
大家好,我是肆〇柒。本文一篇来自阿里巴巴通义实验室(Tongyi Lab, Alibaba Group)的研究,是通义 Deepresearch 发布的系列研究之一。
这篇论文不仅推出了一个名为WebResearcher的新型AI智能体,更重要的是,它提出了一种名为"IterResearch"的全新范式,期望从根本上解决长程推理任务中的核心瓶颈。
在人工智能向通用智能(AGI)迈进的征途中,让模型从被动的知识消费者,转变为能主动探索、验证与合成新知识的研究者,已成为一个关键转折点。近年来,"深度研究"(Deep Research)智能体的兴起,正是这一趋势的集中体现。然而,当任务复杂度持续攀升,当前主流系统所依赖的"单上下文线性累积"范式正日益显露出其结构性瓶颈——认知工作区被历史信息淹没,早期错误如病毒般持续污染后续推理。
在此背景下,阿里巴巴通义实验室推出的WebResearcher,并非一次简单的性能优化,而是一场针对长程智能体底层逻辑的范式革命。其核心贡献"IterResearch"通过将研究过程重构为一个可迭代、可重置的循环,从根本上解决了旧范式的两大顽疾:"认知工作区窒息"与"不可逆噪声污染"。这不仅带来了性能上的飞跃,更重新定义了我们构建下一代AI智能体的方式。
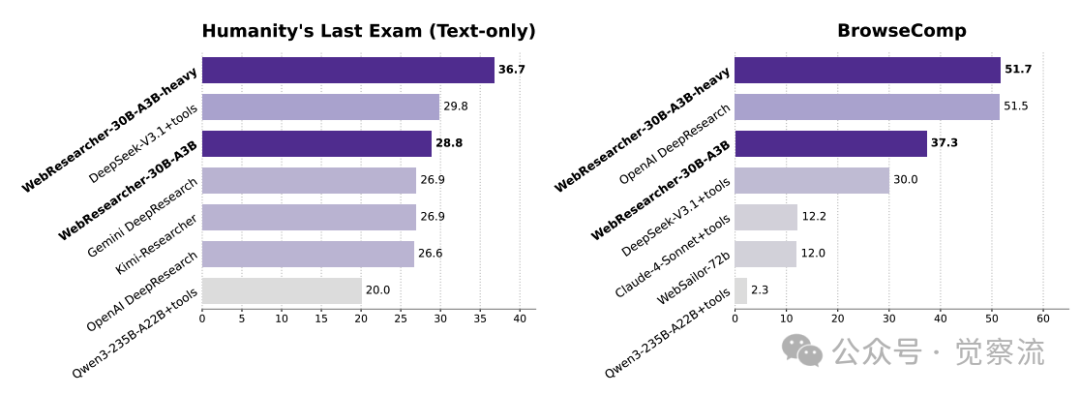
WebResearcher 与顶尖深度研究智能体的性能对比
上图直观展示了这一革命性突破:在被誉为"人类最后的考试"(Humanity's Last Exam, HLE)的顶级学术挑战中,WebResearcher-heavy(使用Qwen3-235B-A22B作为骨干模型的版本)以**36.7%的准确率大幅领先第二名DeepSeek-V3.1(29.8%);在复杂的网页导航任务BrowseComp-en上,它达到51.7%**的准确率,与OpenAI的闭源系统打成平手,同时将最佳开源系统DeepSeek-V3.1(30.0%)远远抛开21.7个百分点。这些数据清晰表明,WebResearcher已建立起不可忽视的性能壁垒。
长程智能体的"范式瓶颈"——从量变到质变的临界点
回顾近期开源与闭源领域涌现的代表性深度研究智能体,无论是OpenAI的Deep Research、Google的Gemini Deep Research,还是WebThinker、WebSailor等开源项目,它们普遍采用了一种看似直观的"单上下文线性累积"架构。在这种模式下,智能体每一步的思考、工具调用结果和检索到的信息,都会被无差别地追加到一个不断膨胀的上下文窗口中。
这一范式在解决中等复杂度问题时取得了显著成功,是AI Agent能力演进过程中不可或缺的"量变"阶段。然而,随着任务向多跳、跨域、长周期的方向发展,这种线性累积的弊端愈发明显。首先,是"认知工作区窒息"(Context Suffocation):随着上下文窗口被历史信息填满,留给模型进行深度推理的空间急剧压缩,迫使智能体在信息尚未充分消化时就做出仓促结论。其次,是"不可逆噪声污染"(Irreversible Noise Contamination):一旦引入无关信息或出现初始判断错误,这些"噪声"会永久滞留在上下文中,无法被修正或过滤,导致后续所有推理都建立在错误的基础之上,形成雪崩式的误差传播。
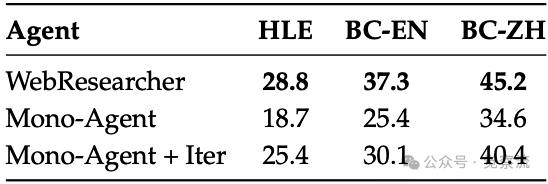
在 HLE、BC-EN 和 BC-ZH 基准上,不同智能体的核心对比结果
上表显示,在HLE基准测试中,单上下文智能体(Mono-Agent)的准确率仅为18.7%,而采用IterResearch范式的WebResearcher-30B-A3B则达到28.8%,差距高达10.1个百分点。这一定量证据有力地证明,旧范式的缺陷已无法通过简单的模型升级或数据扩充来解决。
这两个缺陷揭示了一个深刻的悖论:智能体越是努力搜集信息来解决问题,其用于处理信息的推理能力反而越弱。这标志着行业已抵达一个必须进行"范式转移"的临界点。WebResearcher的价值,正在于它没有选择在旧范式上修修补补,而是彻底颠覆了研究过程的建模方式,提出了一套名为"IterResearch"(Iterative Deep-Research Paradigm的缩写)的全新架构,开启了一场从"线性累积"到"迭代合成"的深刻变革。
解构革命——IterResearch的MDP内核与工程实现
要理解IterResearch的革命性,最直观的方式是对比其与传统范式的工作流差异。
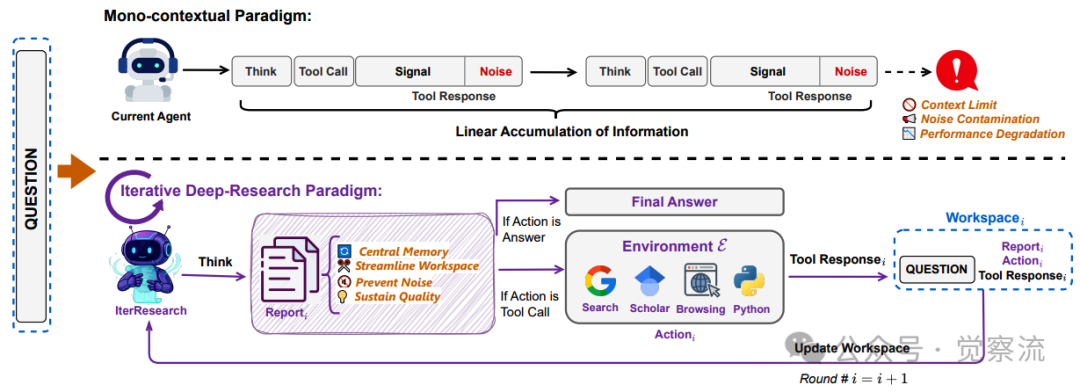
“迭代式深度研究范式”与主流“单语境范式”的对比示意图
上图清晰地展示了这一点。左侧的传统范式如同一条不断增粗的河流,所有信息汇成一股洪流,最终因体量过大而变得迟缓浑浊;右侧的IterResearch则像一个精密的循环系统,每一圈都进行提炼与净化,确保流动的是高纯度的"知识精华"。
这一精妙设计的理论基石,是将整个研究过程形式化为一个马尔可夫决策过程(Markov Decision Process, MDP)。在每个研究轮次 ,智能体的状态 被严格限定为三个核心组件:
1. 原始问题(Question):贯穿始终的研究目标。
2. 进化报告(Report_{i-1}):上一轮生成的、融合了所有关键发现的摘要。
3. 最新工具响应(Tool Response_{i-1}):上一轮动作的直接反馈。
这种精简状态的设计,完美满足了MDP的马尔可夫性——当前决策仅依赖于当前状态,而非冗长的历史轨迹。状态间的转换通过一个"重建"函数完成:丢弃临时的思考草稿和过时的交互细节,只保留经过提炼的Report和最新的Tool Response,从而为下一轮推理构建一个轻盈、聚焦的认知工作区。
在工程实现上,IterResearch通过一套结构化的元信息框架来指导每一轮的行为:
- Think:这是本轮的"认知草稿",智能体在此分析当前状态、反思进展并规划下一步。它的存在保证了推理的透明性和完整性,但关键在于,Think的内容不会进入下一个状态,避免了思维碎片对后续工作的干扰。
- Report:这是整个范式的灵魂所在,扮演着"中央记忆"和"知识蒸馏器"的双重角色。智能体并非简单地将新发现追加到报告末尾,而是必须将其与现有知识进行主动整合,解决潜在冲突,更新结论,生成一份连贯、高密度的摘要。例如,当新检索到的信息与现有知识矛盾时,智能体需评估证据强度并更新报告。通过强制性合成,Report始终保持紧凑(通常小于500 tokens),确保后续轮次有充足空间进行深度推理。这个强制性的"合成"步骤,是阻断噪声、实现知识提纯的核心机制。
- Action:基于Think的分析和Report的总结,智能体决定采取具体行动,即调用外部工具(如搜索、浏览、代码执行)或给出最终答案。
这一设计带来了优势:无论研究进行多少轮,智能体的认知工作区大小恒定,推理能力永不衰减,实现了理论上"无界"的研究深度。同时,通过Report的迭代更新,早期错误可以被识别和修正,噪声被有效过滤,整个研究过程呈现出"单调信息增益"的良性进化态势。
更值得注意的是,这一范式为训练方法带来了创新空间。在训练过程中,IterResearch采用拒绝采样微调(Rejection Sampling Fine-Tuning)策略,严格筛选仅保留最终答案与参考答案完全匹配的轨迹进行训练,确保模型学习到端到端正确的推理过程。这意味着,即使某条轨迹前90%的推理正确,但最终答案错误,整条轨迹也会被"拒绝"。这种"结果导向"的筛选确保了模型学习到的是端到端正确的推理过程,而非部分正确的片段。
此外,迭代范式天然产生的多轮次样本为强化学习提供了丰富素材。每个研究问题可产生∑gG=1 T(i)g个训练样本,实现了显著的数据放大效应,这是单上下文方法无法企及的优势。然而,可变长度轨迹的训练挑战需要特殊处理,IterResearch采用最小损失下采样技术:这一技术确保了分布式训练稳定性,同时最小化数据损失(通常<1%),是实现高效训练的关键工程细节。
通过Group Sequence Policy Optimization (GSPO),IterResearch能够优化多轮次推理策略。在这一框架下,所有∑gG=1 Tg轮次形成一个训练组,实现高效的批量训练,同时保持组级别的优势归一化。这种设计与传统GSPO不同——传统方法将每条轨迹单独处理,而IterResearch利用轨迹的自然分解,将每轮视为独立训练样本,同时保持所有轮次的组级优势归一化,最大化数据利用效率,确保在不同研究深度上实现均衡学习,为长程推理提供了坚实的训练基础。
实证革命——数据与行为分析揭示的统治力
理论的优势需要实验的检验。为了剥离模型、数据等因素的影响,研究团队进行了严谨的消融实验。
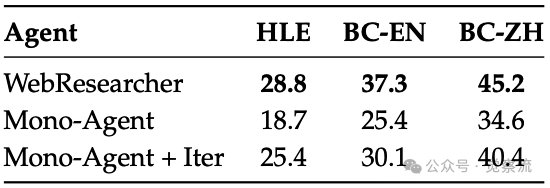
在 HLE、BC-EN 和 BC-ZH 基准上,不同智能体的核心对比结果
上表对比了三种配置:基础的"Mono-Agent"(单上下文)、使用IterResearch训练数据的"Mono-Agent+ Iter",以及完整的"WebResearcher"(迭代范式)。
结果显示,"Mono-Agent+ Iter"相比基础版有稳定提升,这证明了WebFrontier数据引擎本身具有普适价值,能增强任何模型的工具使用能力。然而,最关键的差距体现在"Mono-Agent+ Iter"与"WebResearcher"之间。例如,在HLE基准上,WebResearcher-30B-A3B以28.8%的成绩领先"Mono-Agent+ Iter"25.4%。这一"决定性优势"无可辩驳地证明,性能的飞跃主要源于
架构范式本身的优越性,而非仅仅是数据质量的提升。旧范式下的线性累积,终究无法克服其内在的"语境退化"和"不可逆错误传播"两大致命伤。
更令人信服的是对智能体行为的分析。在以学术问答为主的HLE基准上,智能体策略高效而精准,平均仅需4.7个回合即可解决问题,且大量使用学术文献搜索(Scholar)工具。而在需要复杂网页导航的BrowseComp基准上,智能体展现出了惊人的持久力,平均每个任务耗时高达61.4个回合,搜索(Search)和页面访问(Visit)成为主导工具。这种根据任务本质自适应调整研究策略的能力,正是IterResearch赋予智能体的高级认知特征,是被"窒息"工作区所束缚的旧范式智能体难以企及的。
特别值得注意的是工具调用模式的差异:在HLE任务中,Scholar工具占所有工具调用的25.4%,反映了对专业学术资源的精准利用;而在BrowseComp任务中,Search和Visit工具分别占56.5%和39.7%,共同构成了96%以上的工具调用。这清晰表明,IterResearch能够根据任务需求动态调整其工具使用策略,实现真正的"任务感知"行为。
支撑革命——数据引擎与推理框架的协同创新
一场成功的革命,离不开充足的"弹药"和高效的"战术"。WebResearcher的成功,还得益于两大关键支撑:为其"造血"的数据引擎WebFrontier,以及实现测试时扩展的推理框架Research-Synthesis。
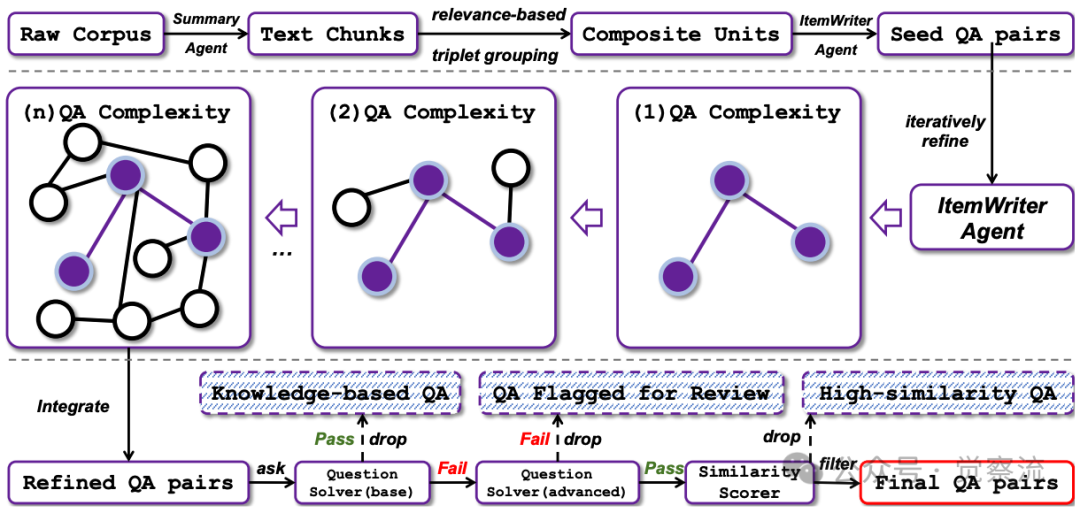
多智能体系统驱动的三阶段数据合成流程总览
上图清晰展示了WebFrontier的三阶段闭环流程:从原始语料库开始,经过"相关性分组"形成"复合单元",再由ItemWriter Agent生成初始问答对;随后进入迭代循环,工具增强的ItemWriter Agent不断升级问题复杂度;最后通过多阶段质量控制确保数据质量。
WebFrontier直面高质量长程任务数据稀缺的行业难题。其创新之处在于一个三阶段的闭环流程:种子生成、工具增强的复杂度升级和严格的质量控制。其中最核心的是"自举"(refinement loop)机制:一个配备了搜索、浏览、代码解释器等工具的智能体,能够将一个简单的种子问题,通过四个关键步骤系统性地升级为复杂的、需要多源信息合成的研究问题:
1. 知识扩展:查询外部源拓宽问题范围。例如,将"量子计算的基本原理"扩展为"量子纠错码在超导量子计算机中的实现挑战及其对Shor算法的影响"。
2. 概念抽象:提炼高层原理、识别跨域关系。如从具体实验数据中归纳出"量子退相干时间与量子比特数量的指数关系"。
3. 事实验证:通过多源交叉验证确保答案准确性,同时比对arXiv论文、权威教科书和实验数据集。
4. 计算公式化:利用Python环境创建需定量计算的问题,如"基于公开的LIGO数据,计算GW150914事件中黑洞合并释放的能量相当于多少个太阳质量"。
这一过程本身就模拟了人类研究者的思维方式,生成的数据不仅规模大、质量高,而且天然契合IterResearch的"探索-合成"循环理念。更关键的是,WebFrontier产生的训练数据能显著提升任何模型(包括旧范式)的工具使用能力,凸显了新范式对整个生态的赋能作用。
值得注意的是,WebFrontier的数据生成过程与IterResearch范式高度一致,都遵循"探索-合成-再探索"的循环逻辑。这种内在一致性确保了训练数据与推理范式的完美匹配,是性能飞跃的隐藏关键。在质量控制阶段,WebFrontier采用双重验证机制确保数据质量:
- 基线验证:QuestionSolver Agent在无工具模式下尝试回答,过滤掉过于简单的问题
- 高级验证:同一Agent在工具增强模式下重新尝试,仅保留能被工具增强型Agent解决但基线模型无法解决的问题
此外,SimilarityScorer Agent会过滤与现有数据语义冗余的新生成对,保持数据集多样性。这种精准定位"能力间隙"(capability gap)的机制,确保了生成的数据既具有挑战性又可解,为训练高质量智能体提供了坚实基础。
Research-Synthesis框架则解决了测试时扩展的难题。直接聚合多条完整研究轨迹的上下文成本极高。该框架的巧妙之处在于,利用"最终报告"作为高密度信息载体。
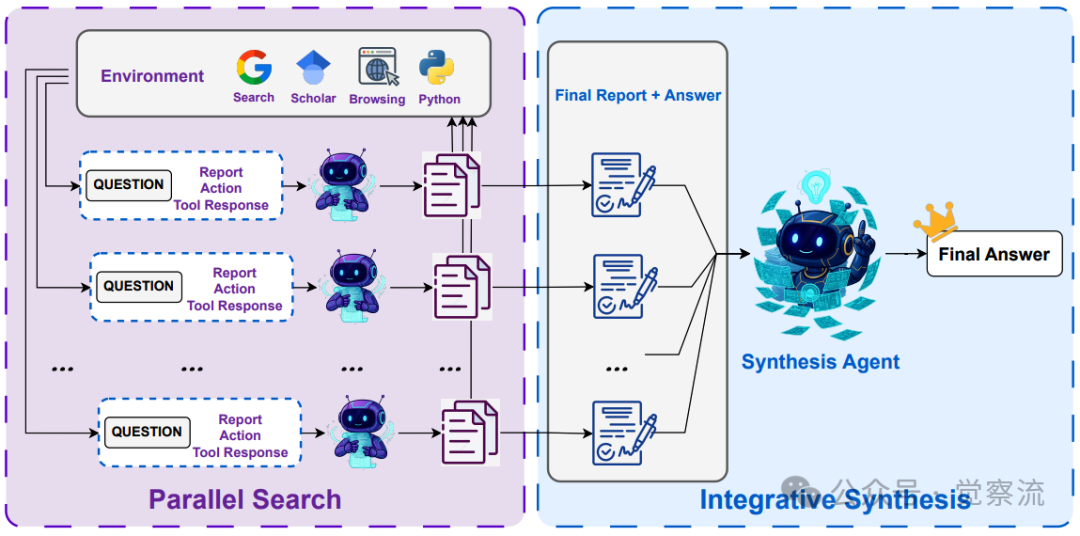
推理—综合框架图解
上图生动展示了这一过程:在"并行研究"阶段,多个Research Agent独立探索,各自生成一份浓缩了全部推理路径的报告;在"集成综合"阶段,一个专门的"综合代理"(Synthesis Agent)只需阅读这些报告,即可融合不同视角,得出更全面、稳健的结论。
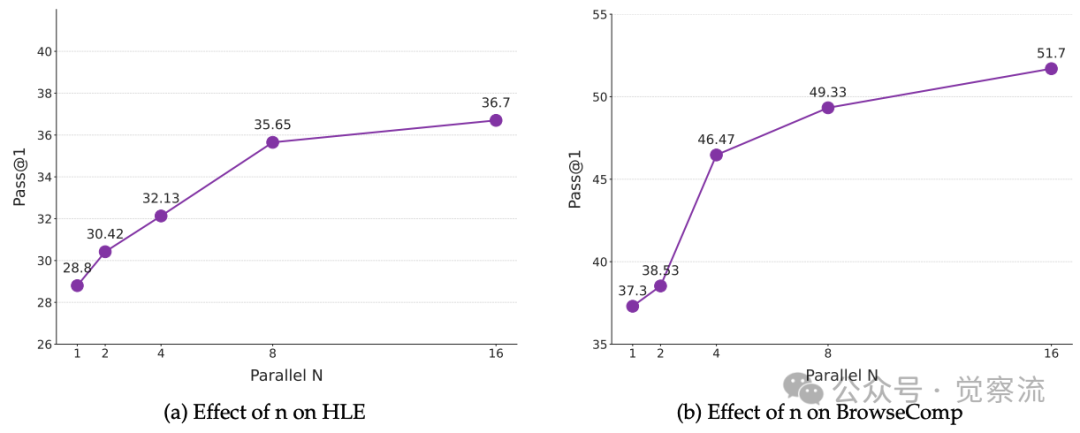
Reason-Synthesis Framework 中 n 值的影响
上图显示,随着并行智能体数量 的增加,性能持续提升,但存在明显的边际效益递减。当 从1增加到8时,HLE准确率从28.8%跃升至35.65%,但 时仅微增至36.7%。这为实际部署提供了清晰的成本-收益权衡方案,使架构师能够在性能提升与计算成本之间找到最佳平衡点。
深入分析上图揭示的规律表明,8个并行智能体已能捕获绝大多数的性能增益,为实际部署提供了明确的成本效益拐点。这种"边际效益递减"规律对系统架构师设计生产环境具有直接指导价值,而不仅是学术观察。
WebResearcher配备了四类专业工具,每类工具都经过精心设计以支持高效研究:
- Search工具:支持批量查询,返回每个查询的前10个结果,包含标题、摘要和URL,便于快速评估相关性
- Scholar工具:提供学术文献的作者、出版 venue 和引用计数等元数据,支持高效学术研究
- Visit工具:基于Jina.ai实现目标导向的网页内容提取,代理提供URL和提取目标(如"查找实验结果"),工具首先检索完整内容,然后使用Qwen3基于指定目标生成聚焦式摘要,避免信息过载
- Python工具:在沙盒环境中执行代码,支持数据分析和可视化库,所有输出明确打印以确保计算结果清晰呈现
特别是Visit工具的"目标导向摘要"机制,直接解决了传统网页浏览中信息过载的问题,是支撑IterResearch范式的关键基础设施。这些工具系统的设计细节,展现了WebResearcher工程实现的成熟度,使其能够处理真实的长程研究任务。
影响革命——Benchmark统治力与行业启示
在6项极具挑战性的基准测试中,WebResearcher展现了统治级的表现,为这场范式革命提供了最强有力的背书。这些结果不仅体现在绝对性能上,更体现在多维度的适应性上。
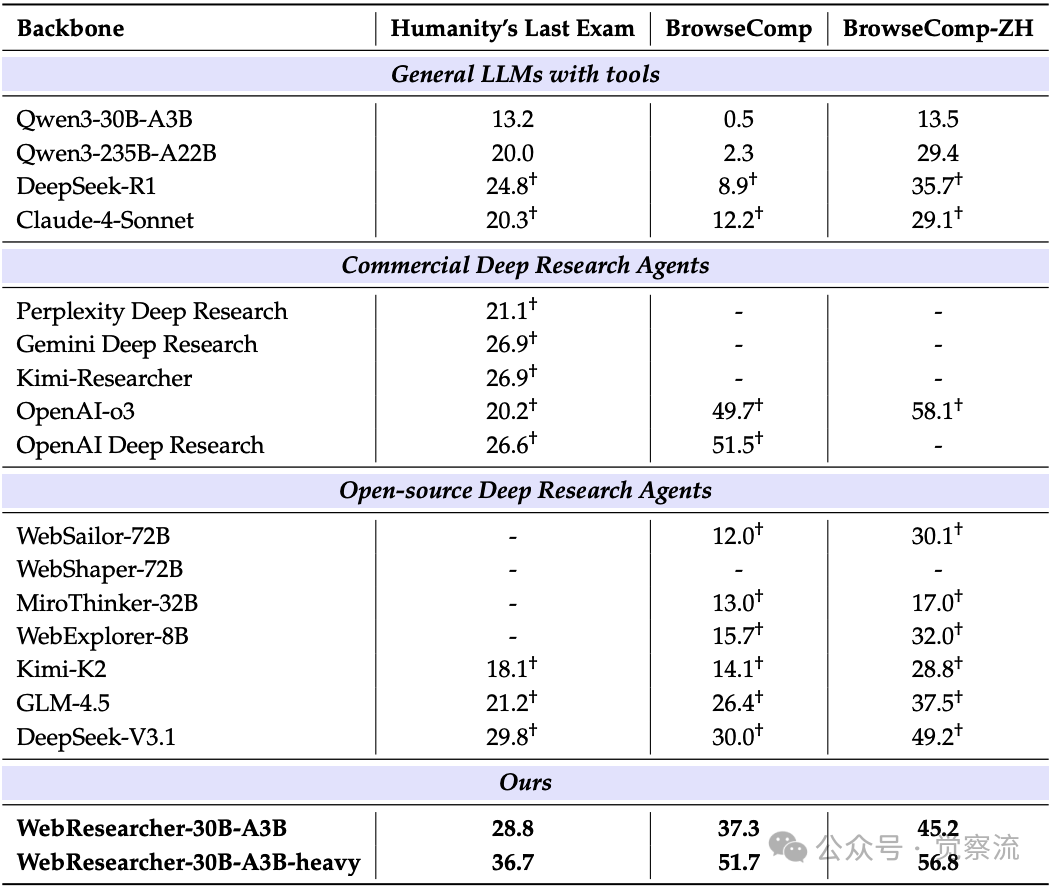
在通用网页导航与推理基准测试中的表现
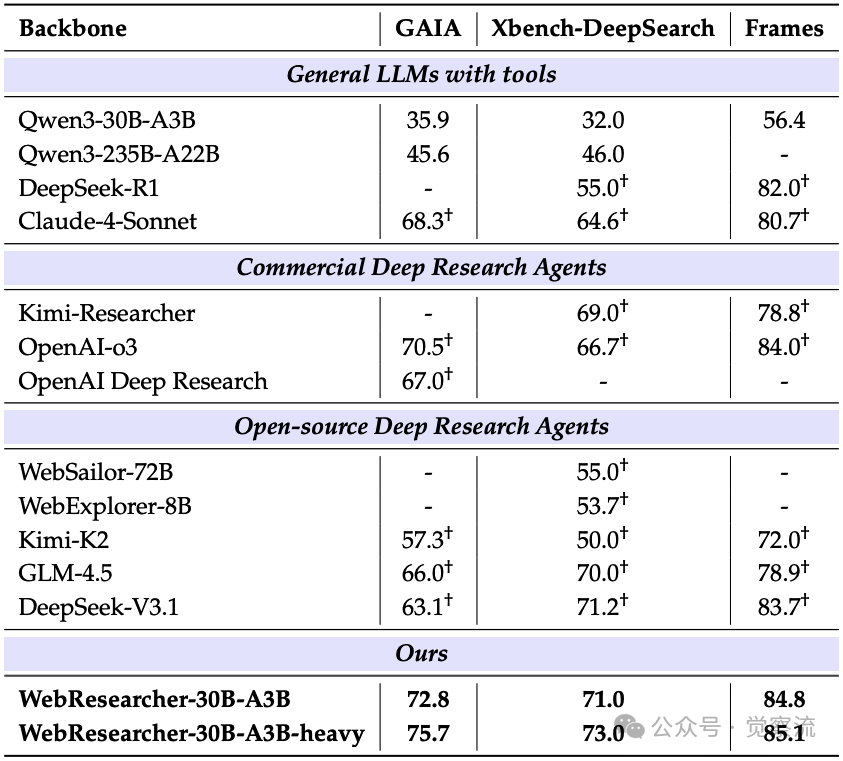
在面向目标的复杂网络任务基准测试中的结果
上表全面展示了WebResearcher在不同任务类型上的表现。在通用网络导航与推理基准(HLE、BrowseComp)上,WebResearcher-heavy取得了**36.7%的准确率,大幅超越了DeepSeek-V3.1(29.8%)和OpenAI Deep Research(26.6%),彰显了其在深度知识合成方面的绝对优势。在复杂的网页导航任务BrowseComp-en上,它达到了51.7%**的准确率,与OpenAI的闭源系统持平,同时将最佳开源系统DeepSeek-V3.1(30.0%)甩开21.7个百分点。在中文网页导航任务BrowseComp-zh上,它同样表现出色,达到56.8%的准确率,接近OpenAI-o3的58.1%,显著优于DeepSeek-V3.1的49.2%。这些结果证明,IterResearch通过结构化的合成过程,能够有效处理跨语言信息源,避免了单上下文系统在积累多语言内容时常见的混淆问题。
在复杂目标导向网络任务(GAIA、Xbench-DeepSearch、Frames)上,WebResearcher同样展现出卓越能力。在GAIA基准上,它以75.7%的准确率超越所有评估系统,包括Claude-4-Sonnet(68.3%)和OpenAI-o3(70.5%),领先优势高达9.7个百分点。在Xbench-DeepSearch上,它达到73.0%的准确率,超越DeepSeek-V3.1(71.2%)和其他开源替代方案。在Frames基准上,它以85.1%的准确率领先DeepSeek-V3.1(83.7%)和OpenAI-o3(84.0%)。
这些数据背后揭示了一个重要规律:在需要复杂多步推理的任务中,IterResearch的优势更加显著。这正是因为这些任务最能体现其核心价值——通过周期性合成和工作区重建,维持高质量推理能力于整个研究过程。相比之下,单上下文系统随着研究轮次增加,性能会逐渐下降,这在BrowseComp任务中尤为明显(平均61.4轮),而IterResearch仍能保持稳定输出。
这一成功带来的启示深远:
- 对研究者而言,未来的竞争焦点将从单纯的模型规模竞赛,转向智能体架构的创新。IterResearch提供了一个可复用的优秀模板。
- 对系统架构师而言,"迭代合成"和"周期性知识蒸馏"的思想具有极强的普适性,有望迁移到机器人控制、长期规划等其他长程决策场景。
- 对AGI的发展而言,WebResearcher通过模拟人类研究者的核心工作流,推动了AI从"信息检索者"向"知识建筑师"的转变,为构建真正具备自主学习与创造能力的通用智能体铺平了道路。
总结:拥抱迭代合成的新时代
WebResearcher不是一次渐进式的改良,而是一场由第一性原理驱动的范式革命。它深刻地认识到,当"量变"积累到一定程度,原有的架构终将触及天花板。唯有回归"如何进行有效研究"这一本质问题,重新设计智能体的底层运行逻辑,才能实现真正的"质变"。
IterResearch通过将研究过程解耦为"探索"与"合成"两个相辅相成的阶段,创造性地解决了长程推理的可持续性难题。实验结果表明,IterResearch在多项基准测试上达到了state-of-the-art性能,甚至超越了前沿闭源系统,验证了迭代合成范式在长程推理任务中的有效性。
值得注意的是,IterResearch范式产生的训练数据能显著提升传统单上下文方法的性能,这表明其设计理念对整个AI智能体生态具有广泛的赋能作用。这种"架构即数据"的良性循环,将加速整个领域的进步。


