RefineX团队 投稿
量子位 | 公众号 QbitAI
在噪声污染严重影响预训练数据的质量时,如何能够高效且精细地精炼数据?
中科院计算所与阿里Qwen等团队联合提出RefineX,一个通过程序化编辑任务实现大规模、精准预训练数据精炼的新框架。
其核心优势在于:将专家指导的高质量端到端优化结果,蒸馏为极简的基于编辑操作的删除程序。

通过这一高精度蒸馏流程,可以训练出高效可靠的优化模型(refine model),系统地优化语料中的每个实例。
在高效精炼数据的同时,可靠地保留原始文本的多样性和自然性。
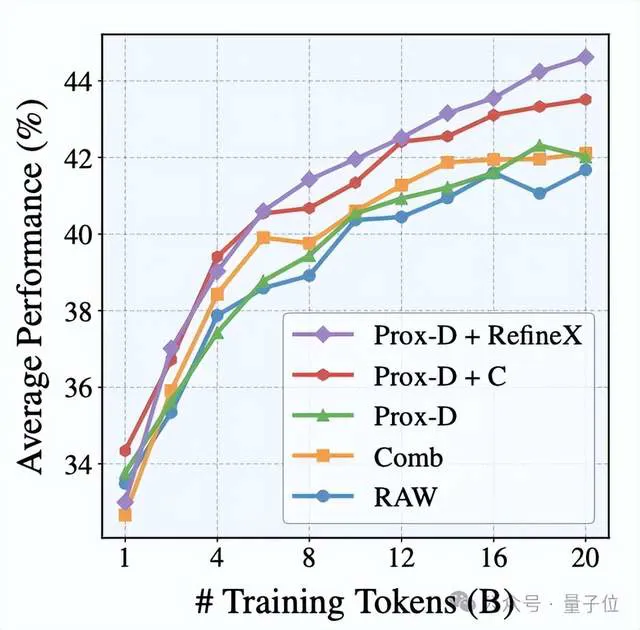
用RefineX净化后的20B token数据训练750M模型时,其在常识推理、科学问答等10项任务的平均得分达到44.7,较原始数据提升7.2%。
预训练数据的质量直接决定了模型的知识深度与推理能力上限。
当互联网成为海量训练数据的来源,噪声污染也随之而来——植入的广告、破碎的HTML标签、无意义的乱码等,不仅降低数据效用,更可能引发模型幻觉。
然而,大规模的去除这些噪声来提升预训练数据的质量是十分困难的,因为同时要兼顾两个要素:
- 高效:由于数据规模庞大,精炼必须能够高效低成本的进行
- 可靠:精炼应该最大化的保留有价值信息,并不引入额外的模型或人工偏好而破坏原始数据的本质。
传统数据精炼方案主要集中于规则过滤和端到端重写。但是,规则过滤(如C4/Gopher)只能文档级粗筛选择,误伤高价值内容,且无法做到字符级的精准修正;端到端重写尽管重写质量高,但推理成本极高,无法应用于大规模数据。
更危险的是,端到端重写过程常擅自修改术语与句式从而引入模型偏好的不可控性,如:
原始: “Climate change[广告] impacts the environment” 重写: “Climate change impacts ecosystems” # 篡改关键术语
而RefineX框架受ProX等新兴工作的启发,选择了一条新的去噪路径:
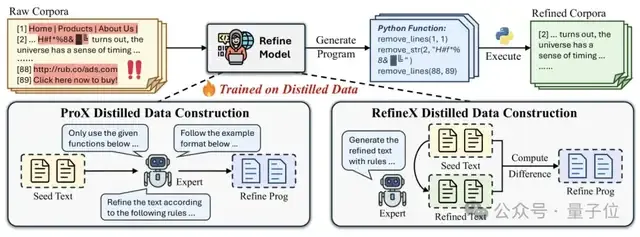
上图展示了基于程序的精炼流程,以及ProX和RefineX中精炼模型的训练数据构建比较。
ProX的限制在于直接训练来自专家输出的噪声精炼程序,复杂的prompt组合极大增加了这项任务的生成难度,从而降低蒸馏数据质量。
而RefineX在蒸馏数据的处理上进行了创新,将蒸馏数据的构建结构分为两个明确的阶段:首先执行端到端精炼,然后通过将精炼后的文本与原始文本进行比较来生成更可靠的监督程序。
这个两阶段过程产生了显著更可靠的监督,有效消除了生成过程中引入的过度编辑风险,最终生成一个更有效且更鲁棒的精炼模型。
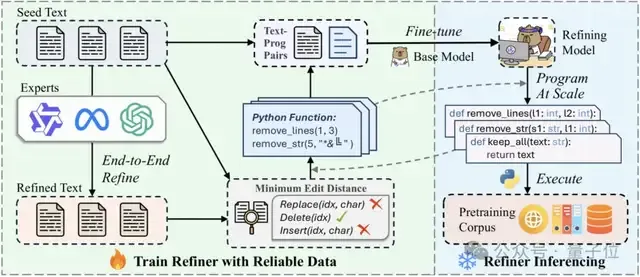
上图展示了RefineX的核心工作流程。
RefineX的目标是降低专家模型直接生成用于蒸馏的精炼程序难度,同时尽可能保留端到端输出中的有效精炼操作。
为实现这两个目标,RefineX首先在精心设计的指令下提示专家模型生成高质量的精炼文本。然后,将精炼文本与原始输入进行比较,基于最小编辑距离提取可靠的删除操作序列。
这些操作被转换为预定义的程序函数集,作为可信的监督信息来训练紧凑的精炼模型。
训练完成后,模型通过推理生成可靠的精炼程序,随后执行这些程序以高效地在语料库中执行细粒度精炼。
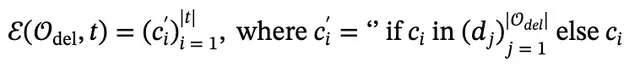
为彻底规避模型偏好带来的新增内容或者过度修改的风险,仅保留精炼过程中的删除操作,RefineX限制程序函数为删行、删字符、保留全部。上面是具体的函数定义。
“只删不改”可以很好得保护原始文本,使拼写偏差等非关键缺陷得以保留——它们将在预训练中被数十万亿token自然中和,而不会污染数据的多样性本质。
另外,RefineX使用最小编辑距离算法来捕获原文本和端到端精炼后文本的差异,并过滤非法的插入和替换操作以及低质量数据,将可靠的删除操作与预定义好的函数对齐,和原文本组成文本-程序对用于优化模型的训练。
RefineX使用动态分块机制来保持长上下文的内容捕获,提升模型的长上下文处理能力。
论文使用Qwen2.5-72B-Instruct模型作为专家模型进行端到端精炼,消耗万卡小时来处理得到大约200万个高质量蒸馏样本,用于训练0.6B的Qwen-3-Base模型作为优化模型。
较小的参数量可以实现较高的推理速度保证精炼的高效性,严谨的蒸馏数据处理方法保证了优化模型的可靠性。
为了评估优化数据对模型性能的影响,RefinX团队使用每种方法优化后的语料库,从头开始预训练不同规模的LLMs,并在下游任务中评估它们。
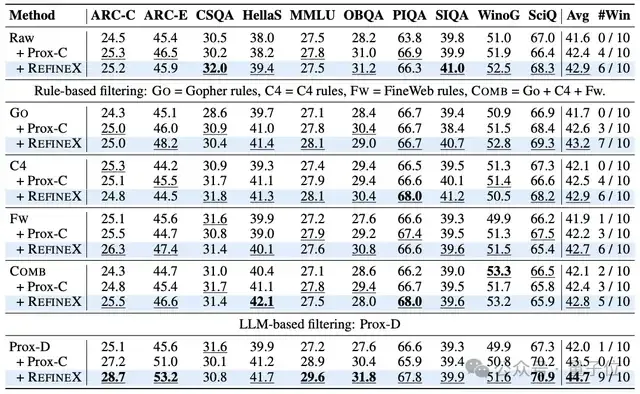
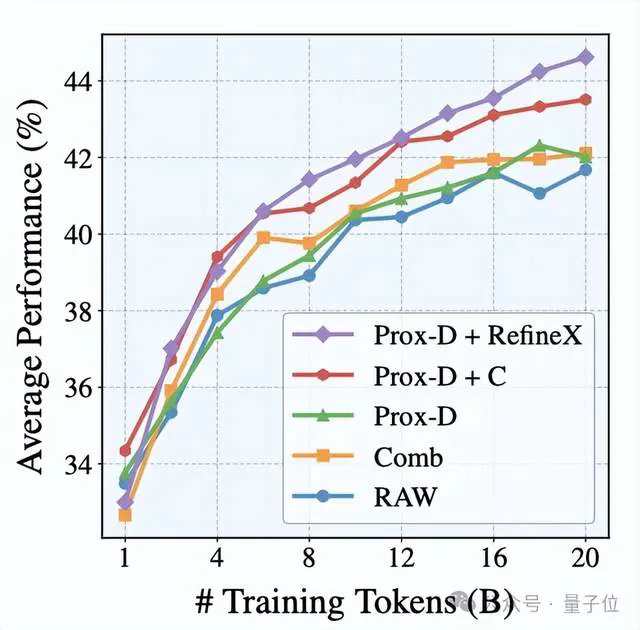
结果显示,尽管在不同任务中表现最佳的变体可能来自不同的数据源,RefineX在每个单独的任务上都取得了最佳结果。
当用RefineX净化后的20Btoken数据训练750M模型时,其在常识推理、科学问答等10项任务的平均得分达到44.7,比原始数据提高了+7.2%,比Comb提高了+5.9%,甚至比最强的先前细粒度改进方法Prox-C还要高+2.6%。
在数据效率的改善上,模型使用10B净化token的表现超越其使用20B传统过滤数据的性能,表明RefineX可以有效地通过删除垃圾文本降低训练单文本的token开销,从而在训练token总数限制下让模型预训练考虑更加多样的文本。
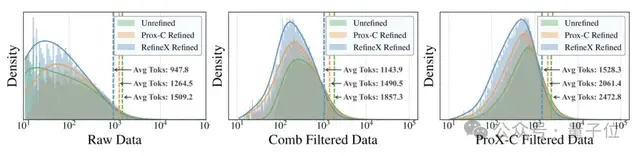
无论是对原始数据进行改进还是对先前过滤的数据集进行改进,使用RefineX训练的模型始终在平均得分上获得最高分,并赢得最多任务。
论文使用文本质量打分器DataMan来对收集的混乱的文本数据进行预分类,并观察精炼前后的质量变化。
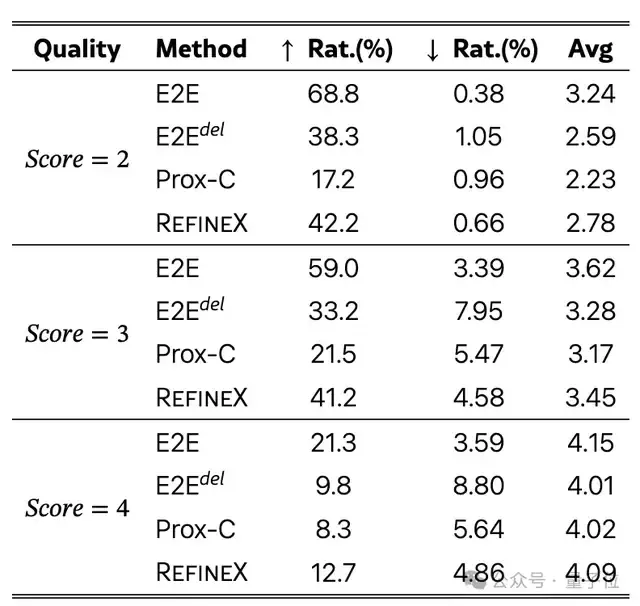
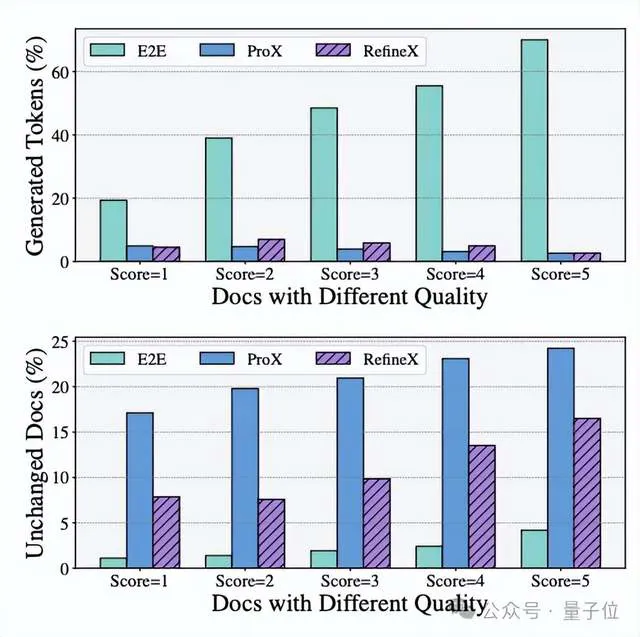
可以看到,在文本质量层面,RefineX对低质内容的改善率高达42.2%,且严格保持“零新增词汇”,杜绝了任何幻觉风险。而端到端方案虽提升率更高,却以每千token新增15个外部词汇为代价,埋下了语义篡改的隐患。
RefineX提供了一个可靠又高效的大规模预训练数据细化的新范式。真正的数据净化不是重塑文本,而是以最小干预剥离噪声,让知识的原初脉络自由呼吸。
arxiv:https://arxiv.org/abs/2507.03253 huggingface:https://huggingface.co/papers/2507.03253 github:https://github.com/byronBBL/RefineX