时能够更准确地识别。
结 语
在本文中,我们深入探讨了神经网络的泛化能力,从数学的角度进行了分析,并提出了多种提升策略。
我们首先定义了泛化能力,并介绍了衡量泛化能力的指标,如测试误差和交叉验证误差。
然后,我们分析了影响泛化能力的因素,包括模型复杂度、数据质量与数量以及训练算法与优化策略。
接着,我们提出了多种提升泛化能力的策略,如数据增强、模型正则化和早停法。


