
"老板,我们的模型效果怎么还是这么差?"小李拿着测试报告,一脸无奈地走进了技术总监的办公室。
"数据质量怎么样?"技术总监头也不抬地问道。
"这..."小李支支吾吾,"我们用的都是网上爬的数据,应该没问题吧?"
这...大家都在谈论算法优化、模型架构,却很少有人真正关注那个最基础、最关键的问题:数据集质量。

被忽视的数据集
最近和几个做AI的朋友聊天,发现一个有趣的现象:大家都在卷模型参数、卷算力,但很少有人愿意在数据集上下功夫。
为什么?因为数据集建设太"脏"、太"累",没有模型优化那么有技术含量,也没有那么容易出成果。
但现实很残酷。你花几个月时间调优的模型,可能还不如别人用高质量数据集训练几天的效果好。这就是数据集的威力,也是很多AI项目失败的根本原因。
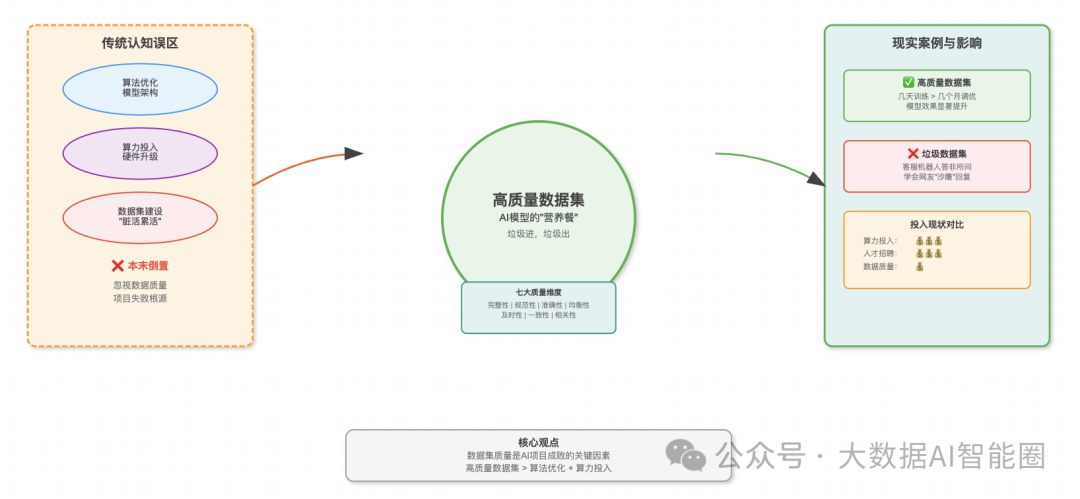
数据集不仅仅是一堆数字和文本的堆砌,它更像是AI模型的"营养餐"。你给模型喂什么样的数据,它就会学成什么样。垃圾进,垃圾出,这个道理在AI领域体现得淋漓尽致。
一个高质量的数据集需要具备完整性、规范性、准确性、均衡性、及时性、一致性和相关性等多个维度的标准。
听起来很学术,但翻译成人话就是:数据要全、要准、要新、要平衡,还要和你的应用场景高度匹配。
说起来容易,做起来难。很多公司花了大价钱买算力、招人才,却在数据质量上栽了跟头。
有个朋友的公司,用了半年时间训练一个客服机器人,结果上线后答非所问,原因就是训练数据里混入了大量无关的网络对话,模型学会了网友的"沙雕"回复风格。
中文数据荒
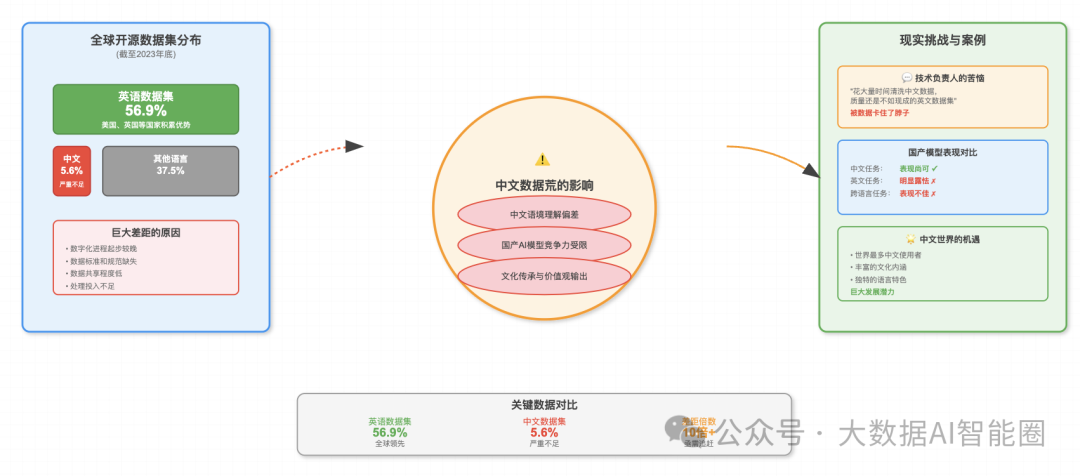
更让人担忧的是中文数据集的现状。截至2023年底,全球开源数据集中,英语占比高达56.9%,而中文仅占5.6%。这个数字背后,隐藏着一个残酷的事实:我们正在AI时代的数据竞赛中落后。
这种差距并非偶然的。美国、英国等英语国家在数字化进程中起步较早,积累了大量高质量的数字化内容。从学术论文到新闻报道,从社交媒体到企业文档,英语世界的数字化程度远超其他语言。
而中文世界呢?
虽然我们有着世界上最多的中文使用者,但高质量的中文数据集却严重匮乏。原因很复杂:数据标准缺失、共享程度低、处理投入不足,还有各种法律法规的限制。
前段时间和一个做中文大模型的团队聊天,他们的技术负责人苦笑着说:"我们花了大量时间去清洗网络爬取的中文数据,但质量还是不如人家现成的英文数据集。有时候真的很无奈,明明技术实力不差,但就是被数据卡住了脖子。"
这种数据荒的影响是深远的。当我们的AI模型主要依赖英文数据训练时,它们对中文语境的理解必然存在偏差。这不仅影响模型效果,更可能在文化传承、价值观输出等方面产生问题。
更现实的问题是,缺乏高质量中文数据集直接限制了国产AI模型的竞争力。
你看那些在国际上表现优异的大模型,哪个不是建立在海量高质量数据集基础上的?而我们的模型,往往在中文任务上表现尚可,但一到英文或者跨语言任务就露怯了。
破局之路
面对这样的现状,我们该怎么办?
抱怨没用,关键是行动。
首先要转变思维。
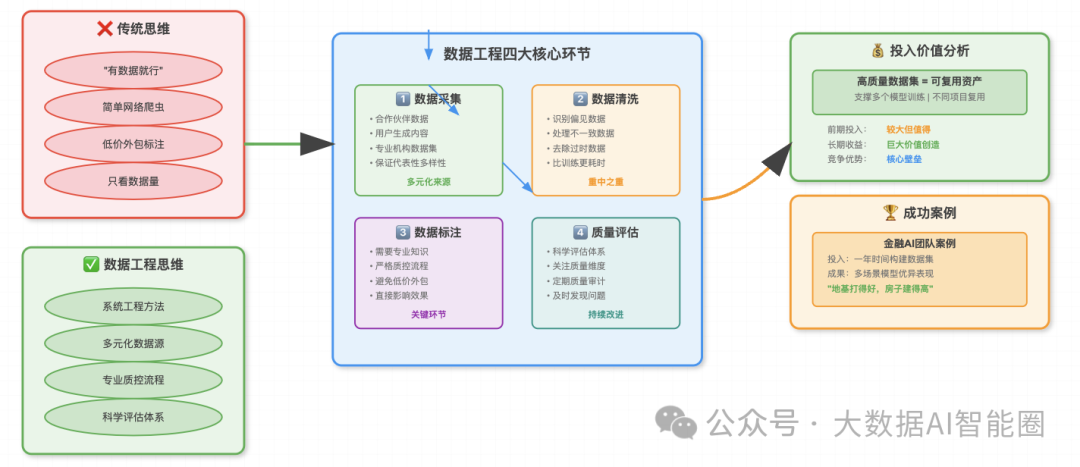
很多技术团队还停留在"有数据就行"的阶段,但真正的AI竞争已经进入了"数据工程"时代。什么是数据工程?就是把数据集建设当作一个系统工程来做,从数据采集、清洗、标注到质量评估,每个环节都要精益求精。
在数据采集阶段,不能再满足于简单的网络爬虫。
需要建立多元化的数据来源,包括合作伙伴提供的业务数据、用户生成的内容、专业机构的标准数据集等。关键是要保证数据的代表性和多样性。
数据清洗更是重中之重。很多人以为清洗就是去重、去噪,但实际上远不止如此。你需要识别和处理偏见数据、不一致数据、过时数据等各种问题。这个过程往往比训练模型还要耗时耗力,但绝对值得。
数据标注是另一个关键环节。高质量的标注需要专业知识和严格的质控流程。很多公司为了节省成本,把标注外包给价格最低的供应商,结果得到的是垃圾标注,最终影响模型效果。
质量评估则需要建立科学的评估体系。不能只看数据量,更要关注数据质量的各个维度。定期对数据集进行质量审计,及时发现和解决问题。
当然,这些都需要投入。
但这种投入是值得的,因为高质量的数据集是可以复用的资产。一个精心构建的数据集,可以支撑多个模型的训练,可以在不同项目中发挥价值。
有个做金融AI的朋友,他们团队花了一年时间构建了一个高质量的中文金融文本数据集。虽然前期投入很大,但后来基于这个数据集训练的模型在多个金融场景中都表现优异,为公司创造了巨大价值。
他说:"数据集就像是房子的地基,地基打得好,房子才能建得高。"
结语
数据集正在成为AI时代的核心竞争力。在算法日趋同质化的今天,谁拥有更高质量的数据集,谁就拥有了更强的竞争优势。
对于中文AI生态来说,我们面临的挑战是严峻的,但机遇同样巨大。中文世界有着丰富的文化内涵和独特的语言特色,如果能够建设出高质量的中文数据集,不仅能够提升国产AI模型的竞争力,更能够在全球AI竞争中占据一席之地。
这需要整个行业的共同努力。zf需要制定更加开放的数据政策,企业需要加大数据集建设的投入,学术机构需要提供更多的理论指导和技术支持。只有形成合力,我们才能在这场数据竞赛中不落人后。
数据集的建设是一场马拉松,不是百米冲刺。但只要我们开始行动,就永远不会太晚。


