
深陷数据泥潭,渴望洞察
如今,许多组织都深陷数据洪流。信息从销售系统、营销工具、运营数据库、网站以及无数其他来源涌入。然而,尽管信息浩如烟海,要获得清晰可靠的业务答案却异常困难。数据常常被困在不同的部门或系统中,难以查找、难以理解,有时甚至不可靠。这是一种常见的挫败感:原始信息量巨大,但人们真正渴望的是切实可行的洞察。
如果有更好的方法会怎样?如果组织不再将数据视为运营的技术副产品,而是将其视为产品,会怎样?这意味着将数据的“消费者”——同事、分析师、数据科学家和其他团队——视为“客户”,并专门设计数据产品以有效满足他们的需求。这种视角的转变正是一个日益受到广泛关注的概念的核心:“数据产品”。它代表着从简单地收集数据到积极管理和包装数据,使其成为有价值的可消耗资产的转变。这不仅仅是技术变革,更是对数据在业务中的作用和价值的全新思考方式。
那么,什么是数据产品?
简单来说,数据产品是为特定目的或受众设计的即用型、可靠且易于理解的数据包。想象一下,送货上门的一盒未经烹制的原料和一整套餐食的区别。餐食不仅包含食材,还包含食谱卡、营养信息,甚至可能还有一些预先切好的蔬菜——所有这些东西都能轻松准备一顿特定的饭菜。
同样,数据产品不仅仅是原始数据。它是一个独立的、可部署的单元,将数据与有效使用所需的一切捆绑在一起。这个包通常包括:
- 数据本身:核心信息,无论是原始的、清理过的、汇总的还是衍生的。
- 元数据:关于数据的数据——字段描述、定义、来源、质量指标(如产品标签)。
- 代码:用于创建或访问数据的逻辑(例如,转换脚本、API 访问代码)。
- 访问信息:如何连接和使用数据。
- 服务水平目标 (SLO):关于其质量、新鲜度和可靠性的承诺。
其核心理念是将成熟的产品开发思维应用于数据世界。它旨在从消费者的角度设计数据解决方案,以解决特定问题或实现特定分析,使其成为分析数据的最小价值单元。这是一种刻意的努力,旨在超越简单的数据存储,创造真正符合用途且自身有价值的东西。
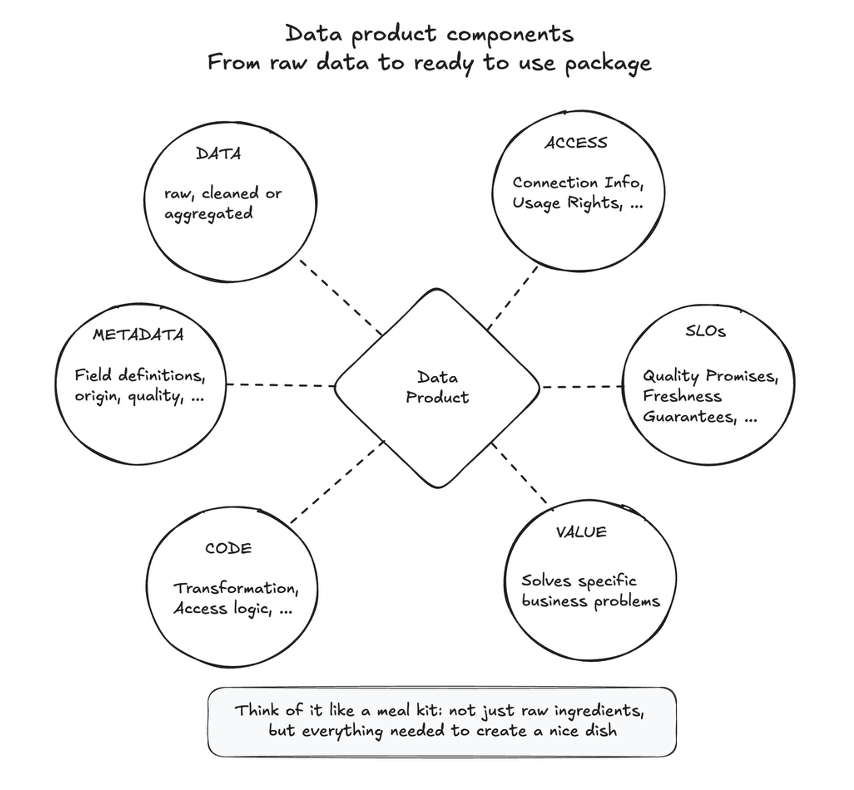
数据产品组件——从原始数据到可立即使用的包。
在数据工程中,区分数据产品与更传统的结构至关重要。例如:
传统批量加载:这类操作通常需要每晚(或定期)将大量原始数据或少量处理的数据从源系统传输到数据仓库或数据湖等中央存储库。虽然它们有助于数据整合,但通常缺乏丰富的元数据、明确的所有权、明确的服务水平目标 (SLO) 以及针对特定业务需求的直接可用性,而这些正是数据产品所特有的。消费者通常需要执行大量的下游工作才能使这些数据可用。
简单数据 API:虽然 API 提供了数据访问,但简单的 API 端点仅仅暴露原始数据表或转储数据,缺乏全面的元数据、质量保证或明确的预期用途和生命周期管理定义,因此不属于数据产品。数据产品的 API 是面向管理完善、可靠且易于理解的数据资产的接口,并包含所有支持组件。
这就是“数据契约”概念变得高度相关的地方。数据产品具有明确的服务水平目标 (SLO)、模式定义、元数据和质量保证,本质上体现了数据生产者与消费者之间的数据契约。这份契约确保消费者了解他们将获得什么、如何使用它以及他们可以期待什么样的可靠性。如果数据产品发生变化(例如,模式演变、数据语义变化),契约提供了一个框架来管理这些变化并将其传达给消费者,从而防止下游流程出现问题并增强对数据的信任。数据契约是一种机制,旨在增强数据产品理念中固有的可靠性和可信度。
数据产品理念的诞生
“数据产品”一词在 2019 年左右开始流行,这主要归功于 ThoughtWorks 的 Zhamak Dehghani。她将其作为一项核心原则——“数据即产品”——引入了更广泛的架构概念“数据网格”。
数据网格本身是一种范式转变,旨在解决数据仓库和数据湖等传统集中式数据方法的局限性,这些局限性往往会成为大型组织的瓶颈。数据网格并非由一个中心团队管理所有数据,而是倡导将数据所有权分散到特定的业务领域(例如市场营销、销售和财务)。
在这样一个去中心化的世界里,拥有定义明确、高质量、易于共享的数据单元至关重要。数据产品正是这些重要的构建块,使不同领域的团队能够有效地创建、共享和使用数据,而无需仅仅依赖一个中心化的数据团队。理解这一起源有助于阐明数据产品日益重要的原因:它们通过促进去中心化的数据共享和所有权,成为在现代复杂组织中扩展数据使用和创新的关键推动因素。
什么让数据产品脱颖而出?
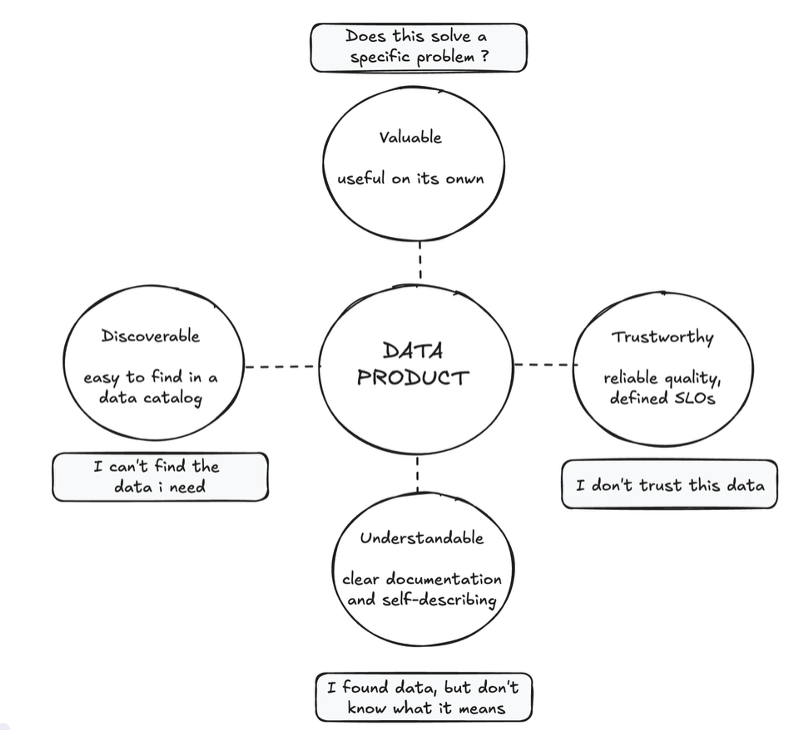
并非所有数据都能被归类为数据产品。要获得这一称号,数据需要具备某些特征,使其对消费者真正有用且可靠。这些特征直接解决了人们在处理数据时经常遇到的难题。关键特征包括:
1.可发现性:用户需要能够轻松找到与其需求相关的数据产品,就像搜索在线目录一样。这通常需要一个专门的“数据产品目录”,其中列出可用的产品并可供搜索。这解决了“我找不到我需要的数据”的问题。
2.易于理解(自描述):数据产品应提供清晰的文档和元数据,解释其内容、字段含义、创建方式及其预期用途——就像清晰的产品标签一样。这解决了“我找到了数据,但不知道它的含义或是否适合我”的难题。
3.值得信赖:消费者必须对数据的质量、准确性和时效性充满信心。数据产品通过公开其质量标准(通常定义为服务级别目标,简称 SLO)及其达成情况来实现这一点。可以将其视为一个以可靠性著称的值得信赖的品牌。这可以消除“我不信任这些数据”的顾虑。
4.自身价值:数据产品应该提供内在价值,无需与许多其他数据集结合才能发挥作用。它代表着一个有凝聚力且有意义的信息概念。这确保用户能够立即获得有用的信息,而不仅仅是需要复杂组装的原始零件。
其他重要特性通常包括可寻址(具有唯一且稳定的位置)、可访问(可通过 SQL 或 API 等标准工具使用)、可互操作(易于与其他数据产品结合)以及安全性(具有适当的访问控制)。这些特性共同构成了数据产品生产者与其消费者之间的“合同”,确保了良好的用户体验。
实际数据产品案例
数据产品并非仅限于理论;它们以多种形式存在,通常为常见的应用程序和业务流程提供支持。它们远不止简单的数据集。例如:
基于洞察的产品:这些产品提供可供决策的已处理信息。
销售绩效仪表板显示为销售经理精心挑选的收入、渠道和区域绩效等关键指标。
自动为银行客户计算信用风险评分,以简化贷款申请。
YNAB 或 Mint 等应用程序提供的个人理财洞察,分析消费模式。
算法/自动决策产品:这些产品使用数据来驱动自动化操作或复杂的建议。
Netflix 或 Amazon 等平台上的推荐引擎根据用户行为推荐电影或产品。
预测分析工具,例如 Zillow 估算房屋价值或预测客户流失的模型。
GPS 导航应用程序提供实时路线指引。
基于主数据的产品:这些产品提供了关键业务实体的综合、标准化视图。
精心策划的“黄金客户记录”数据集结合了来自 CRM、销售和支持系统的信息,用于营销的统一客户视图。
数据集/数据即服务产品:这些产品通常通过 API 提供对精选数据或原始数据的访问。
各种应用程序用来显示天气信息的天气预报 API。
用于电子商务的动态定价产品数据集,根据库存水平和到期日期调整价格。
清理并记录以电子表格或数据库表形式提供的竞争对手定价数据。
这些示例展现了数据产品的多样性。无论是简单的报告、复杂的机器学习模型,还是基础数据集,其共同点在于运用“产品思维”——设计、打包和管理数据资产,以实现可用性、可靠性和价值。
小结:为什么要关心数据产品
将数据视为产品不仅仅是采用新的术语;它是一种克服常见数据挑战的实用方法。通过关注数据消费者的需求并运用产品管理原则,组织可以使其数据更加:
- 可发现:人们更容易找到他们需要的东西。
- 易于理解:含义和背景更清晰。
- 值得信赖:更高的质量和可靠性。
- 可访问且可用:更轻松地集成到分析和工作流程中。
数据产品的最终目标是打破数据孤岛,促进协作,并赋能组织内更多人员有效利用数据,从而做出更优、更快速的决策。它有助于将数据从复杂的技术挑战转变为随时可用的资产,从而推动创新并创造切实的商业价值。
未来展望:数据产品和代理人工智能的兴起
随着代理人工智能 (Agentic AI) 的快速发展,数据产品的基本原则将变得更加重要。代理人工智能系统旨在通过与环境交互并利用各种工具自主实现目标,这在很大程度上依赖于可靠、可理解且可操作的数据。
数据产品如何对 Agentic AI 的使用和采用产生积极影响:
- 赋能自主代理:人工智能代理需要高质量、丰富的上下文数据来做出明智的决策并有效地执行任务。数据产品本质上可以提供以下功能:
- 可发现性:代理可以通过数据产品目录以编程方式找到所需的数据。
- 可理解性:丰富的元数据使代理能够正确解释数据。
- 可信度: SLO 和质量保证确保代理根据可靠的信息进行操作,减少错误并提高自主行动的效率。
- 可访问性:标准化的访问机制(如为数据产品设计的 API)使代理更容易使用数据。
- 支持复杂工具的使用: Agentic AI 通常依赖于多种工具和数据源。数据产品可以作为客服人员工具包中标准化、可靠的“工具”。例如,负责市场分析的客服人员可以无缝访问“已验证销售数据产品”、“精选竞争对手洞察产品”和“实时社交情绪产品”,从而生成一份综合报告。
- 提升安全性和治理:随着人工智能代理日益自主,确保它们在合乎道德和安全的界限内运行至关重要。拥有明确所有权、血统和内置治理机制(例如,访问控制、嵌入元数据的使用策略)的数据产品,可以帮助管理代理有权访问的数据及其使用方式。这有助于负责任的人工智能开发。
- 加速代理的开发和部署:当数据以定义明确的产品形式随时可用时,开发人员可以更快地构建和训练人工智能代理。他们可以减少在数据整理上花费的时间,而将更多时间投入到代理的核心逻辑和功能上。
- 促进人机协作:当人类和人工智能代理都依赖相同的可信数据产品时,协作将变得更加无缝。人类可以轻松理解代理正在使用的数据,验证其输出,并在必要时进行干预。
连接到 Entropic 的模型上下文协议 (MCP):
数据产品的愿景与 Anthropic 的模型上下文协议 (MCP) 等新兴标准高度契合。MCP 是一种开放协议,旨在规范 AI 模型(包括支持代理的模型)与外部数据源和工具的连接和交互方式。
数据产品可以被视为通过 MCP 服务器进行公开的理想选择。通过将数据、元数据、访问逻辑和质量保证打包到数据产品中,组织可以创建一个现成的、可靠的“上下文源”,AI 代理可以通过 MCP 连接到该源。这具有以下几个优势:
- 标准化访问: MCP 提供“AI 的 USB-C 端口”,为代理提供接入各种数据源的标准化方式。通过 MCP 公开的数据产品,对于任何符合 MCP 标准的代理来说,都可以轻松成为其使用的构建模块。
- 增强 LLM 的上下文:代理系统通常利用大型语言模型 (LLM)。数据产品可以通过 MCP 为这些 LLM 提供丰富、结构化且值得信赖的上下文,从而使代理能够做出更准确、更相关、更可靠的响应和操作。LLM 不再仅仅依赖于自身的训练数据,而是可以从专用数据产品中获取最新的、特定领域的高质量信息。
- 安全且受管控的数据交换: MCP 旨在实现安全连接。当通过 MCP 访问具有固有安全性和管控功能的数据产品时,它可以加强对 AI 代理敏感信息的访问控制。
本质上,数据产品提供结构良好、可靠且受管控的“内容”(数据资产本身),而像 MCP 这样的协议则提供标准化的“方法”(AI 代理访问和使用该资产的机制)。两者强强联手,可以显著加速复杂 Agentic AI 系统的开发和可信应用,使其能够更有效、更安全地利用组织数据,从而实现商业价值。


