The Silicon Cloud (SiliconFlow) has officially launched the world's first open-source large-scale hybrid attention reasoning model — MiniMax-M1-80k (456B). This innovative model is designed to provide strong support for complex tasks such as software engineering, long-context understanding, and tool usage, and its performance can rival leading models like o3 and Claude4Opus.
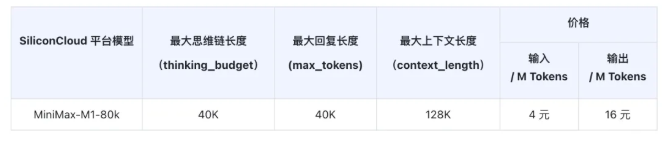
It is reported that MiniMax-M1-80k supports a maximum context length of up to 128K, greatly facilitating the handling of long texts. For users with special needs, the platform also provides backend support to meet the demand for 1M long contexts. The cost of using this model is ¥4 per million tokens for input and ¥16 per million tokens for output. New users can enjoy an experience bonus of 14 yuan when they first use it.
The MiniMax-M1-80k model is developed based on MiniMax-Text-01, adopting a hybrid expert system (MoE) architecture and Lightning Attention mechanism, featuring an efficient reinforcement learning expansion framework. This design allows the model not only to handle traditional mathematical reasoning tasks but also to function in real sandbox software development environments. Therefore, it becomes an ideal choice for tasks requiring long text processing and deep thinking.
In terms of performance, MiniMax's benchmark tests show that the model consumes only 25% of the FLOPs of DeepSeek R1 when generating 100,000 tokens, indicating its highly efficient inference scaling. Meanwhile, MiniMax-M1-80k's evaluation results in areas such as mathematics, programming, tool usage, and long-context understanding are on par with top-tier models like o3.
SiliconCloud, as an all-in-one large model cloud service platform, is committed to providing developers with high-quality services. In addition to MiniMax-M1-80k, the platform has launched several excellent models, including DeepSeek-R1-0528, Qwen3, GLM-4 series, etc., greatly enriching developers' options. Especially the distilled version of DeepSeek-R1 and other multiple models are available for free use, helping developers achieve "Token freedom."
To experience the newly launched MiniMax-M1-80k, users can access it online or integrate it through the official website of SiliconCloud, further promoting the development of generative AI applications.
Online Experience
https://cloud.siliconflow.cn/models
Third-party Application Integration Tutorial
https://docs.siliconflow.cn/cn/usercases/