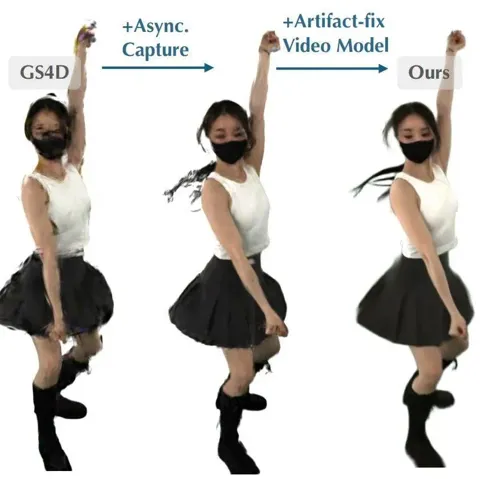
第一作者徐源诚是 Netflix Eyeline 的研究科学家,专注于基础 AI 模型的研究与开发,涵盖多模态理解、推理、交互与生成,重点方向包括可控视频生成及其在影视制作中的应用。他于 2025 年获得美国马里兰大学帕克分校博士学位。
最后作者于宁是 Netflix Eyeline 资深研究科学家,带领视频生成 AI 在影视制作中的研发。他曾就职于 Salesforce、NVIDIA 及 Adobe,获马里兰大学与马普所联合博士学位。他多次入围高通奖学金、CSAW 欧洲最佳论文,并获亚马逊 Twitch 奖学金、微软小学者奖学金,以及 SPIE 最佳学生论文。他担任 CVPR、ICCV、ECCV、NeurIPS、ICML、ICLR 等顶会的领域主席,以及 TMLR 的执行编辑。
在电影与虚拟制作中,「看清一个人」从来不是看清某一帧。导演通过镜头运动与光线变化,让观众在不同视角、不同光照条件下逐步建立对一个角色的完整认知。然而,在当前大量 customizing video generation model 的研究中,这个最基本的事实,却往往被忽视。

论文地址: https://arxiv.org/pdf/2510.14179
项目主页: https://eyeline-labs.github.io/Virtually-Being/
被忽视的核心问题:Multi-view Identity Preservation

多视角身份一致、镜头环绕与多人物示例
近年来,视频生成领域中关于人物定制(customization)的研究迅速发展。绝大多数方法遵循一种相似范式:给定一张或少量人物图像 → 生成包含该人物的视频。这种范式隐含了一个关键假设:只要人物在某个视角下看起来像,就等价于「身份被保留」。但在真实的视频与电影语境中,这个假设并不成立。
为什么单视角身份是不够的?
身份是强烈依赖视角的(view-dependent)
面部轮廓、五官比例、体态与衣物形态,都会随观察角度发生系统性变化。
相机运动会持续暴露未见过的外观区域
单张或少量图像无法覆盖侧脸、背面以及连续视角变化过程中的外观一致性。
多人场景会放大任何身份错误
当多个角色同框时,哪怕轻微的身份漂移都会变得非常明显。
因此,在具有真实 3D 相机运动的视频中,「identity preservation」本质上是一个 multi-view consistency 问题,而不是单帧相似度问题。
然而,令人遗憾的是,显式关注 multi-view identity preservation,在当前的视频定制化生成研究中仍然几乎没有被系统性地解决。
核心立场:学习一个人的身份,必须学习他在多视角与多光照下的样子
Virtually Being 的核心论点非常明确:如果希望模型真正「学会一个人的身份」,那么它必须看到这个人在不同视角(multi-view)和不同光照(various lighting)下的稳定外观。
换句话说,看清一个人,不是看清一张脸,而是理解这个人在空间中如何被观察,在光线变化下如何呈现。身份不是一个静态的 2D 属性,而是一个 4D(空间 + 时间)一致的概念,这正是 Virtually Being 所要系统性解决的问题。
方法概览:用 4D 重建构建真正的多视角身份监督
为了解决 multi-view identity 被长期忽视的问题,我们从数据层面重新设计了人物定制流程。
多视角表演采集,而非单视角参考
使用专业体积捕捉系统采集真实人物表演:75 相机面部捕捉阵列、160 相机全身捕捉阵列;
捕捉人物在受控条件下的动态表演,为高质量重建提供输入。
4D Gaussian Splatting 作为数据生成器
对捕捉到的表演进行 4D Gaussian Splatting (4DGS) 重建;
在重建结果上渲染大量视频:覆盖连续变化的相机轨迹、具备精确的 3D 相机参数标注、保证同一人物在不同视角下的身份一致性。
通过这一过程,视频生成模型在训练阶段不再依赖零散的图像线索,而是反复观察同一个人在多视角、连续镜头运动下应当如何保持外观一致。
两阶段训练:先理解镜头,再理解「这个人」
为了在身份定制的同时保持稳定的镜头控制能力,我们采用了一个清晰解耦的两阶段训练策略。
阶段一:相机感知预训练(Camera-aware Pretraining)
基于 ControlNet 架构,引入完整 3D 相机参数(Plücker 表示),在大规模公开视频数据上训练模型,使其学会相机运动如何影响视角变化与时间结构。这一阶段的目标,是让模型牢固掌握电影级的镜头语言。
阶段二:多视角身份定制(Multi-view Customization)
在预训练模型基础上进行微调,使用 4DGS 渲染的多视角视频作为定制数据,为每个身份引入专属 token,将身份与多视角外观显式绑定,最终模型在推理时能够精确遵循输入的 3D 相机轨迹,在未见过的视角下仍然稳定呈现同一个人。
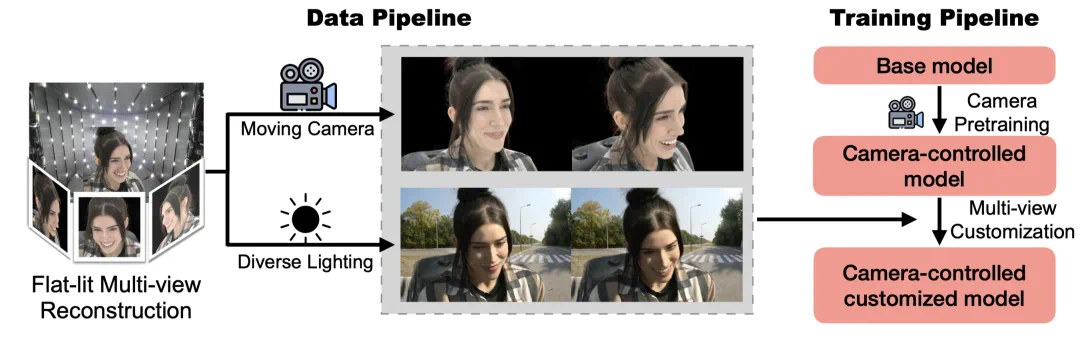
光照真实感:身份感知不可分割的一部分
除了视角,光照同样是「看清一个人」的关键维度。
在真实电影中,人物身份并不是在单一光照条件下被认知的,而是在不同室内外环境,侧光、逆光、柔光等变化,不同光比与色温条件下逐步被观众确认。
在 Virtually Being 中,我们通过引入基于 HDR 的视频重打光数据,显著增强了生成视频中的光照真实感。在 4DGS 渲染基础上,对同一人物生成多种自然光照条件,覆盖真实拍摄中常见的照明变化范围,使模型学会在光照变化下,人物身份仍应保持稳定。
实验结果显示,引入重光照数据后,生成视频在用户研究中 83.9% 被认为光照更自然、更符合真实拍摄效果,缺乏该数据时,人物往往呈现平坦、缺乏层次的合成感。
多人物生成:multi-view identity 才能支撑真实互动
在多人物视频生成中,multi-view identity preservation 的重要性进一步被放大。
只有当模型对每个角色在不同视角与光照条件下的身份都有稳定建模时,人物才能自然同框,空间关系才能保持一致,互动才不会显得拼接或混乱。
Virtually Being 支持两种多人物生成方式:
联合训练(Joint Training):通过少量同框数据增强互动真实性;
- 推理阶段组合(Noise Blending):在无需重新训练的情况下灵活组合多个身份。
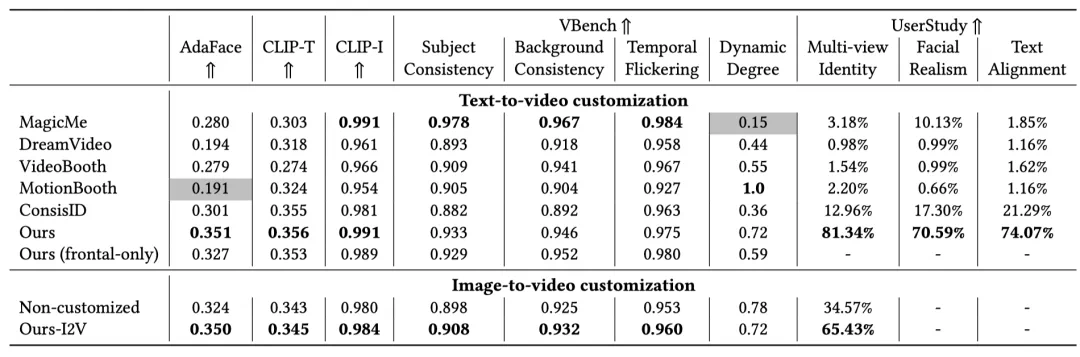
 实验结论:multi-view + relighting 是身份一致性的关键因素
实验结论:multi-view + relighting 是身份一致性的关键因素
系统性实验表明,使用 multi-view 数据训练的模型,在 AdaFace 等身份指标上显著优于仅使用 frontal-view 数据的模型以及其他 video customization 的方法。缺失 multi-view 或 relighting 数据,都会导致身份一致性与真实感明显下降。用户研究结果同样明确偏好具备 multi-view 身份稳定性的生成结果。

总结:重新定义视频生成中的「身份」
Virtually Being 并不仅仅提出了一个新框架,而是明确提出并验证了一个长期被忽视的观点:在视频生成中,身份不是一张图像,而是一个人在多视角与多光照条件下保持稳定的 4D 表现。通过系统性地引入 multi-view 表演数据与真实光照变化,我们为 customizing video generation model 提供了一条更贴近电影制作实际需求的解决路径。