阿里通义

阿里通义 Qwen-lmage-Edit-2511 图像编辑 AI 模型开源,支持两人隔空“合照”
AI在线 12 月 25 日消息,阿里通义千问今日宣布 Qwen-Image-Edit-2511 正式开源。 Qwen-Image-Edit 是阿里通义团队推出的图像编辑模型。 2511 版本中着重进行了包括一致性提升在内的多项增强,新版本的整体生成质量、尤其是人物生成质量,得到显著提升。

阿里通义 Qwen3-TTS 家族上新两款 AI 模型:声音不仅能复制,还可以定制
AI在线 12 月 24 日消息,阿里通义今日官宣,Qwen3-TTS 家族新推出两款模型,音色创造模型 Qwen3-TTS-VD-Flash 和音色克隆模型 Qwen3-TTS-VC-Flash。 AI在线附模型主要特点如下:音色创造:Qwen3-TTS-VD-Flash 支持复杂自然语言指令输入,实现对音色、韵律、情感、人设等的精细化调控,实现从“说什么”到“如何说”的全面掌控,可以让用户自由地定义想要的音色,彻底摆脱只能进行根据已有的音色进行克隆或者只能选择固定的一部分预设音色。 在 InstructTTS-Eval 中综合表现显著优于 GPT-4o-mini-tts、Mimo-audio-7b-instruct,在角色扮演测试中也超越 Gemini-2.5-pro-preview-tts。

阿里通义发布端到端语音交互模型 Fun-Audio-Chat,能猜出你的心情
AI在线 12 月 23 日消息,阿里通义大模型今日发布了新一代端到端语音交互模型 Fun-Audio-Chat。 阿里通义本次开源了 Fun-Audio-Chat 8B,该模型在 OpenAudioBench、MMAU、Speech-ACEBench、VStyle 等多个榜单上“同尺寸模型排名第一”,综合性能超 GLM4-Voice、Kimi-Audio、Baichuan-Omni 等。 AI在线附 Fun-Audio-Chat 技术亮点如下:端到端 S2S 架构:从语音输入直接生成语音输出,无需 ASR LLM TTS 多模块拼接,效率更高、延迟更低。

阿里发布万相 2.6 系列模型,上线国内首个角色扮演功能
AI在线 12 月 16 日消息,阿里发布新一代万相 2.6 系列模型,该系列模型面向专业影视制作和图像创作场景进行了全面升级,全新的万相 2.6 是国内首个支持角色扮演功能的视频模型。 该模型同时支持音画同步、多镜头生成及声音驱动等功能,是全球功能最全的视频生成模型。 万相 2.6 已同步上线阿里云百炼、万相官网。

6B文生图模型,上线即登顶抱抱脸
梦瑶 发自 凹非寺. 量子位 | 公众号 QbitAI6B小模型,首日下载量高达50万次,上线不到两天直接把HuggingFace两个榜单都冲了个第一。 它就是阿里通义的全新图像模型:Z-Image。

Wan2.2-Animate又火了!5分钟让抠脚大汉秒变高冷女神
更多作者文章:最近,一个视频在推上传疯了。 当视频在手机上无法加载,可前往PC查看。 一张美女照片,加上一条自己录制的视频,就能生成一张极其自然的换脸视频,表情和动作复刻的都很好。

WebResearcher:从线性累积到迭代进化,重塑AI研究范式的三大支柱
大家好,我是肆〇柒。 本文一篇来自阿里巴巴通义实验室(Tongyi Lab, Alibaba Group)的研究,是通义 Deepresearch 发布的系列研究之一。 这篇论文不仅推出了一个名为WebResearcher的新型AI智能体,更重要的是,它提出了一种名为"IterResearch"的全新范式,期望从根本上解决长程推理任务中的核心瓶颈。

阿里通义深夜炸场:全球首个端到端全模态 AI 模型 Qwen3-Omni 发布开源,文本、图像、音视频全统一
9 月 23 日消息,又是熟悉的深夜,阿里云今日发布并开源了全新的 Qwen3-Omni、Qwen3-TTS,以及对标谷歌 Nano Banana 图像编辑工具的 Qwen-Image-Edit-2509。 Qwen3-Omni 是业界首个原生端到端全模态 AI 模型,能够处理文本、图像、音频和视频多种类型的输入,并可通过文本与自然语音实时流式输出结果,解决了长期以来多模态模型需要在不同能力之间进行权衡取舍的难题。 Qwen3-Omni 是原生端到端的多语言全模态基础模型,其核心特性主要包括:跨模态最先进表现:通过早期以文本为核心的预训练和混合多模态训练,模型具备原生多模态能力。
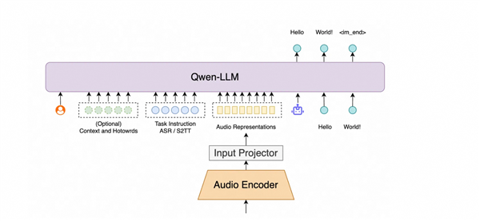
阿里通义Fun-ASR语音模型升级 垂直领域识别率跃升超15%
阿里通义正式推出新一代端到端语音识别大模型Fun-ASR,该模型通过强化上下文感知与高精度转写能力,在家装、保险等垂直行业场景中实现语音识别准确率超15%的突破性提升。 实测数据显示,保险行业准确率较前代提升18%,家装、畜牧等领域增幅达15%-20%。 作为大语言模型驱动的语音识别算法,Fun-ASR采用自研语音算法与Qwen3监督微调技术,结合前沿模型架构与文本模态对齐技术,在保持语言处理优势的同时,集成RAG检索增强方案,支持超1000个自定义热词导入。
LiblibAI接入阿里通义大模型 推出10秒AI视频生成功能
近日,国内AI图像创作领域的领军平台LiblibAI宣布一项重大举措——接入阿里通义系列大模型,这一动作显著提升了其AI创作能力,为用户带来了更强大的创作工具。 此次接入后,基于万相最新开源模型,LiblibAI推出了文生视频和图生视频功能。 用户只需输入文本提示词,或者上传图片,就能快速生成10秒短视频。

阿里巴巴推出AI旗舰应用“新夸克” 全面升级为“AI超级框”
3月13日,阿里巴巴正式推出其AI旗舰应用——新夸克。 这款全新升级的夸克基于阿里通义领先的推理及多模态大模型,打造了一个无边界的“AI超级框”,为用户带来全新的AI体验。 新夸克的创新之处在于将AI对话、深度思考、深度搜索、深度研究和深度执行等功能整合到一个极简的“AI超级框”中,一站式满足用户多样化的需求。

阿里通义新视频生成和编辑模型VACE 可控制运动轨迹、替换主体等
是否还在感叹视频制作门槛高,后期编辑太烧脑?别担心,阿里通义Wan团队再次出手,推出了他们最新的重量级模型All-in-One视频生成和编辑模型——VACE。 VACE最引人注目的能力之一,便是其强大的按条件生成视频功能。 这意味着,你只需要用文字描绘出心中的场景,VACE就能迅速将你的想象变为现实。

消息称字节跳动 8 位数年薪挖走阿里通义千问技术负责人周畅,十多个人跟着跳槽
原阿里通义千问大模型技术负责人周畅(花名:钟煌)于 7 月 18 日被曝将离职创业,然而在 10 月 23 日,就有消息称周畅已经低调加入了字节跳动。(第一财经)

神级模型 In-Context LoRA 爆火!10种场景精准出图!
大家好,我是花生~. 阿里通义实验室在月初推出的一个新开源项目 In-Context(上下文) LoRA 最近越来越火了,因为大家发现它实在太好用了,无论是保持人物/场景一致性,还是进行服装、风格、Logo、字体样式、页面版式的学习迁移,效果都非常不错,一下就解决了很多大家之前头疼的问题。 目前 In-Context LoRA 已经在摄影、电商设计、样机制作、头像生成等方面有了落地应用,极大满足了大家对精准控制出图的需求,那今天我们就一起来看看 In-Context LoRA (以下简称 IC LoRA)究竟有哪些神奇之处。

谨以此文,向飞天奖的AI整活视频「致敬」
AI好好用报道编辑:杨文5款对口型的AI产品,总有一款适合你。AI 最大的受害者,原来是娱乐圈的明星们。咋回事呢?前段时间,飞天奖官方整了个花活儿,让明星和电视剧中的 AI 角色合唱了一首《中国梦・我的梦》。那效果,简直一言难尽……(视频来源:B 站博主神仙颜颜_)视频链接:「扎心」:这个东西一端上来就有种淡淡的疯感。台下明星笑得最真心的一次。天呐唐嫣那个... 我都想替她报警了。每一个都好离谱又恐怖,李沁都没牙齿了。不会整就不要整啊,太抽象了,我真的是哈哈哈哈哈哈哈。第一个胡歌出来我就没绷住。笑死我了,满脑子都是
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉