时令 发自 凹非寺
量子位 | 公众号 QbitAI
Qwen下一代模型架构,抢先来袭!
Qwen3-Next发布,Qwen团队负责人林俊旸说,这就是Qwen3.5的抢先预览版。

基于Qwen3-Next,团队先开源了Qwen3-Next-80B-A3B-Base。
模型参数80B,但训练成本连Qwen3-32B的十分之一都不到,并且在32 k以上的上下文推理吞吐能达到后者的十倍以上。

基于这一模型,团队接连出手,同步开发并发布了两大新模型:
- Qwen3-Next-80B-A3B-Instruct:在256K超长上下文处理任务中展现出显著优势。
- Qwen3-Next-80B-A3B-Thinking:在多项基准测试中超越闭源模型Gemini-2.5-Flash-Thinking。
网友表示,这更新频率令人震惊。

话不多说,赶紧来看看新模型有哪些改进吧。
Qwen3-Next的核心改进有4方面:
- 混合注意力机制
- 高稀疏度MoE结构
- 稳定性优化
- 多token预测机制
线性注意力在长上下文处理中效率很高,但召回能力有限,而标准注意力计算开销大、推理效率低,单独使用均存在局限。
为此,Qwen团队引入Gated DeltaNet,其在上下文学习能力上优于常用的滑动窗口注意力和Mamba2,并在采用3:1的混合策略(75%层使用 Gated DeltaNet,25%层保留标准注意力)时,兼顾性能与效率。
同时,在保留的标准注意力层中,他们进一步引入了多项优化设计:
1、延续先前工作的输出门控机制,以缓解注意力中的低秩问题;
2、将单个注意力头的维度从128扩展至256;
3、仅对注意力头前25%的维度加入旋转位置编码,以增强长序列外推能力。
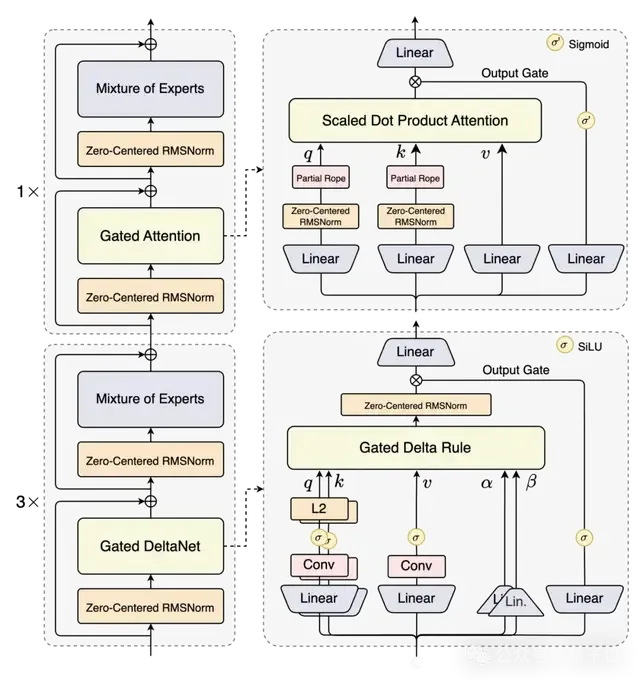
Qwen3-Next采用高稀疏度的MoE架构,总参数量达800亿,但每次推理仅激活约30亿参数。
相比Qwen3-MoE的128个总专家和8个路由专家,Qwen3-Next 扩展到512个总专家,并采用10路由专家加1共享专家的组合设计,在保证性能的前提下最大化资源利用率。
在Qwen3-Next中,团队为进一步提高模型稳定性,采用了Zero-Centered RMSNorm,并在此基础上,对norm weight施加weight decay,以避免权重无界增长。
不仅如此,他们还在初始化时归一化了MoE router的参数,确保每个expert在训练早期都能被无偏地选中,减小初始化对实验结果的扰动。
Qwen3-Next引入了原生Multi-Token Prediction(MTP) 机制,不仅获得了Speculative Decoding接受率较高的MTP模块,还提升了模型主干的整体性能。
此外,它还对MTP的多步推理进行了专项优化,即通过训练推理一致的多步策略,进一步提高了在实际应用场景下Speculative Decoding的接受率。
接下来,让我们一起看看新模型表现如何。
首先,Qwen3-Next使用了Qwen3 36T预训练语料的均匀采样子集,仅包含15T tokens。
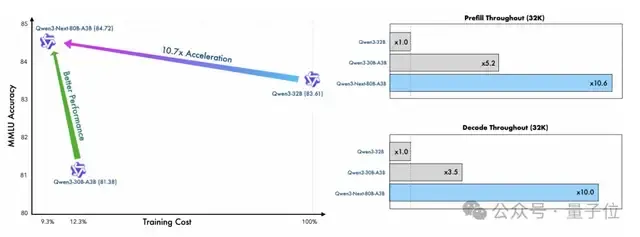
其训练所需的GPU Hours不到 Qwen3-30A-3B的80%,相比 Qwen3-32B,仅需9.3%的GPU计算资源就能取得更优性能。
不仅如此,得益于创新的混合模型架构,Qwen3-Next在推理效率上也表现突出。
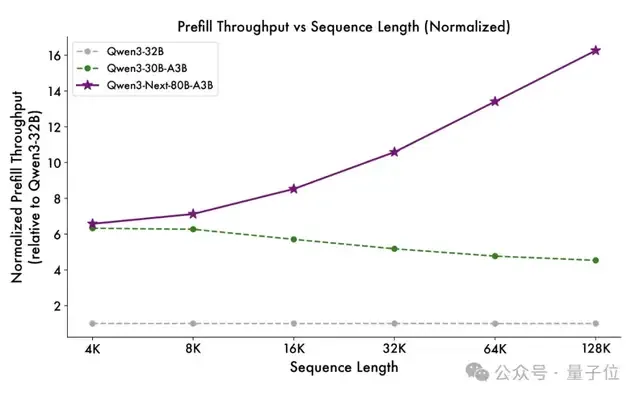
与Qwen3-32B相比,Qwen3-Next-80B-A3B在预填充(prefill)阶段就展现出卓越的吞吐能力:
在4k tokens的上下文长度下,吞吐量接近前者的7倍;当上下文长度超过32k时,吞吐提升更是达到10倍以上。
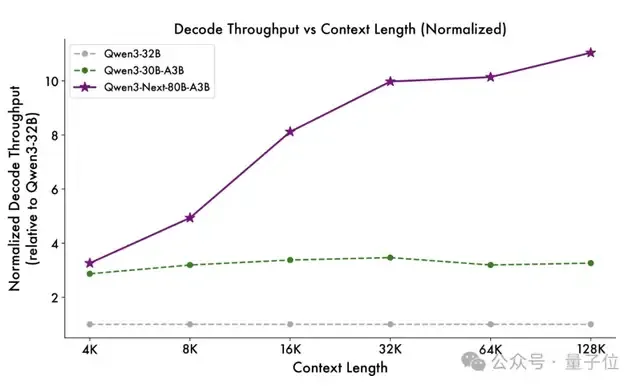
在解码(decode)阶段,该模型同样高效。4k上下文吞吐量提升约4倍,长上下文(32k+)场景中仍可保持超过10倍的吞吐优势。
基于Qwen3-Next,Qwen团队首先训练了Qwen3-Next-80B-A3B-Base模型。
该模型仅使用十分之一的Non-Embedding激活参数,就已在大多数基准测试中超越Qwen3-32B-Base,并显著优于Qwen3-30B-A3B,展现出出色的效率与性能优势。
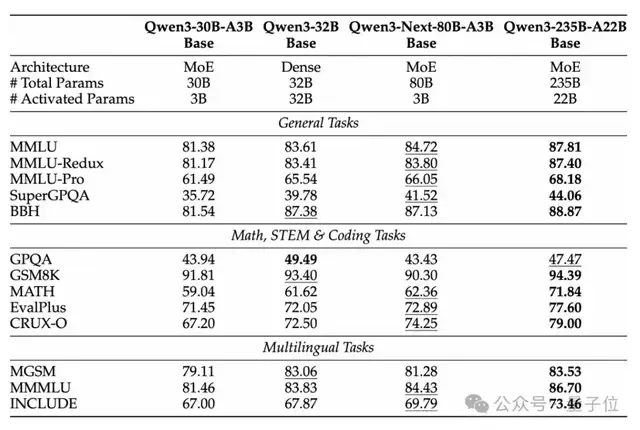
基于Qwen3-Next-80B-A3B-Base的优异表现,团队进一步开发并发布了Qwen3-Next-80B-A3B-Instruct与Qwen3-Next-80B-A3B-Thinking。
首先,Qwen3-Next-80B-A3B-Instruct的表现显著优于 Qwen3-30B-A3B-Instruct-2507和Qwen3-32B-Non-thinking,并在多数指标上接近Qwen3-235B-A22B-Instruct-2507。
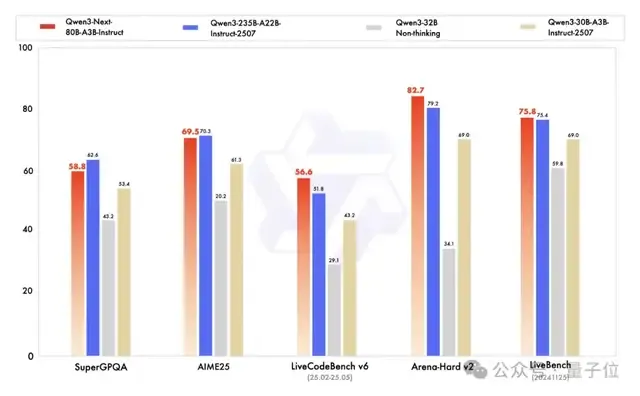
除此之外,在RULER测试中,无论上下文长度如何,Qwen3-Next-80B-A3B-Instruct 的表现均超过了层数相同但注意力层更多的Qwen3-30B-A3B-Instruct-2507。

甚至在256 k范围内也优于层数更多的Qwen3-235B-A22B-Instruct-2507,充分体现了Gated DeltaNet与Gated Attention混合模型在长文本处理场景下的优势。
再来看Qwen3-Next-80B-A3B-Thinking,其表现也相当不错。
在多项基准测试中都超过了闭源模型Gemini-2.5-Flash-Thinking,并在部分指标上接近Qwen最新的旗舰模型 Qwen3-235B-A22B-Thinking-2507。
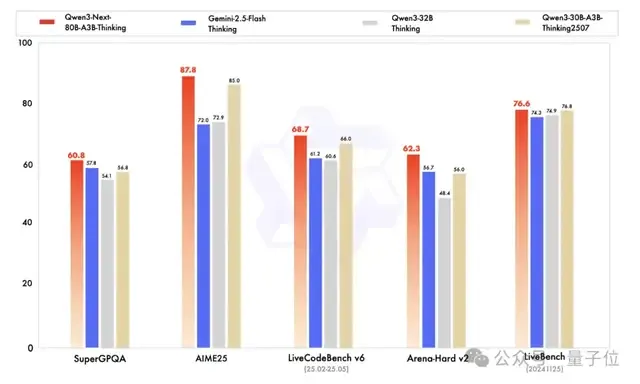
接下来让我们实测一下Qwen3-Next-80B-A3B的推理能力。
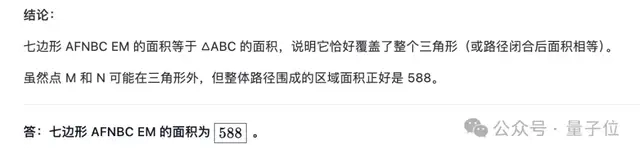
使用Qwen Chat网页,一上来就给它扔一道AIME数学竞赛题试试:

由于Qwen3-Next-80B-A3B支持多模态,这里我们可以直接上传图片。
几乎瞬间,模型就开始飞快地列出了详细解题思路和计算过程,最终得到的答案“588”与AIME标准答案完全吻合。
小试牛刀之后,接下来进入编程环节。
用p5js创建一个可直接玩的扫雷游戏。
代码成功运行后,我们也简单试玩了一下,流畅度还可以(doge)。
就是谁能解释一下为什么这个游戏背景是大红色,还没有网格线???
还有网友奇思妙想,用它生成了天气卡片。
不过,看到这个更新时,网友开心之余还是忍不住吐槽:
名字实在太复杂了。

目前,新模型已在魔搭社区和抱抱脸开源,大家可通过Qwen Chat免费体验,也可直接调用阿里云百炼平台提供的API服务。
魔搭社区直通车:https://t.co/mld9lp8QjK 抱抱脸直通车:https://t.co/zHHNBB2l5X Qwen Chat直通车:https://t.co/V7RmqMaVNZ 阿里云API直通车:https://t.co/RdmUF5m6JA
参考链接: [1]https://x.com/Alibaba_Qwen/status/1966197643904000262 [2]https://x.com/JustinLin610/status/1966199996728156167 [3]https://mp.weixin.qq.com/s/STsWFuEkaoUa8J8v_uDhag?scene=1


