参数

斯坦福最新研究:AI 的上下文比参数重要,无需重训、不再微调
大数据文摘出品近日,斯坦福大学与 SambaNova Systems 合作发表了论文《Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models》。 该论文提出了一个名为ACE(Agentic Context Engineering)的框架,可以让AI在不重新训练权重的前提下,实现自我改进。 图片论文链接:,大模型的能力,并非仅由参数决定,更取决于“上下文的质量”。

全球第一!百度0.9B参数大模型碾压传统OCR!
最近有个感觉特别强烈:AI正在从"识别文字"悄然进化成"理解文档"。 当我看到百度飞桨团队刚刚发布的PaddleOCR-VL在全球权威评测中以92.6分位列第一时,第一反应是——这个0.9B的"小家伙",怎么就把那些动辄几十亿参数的巨无霸给比下去了? 说实话,刚开始我也有点半信半疑。
Kimi开源又放大招!20秒更新万亿参数的中间件来了
Kimi开源又双叒放大招了! 一个中间件,就能让Kimi K2的万亿模型参数进入“秒更时代”。 图片不仅支持一次性把更新完的权重从一个节点同时发送给所有节点,还能实现点对点动态更新。

阿里最新模型真的猛! 真肝实测:硬刚GPT5,技压DS、月暗,情商比GPT5高,读懂下棋大爷淋雨4小时的倔犟,但我发现了一个问题
编辑 | 云昭出品 | 51CTO技术栈(微信号:blog51cto)越来越有趣了! 连续两天,中国队一天推出了一个万亿参数模型。 昨天是Kimi的k2-0905,今天凌晨,则是阿里的Qwen3-Max-preview!

OpenAI 开源模型被 Meta 研究员“逆改”!只动0.3%参数,gpt-oss-20B 解锁无约束基座
OpenAI在8月初发布了开放权重模型家族gpt-oss,这是公司自2019年GPT-2以来首次真正意义上的开源动作。 仅仅两周后,一位研究者就将这一模型“拆解重组”,推出了与官方版本迥异的变体。 康奈尔大学博士生、前Google Brain成员、现任Meta研究员的Jack Morris,公开了名为gpt-oss-20b-base的新版本。

中国石油发布3000亿参数昆仑大模型,助力智能化油气全产业链
中国石油天然气集团有限公司在北京正式发布了其最新的3000亿参数昆仑大模型。 这一重大成果标志着中国在大模型技术领域的又一次重要突破,体现了中央企业在人工智能领域的快速发展和创新能力。 新的昆仑大模型相比于2024年11月发布的700亿参数版本有了显著提升。

DeepSeek R2提前泄露?周二或周三发布?海外谣言一夜刷屏,HggingFace CEO一帖子引疯狂猜想,DS又被消费了
昨天晚上,“DeepSeek R2提前泄露”的传言刷屏 AI 圈,原因尽然来自Hugging Face CEO 在推特的一条帖子,引发全网猜测。 帖子表达的信息有些晦涩:三个眼睛表情,配上了DeepSeek 在 Hugging Face 的仓库链接()以及相关配图。 网友难免会联想猜测:也许DeepSeek R2 即将上线发布。
预测所有物种DNA、RNA、蛋白质的形式和功能,Arc、斯坦福、NVIDIA发布最大AI生物模型Evo2
编辑 | 萝卜皮所有生命都用 DNA 编码信息。 虽然测序、合成和编辑基因组代码的工具已经改变了生物学研究,但智能地编写新的生物系统还需要深入了解基因组编码的巨大复杂性。 科学家们今天发布了他们所称的有史以来最大的生物学人工智能(AI)模型——Evo-2。

看听读全都会的六边形战士MiniCPM,来啦
MiniCPM-o 2.6开源啦,该模型视觉、语音和多模态流式能力达到了 GPT-4o-202405 级别。 图片简介MiniCPM-o 2.6是一个端侧多模态大模型,具有8B参数量。 它基于SigLip-400M、Whisper-medium-300M、ChatTTS-200M和Qwen2.5-7B构建,通过端到端的方式训练和推理。

中国MoE一夜爆火!大模型新王暴打GPT-4o,训练成本仅600万美元
一夜之间,来自中国的大模型刷屏全网。 DeepSeek-V3,一个拥有671B参数的MoE模型,吞吐量每秒高达60 token,比上一代V2直接飙升3倍。 在多项基准测试中,V3性能直接与Claude 3.5 Sonnet、GPT-4o相匹敌。

终于把机器学习中的超参数调优搞懂了!!!
大家好,我是小寒今天给大家分享机器学习中的一个关键知识点,超参数调优超参数调优是机器学习中调整模型超参数以优化模型性能的过程。 超参数是用户在模型训练前需要手动设置的参数,与训练过程中通过算法自动调整的参数(如神经网络中的权重)不同。 这些超参数直接控制着训练过程和模型的行为,例如学习率、隐藏层的数量、隐藏层的节点数等。

荣耀 MagicOS 9.0 升级支持 30 亿参数端侧大语言模型:功耗下降 80%,内存占用减少 1.6GB
感谢荣耀今日正式发布 MagicOS 9.0,号称是“行业首个搭载智能体的个人化全场景 AI 操作系统”。 在 MagicOS 9.0 中,MagicOS 全新魔法大模型家族迎来升级,支持端云资源灵活调配,不同设备灵活部署,AI在线附各版本如下:500 万参数图像大模型,端侧部署,全系列支持4000 万参数图像大模型,端侧部署,中高端系列30 亿参数大语言模型,端侧部署,中高端系列10 亿参数多模态大模型,端侧部署,中高端系列1500 万参数语音大模型,端侧部署,全系列支持荣耀表示,MagicOS 9.0 升级支持 30 亿参数端侧大语言模型,相比 MagicOS 8.0 的 70 亿参数魔法大模型,加载速度提升 77%、出词速度提升 500%、功耗下降 80%。 此外,新版大模型的内存占用减少 1.6GB,存储占用减少 1.8GB。

330 亿参数昆仑大模型发布:中国能源化工行业首个通过备案的大模型,中国石油携手中国移动、华为和科大讯飞打造
科大讯飞集团官方公众号发布博文,表示昨日(8 月 28 日)在北京举办的成果发布会上,中国石油发布 330 亿参数昆仑大模型,是中国能源化工行业首个通过备案的大模型。昆仑大模型简介AI在线援引新闻稿,昆仑大模型由中国石油、中国移动、华为公司和科大讯飞联合打造,于今年 5 月签署合作共建协议,按照“五个一”行动计划,训练了 8 个大模型、研发了 18 个应用场景。图源:科大讯飞昆仑大模型已于 8 月 23 日通过了国家生成式人工智能服务备案,是中国能源化工行业首个通过备案的大模型。在顶层设计具有三大特点:一是创新提出

DeepMind 研究成本大起底,一篇 ICML 论文烧掉 1290 万美元
【新智元导读】DeepMind 最近被 ICML 2024 接收的一篇论文,完完全全暴露了他们背靠谷歌的「豪横」。一篇文章预估了这项研究所需的算力和成本,大概是 Llama 3 预训练的 15%,耗费资金可达 12.9M 美元。发一篇顶会论文,需要多少实验预算?最近,DeepMind 发表了一项研究,对 LLM 扩大规模时各种算法和架构细节,比如参数和优化器的选择,进行了广泛的实证调查。这篇论文已被 ICML 2024 接收。论文地址: 页的论文涵盖了数以万计的模型,备选方案包括 3 种优化器、4 种参数化方案、几

13瓦功耗处理10亿参数,接近大脑效率,消除LLM中的矩阵乘法来颠覆AI现状
编辑 | 萝卜皮通常,矩阵乘法 (MatMul) 在大型语言模型(LLM)总体计算成本中占据主导地位。随着 LLM 扩展到更大的嵌入维度和上下文长度,这方面的成本只会增加。加州大学、LuxiTech 和苏州大学的研究人员声称开发出一种新方法,通过消除过程中的矩阵乘法来更有效地运行人工智能语言模型。这从根本上重新设计了目前由 GPU 芯片加速的神经网络操作方式。研究人员描述了如何在不使用 MatMul 的情况下创建一个自定义的 27 亿参数模型,性能与当前最先进的 Transformer 模型相当。该研究以「Scal
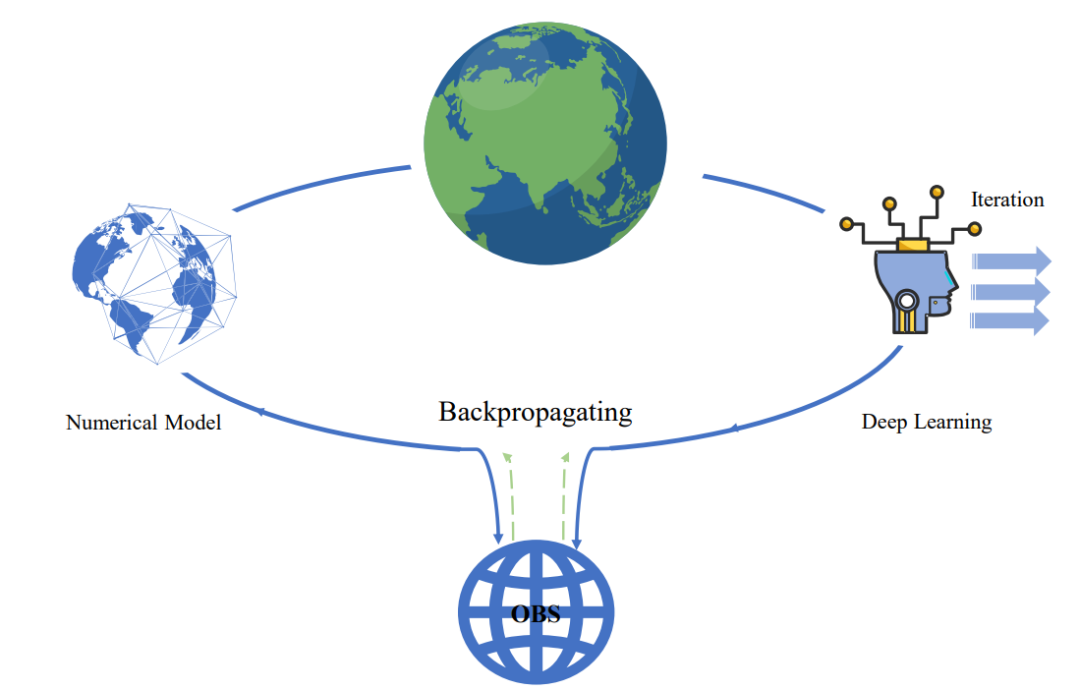
打破「非此即彼」,平衡 AI 与物理,中国科学院提出建立可学习的气候模型
平衡 AI-物理模型示意图。编辑 | X人工智能(AI)迅速发展,大模型正在重新定义我们理解和应对气候挑战的方式。AI 模型已经席卷了大气科学的各个领域。今年年初,中国科学院大气物理研究所黄刚研究员团队将物理与 AI 融合,提升了数值模式的降水预报技巧。近日,黄刚团队联合中国科学院大学、青岛海洋科学与技术国家实验室、同济大学和首尔国立大学在《Advances in Atmospheric Sciences》上,发表了题为「Toward a Learnable Climate Model in the Artific

iPhone 上本地每秒生成 12 个 tokens,微软发布 phi-3-mini 模型:38 亿参数
微软研究院近日发布技术报告,公布了 Phi-3 系列 AI 模型,共有 mini(38 亿参数)、small(70 亿参数)和 medium(140 亿参数)三个版本。微软表示拥有 38 亿参数的 phi-3-mini 通过 3.3 万亿个 tokens 上训练,其基准跑分性能超出 Mixtral 8x7B 和 GPT-3.5。微软表示 phi-3-mini 模型可以部署在手机等设备上,在 27 亿参数的 Phi-2 模型上,进一步整合了严格过滤的网络数据和合成数据。微软也坦言 phi-3-mini 模型虽然通过优

Meta 发布 Llama 3,号称是最强大的开源大语言模型
感谢Meta 公司今天发布新闻稿,宣布推出下一代大语言模型 Llama 3,共有 80 亿和 700 亿参数两种版本,号称是最强大的开源大语言模型。Meta 声称,Llama 3 的性能优于 Claude Sonnet、Mistral Medium 和 GPT-3.5,IT之家附上 Llama 3 的主要特点如下:向所有人开放:Meta 开源 Llama 3 的 80 亿参数版本,让所有人都能接触最前沿的人工智能技术。全球各地的开发人员、研究人员和好奇心强的人都可以进行游戏、构建和实验。更聪明、更安全:Llama
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉