Kimi开源又双叒放大招了!
一个中间件,就能让Kimi K2的万亿模型参数进入“秒更时代”。
 图片
图片
不仅支持一次性把更新完的权重从一个节点同时发送给所有节点,还能实现点对点动态更新。
网友也算是大开眼界了,可谓频频惊叹。
 图片
图片
下面让我们一起看看这个中间件到底是如何发挥大作用的。
20秒更新万亿参数
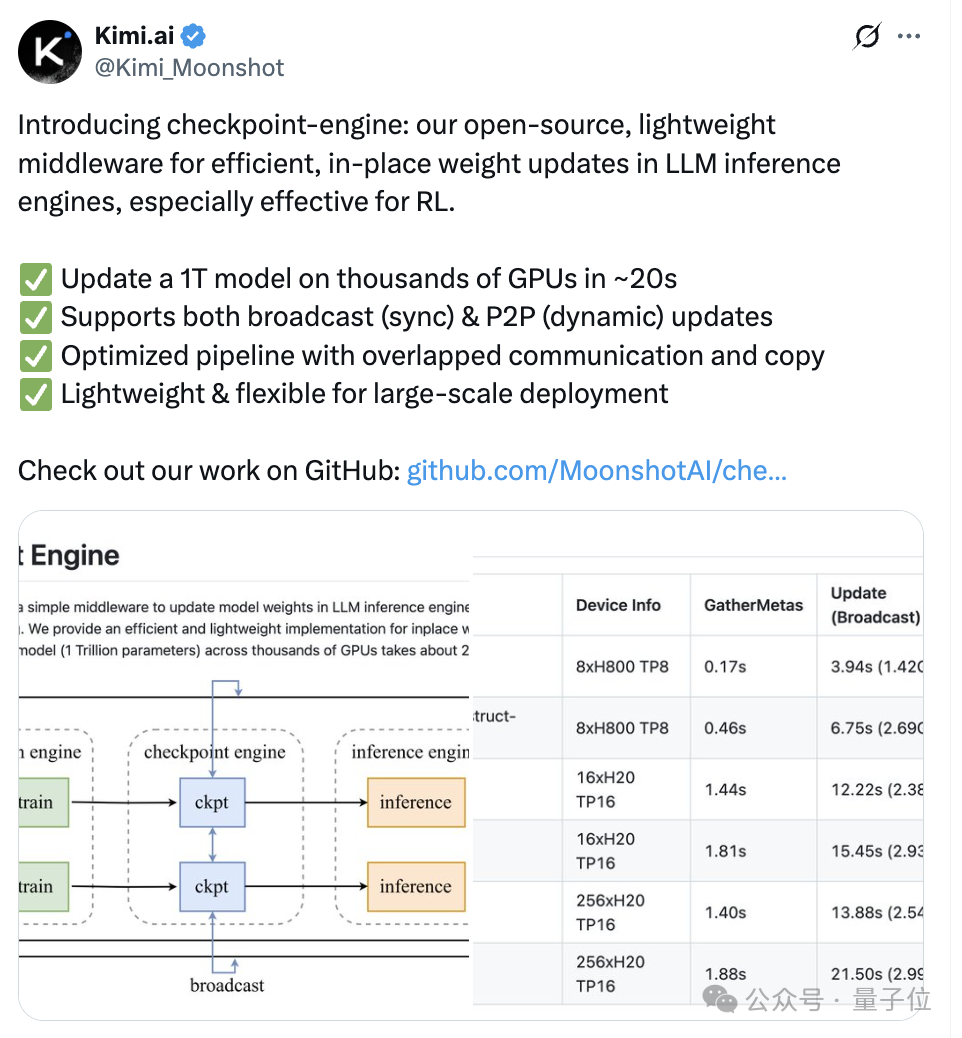
此中间件名为checkpoint-engine(检查点引擎),主要用于强化学习中的一个关键步骤——在大语言模型推理过程中更新模型权重。
借助此组件,Kimi-K2只需约20秒就可实现在数千个GPU上更新1万亿参数。
与Kimi k1. 5类似,K2在同步强化学习训练中采用了混合共置架构,即训练引擎和推理引擎部署在同一组工作节点上。
当一个引擎处于活跃工作状态时,另一个引擎会释放或卸载其GPU资源以以配合资源调配。
在每一次强化学习训练迭代中,集中式控制器会先调用推理引擎生成新的训练数据,随后通知训练引擎基于这些数据进行训练,并将更新后的参数发送至推理引擎,供下一轮迭代使用。
因此,每个引擎都针对高吞吐量进行了深度优化。
然而,随着模型规模扩展至K2级别,引擎切换与故障恢复的延迟变得尤为显著。
所以,研究团队思考如何才能更高效地更新模型参数?
首先,在rollout阶段,训练引擎的参数会被卸载至DRAM(动态随机存取存储器)中,因此启动训练引擎仅需执行一次简单的H2D数据传输。
但在这个过程中,启动推理引擎会面临更大挑战,因为它必须从训练引擎获取更新后的参数,而两者的分片范式并不相同。
研究团队又考虑到K2的规模及庞大的设备数量,使用网络文件系统来重新切分并广播参数是不现实的。因为将系统开销保持在较低水平,所需的总带宽高达每秒数PB(千万亿字节)。
在上述背景下,检查点引擎应运而生。
 图片
图片
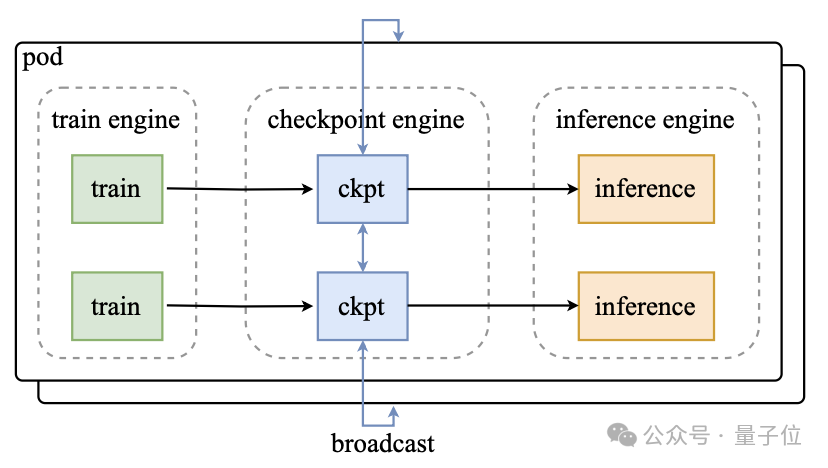
研究团队选择在训练节点上部署分布式检查点引擎来管理参数状态。
执行参数更新时,每个检查点工作节点先从训练引擎获取本地参数副本,然后将完整参数集广播到所有检查点节点。
随后,推理引擎仅从检查点引擎中获取自己所需的参数分片即可。
为了支持1万亿参数的模型更新,他们还选择采用参数逐条更新的流水线方式,将内存占用降至最低。
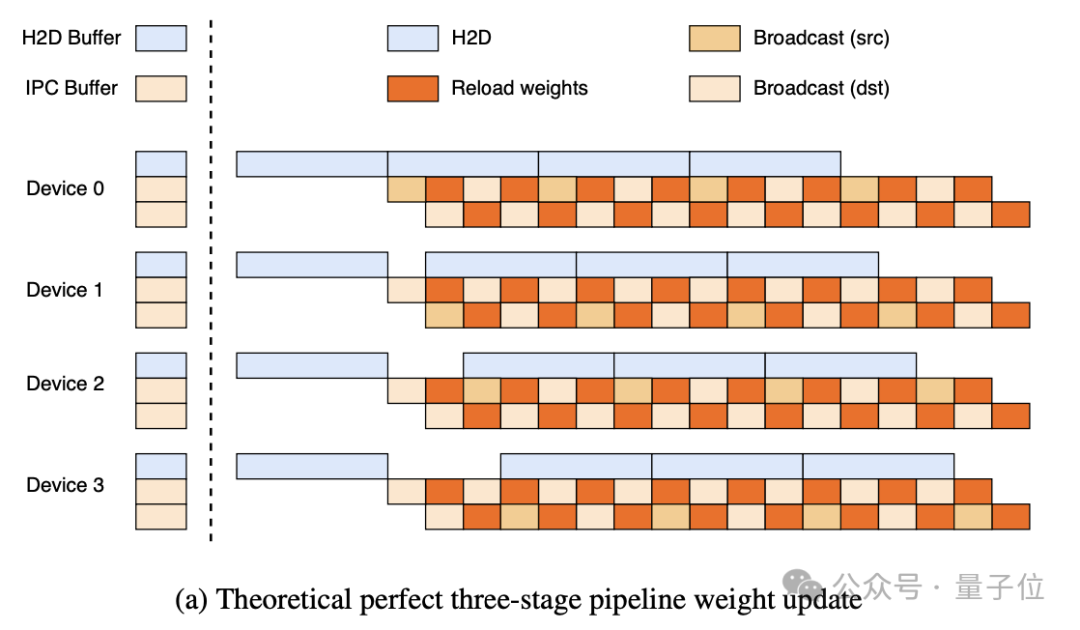
理论上的3阶段流水线如下所示:
- H2D阶段:将最新权重的一个分片异步复制到 H2D 缓冲区;
- 广播阶段:一旦复制完成,该分片会被复制到其中一个IPC缓冲区,并广播到所有GPU;
- 重载阶段:推理引擎同时从另一个IPC缓冲区加载参数。
 图片
图片
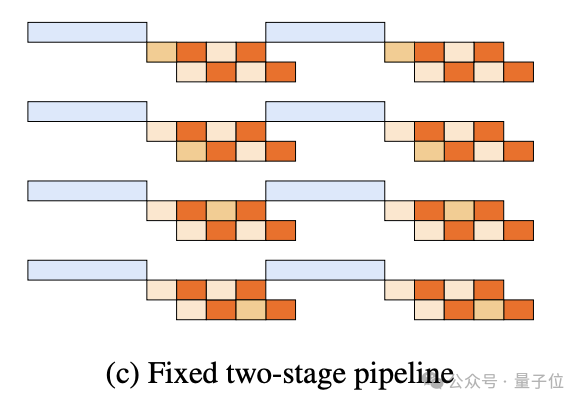
但需注意的是,这种理想的3阶段流水线目前尚未实现,K2应用的更简单的两阶段方案。
- 所有设备先进行一次同步的H2D传输;
- 广播和重载操作随后并行进行。
 图片
图片
他们选择将完整参数集广播到整个集群,而不考虑每个推理工作节点的具体切分方式。
虽然这种方式传输的数据量会比理论最优方案更多,但它可以简化系统设计,对训练和推理引擎的侵入性更低。
研究团队认为,通过牺牲这一点微小的开销,实现训练引擎与推理引擎的完全解耦,大大简化了维护和测试流程。
除了上述问题外,像Kimi K2这样的大模型,优化启动时间也至关重要。
启动训练引擎时,他们让每个训练工作节点选择性地从磁盘读取部分或不读取任何参数,并将必要参数广播至其他对等节点。
这么做的目的是确保所有工作节点只需集体读取一次检查点,从而最大限度地减少昂贵的磁盘IO开销。
除此之外,由于推理引擎是独立副本,研究团队希望避免在它们之间引入额外的同步屏障。
因此,他们选择在启动阶段复用检查点引擎。
让检查点引擎先像训练引擎启动时一样,集体从磁盘读取检查点,然后更新尚未初始化的推理引擎状态。
值得一提的是,通过利用专门的检查点引擎,系统还可以抵御单点故障,因为某个推理副本可以独立重启,而无需与其他副本通信。
这么一看,这一中间件真在Kimi K2中起了不小的作用呢。
参考链接:
[1]https://x.com/Kimi_Moonshot/status/1965785427530629243
[2]https://github.com/MoonshotAI/checkpoint-engine[3]https://arxiv.org/abs/2507.20534


