
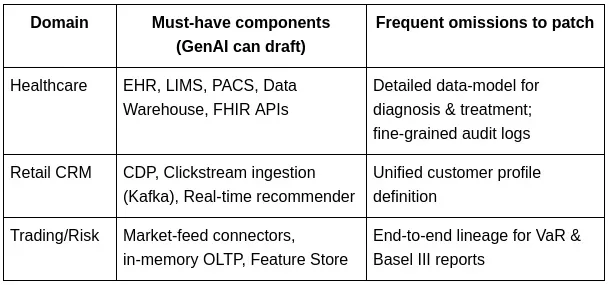
生成式人工智能 (GenAI) 已从最初的好奇发展成为数据工程工作流程中的日常工具:我们现在只需一个精心设计的指令,就能起草架构、生成模式、启动基础设施模板,甚至生成隐私保护数据。本文将我的经验与当前的行业实践相结合,提炼成一份循序渐进的参考指南,供想成为数据工程师或处于职业生涯中期的人士参考。
为什么它今天如此重要?
人工智能工作负载的爆炸式增长: Apache Flink 2.0等实时分析平台现在开箱即用地承担 LLM 级延迟要求,迫使每个管道在几毫秒内做出反应。
Lakehouse 成为 AI 原生:Databricks 的 Lakehouse AI统一了数据、ML 和治理,将 SQL、矢量搜索和模型服务放在同一平台上。
隐私监管趋严:欧盟人工智能法案的最终文本要求合成内容生成器具有特殊的透明度,并要求更严格的数据治理日志。
一、面向提示的数据架构设计
大型语言模型 (LLM) 的成功秘诀在于,你可以反复练习题目,而不是一次性放弃所有要求。一个行之有效的方法:
1. 基本式提示:
为医院网络创建详细的数据架构设计,重点关注 EHR、PACS、LIMS 和安全性。
2.填空式提示:
添加 HIPAA 级 RBAC、AES-256 静态加密和审计跟踪。
3.模型验证提示:
你做了哪些假设?列出缺失的NFR。
您可以尝试以下更多操作:
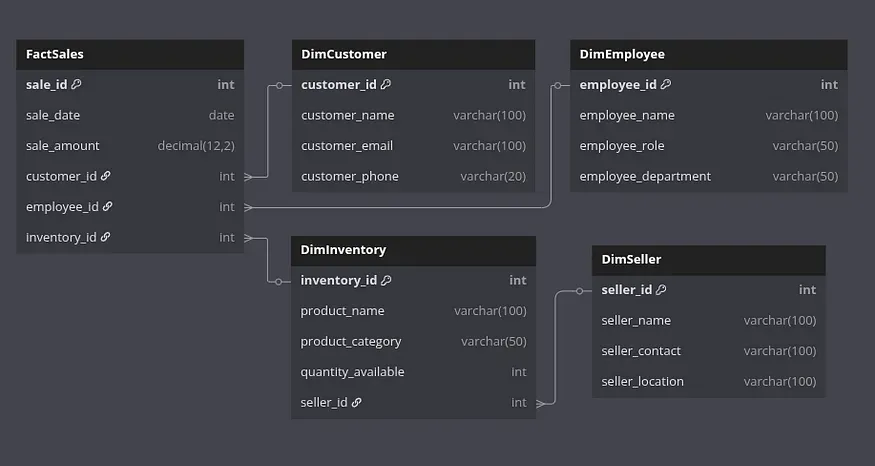
二 LLM 生成的仓库模式
LLM 可以一次性输出星型或雪花型模式以及 SQL DDL。
输入:
为销售、客户、库存、员工和卖家设计一个星型模式。然后生成 DBML 格式的模式,并包含适当的 Table {} 块以及所有外键的 Ref 关系。
输出:
复制Table DimCustomer {
customer_id int [pk]
customer_name varchar ( 100 )
customer_email varchar ( 100 )
customer_phone varchar ( 20 )
}
Table DimEmployee {
employee_id int [pk]
employee_name varchar ( 100 )
employee_role varchar ( 50 )
employee_department varchar ( 50 )
}
Table DimSeller {
seller_id int [pk]
seller_name varchar ( 100 )
seller_contact varchar ( 100 )
seller_location varchar ( 100 )
}
Table DimInventory {
inventory_id int [pk]
product_name varchar ( 100 )
product_category varchar ( 50 )
amount_available int
seller_id int
}
Table FactSales {
sale_id int [pk]
sale_date date
sale_amount decimal(12,2)
customer_id int
employee_id int
inventory_id int
}
Ref: DimInventory.seller_id > DimSeller.seller_id
Ref: FactSales.customer_id > DimCustomer.customer_id
Ref: FactSales.employee_id > DimEmployee.employee_id
Ref: FactSales.inventory_id > DimInventory.inventory_id验证后,将 DDL 粘贴到dbdiagram.io中即可获得即时 ERD。
最佳实践更新:
优先使用Iceberg v1.4或Delta Lake 3.0表来获得 ACID Lakehouse 保证。
用子句标记每个表和列COMMENT——GenAI 可以自动生成描述。
三、合成数据与增强
合成数据既解决了隐私问题,也解决了数据稀缺问题。常用的工具包括:
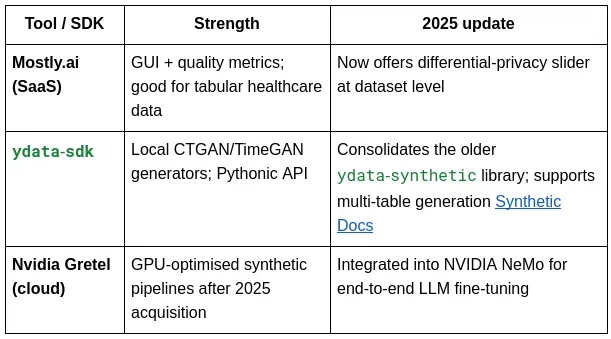
使用 ydata-sdk 的示例:
复制from ydata_sdk.datasets import load_tabular
from ydata_sdk.synth import CTGAN
data = load_tabular('insurance.csv')
model = CTGAN()
model.fit(data, num_epochs=50)
synthetic = model.generate(n_samples=len(data))
synthetic.to_csv('insurance_synth.csv', index=False)数据匿名化工作
除了合成数据之外,你仍然需要直接匿名化。将简单的 Python 转换与差异隐私框架相结合。
导入重新
导入随机
导入pandas作为pd
复制# 示例数据
data = [
{ "name" : "Rohit Sharma" , "age" : 36 , "email" : "[email protected]" , "phone" : "9876543210" },
{ "name" : "Anjali Verma" , "age" : 24 , "email" : "[email protected]" , "phone" : "9123456789" },
{ "name" : "David Johnson" , "age" : 43 , "email" : "[email protected]" , "phone" : "9012345678" }
]
# 创建 DataFrame
df = pd.DataFrame(data)
# 帮助器来编辑电子邮件
def redact_email ( email ):
username, domain = email.split( '@' )
return username[: 2 ] + "***@redacted.com"
# 匿名化函数
def anonymize ( row ):
row[ 'name' ] = re.sub( r'[aeiouAEIOU]' , '*' , row[ 'name' ])
row[ 'age' ] = f" {row[ 'age' ]// 10 } 0s"
row[ 'email' ] = redact_email(row[ 'email' ])
row[ 'phone' ] = row[ 'phone' ][:- 5 ] + str (random.randint( 10000 , 99999 ))
return row
# 应用匿名化
df_anonymized = df.apply(anonymize, axis= 1 )
# 显示前几行
df_anonymized.head()对于更严谨的使用,OpenDP SmartNoise适用于 DP 保证版本。
监管提示:根据欧盟人工智能法案第 50 条,将合成或大量转换的数据集标记为人工生成的。
四、GenAI辅助基础设施规模调整
提示模板让您可以根据工作负载导出云架构。
输入:
“建议基础设施堆栈每秒传输 25 万个事件,每年存储 3 PB 数据,并提供小于 200 毫秒的分析延迟。
输出:
• 存储建议
• 计算层
• 实时引擎
• 成本优化建议。”
GenAI 通常建议:
存储— 对象(S3/GCS)+ 开放表格式 Lakehouse
计算——在 Kubernetes 上自动扩展 Spark;Flink 2.0用于流
实时——Kafka + Flink SQL,由低延迟 OLAP(ClickHouse)支持
成本杠杆——分层存储、Graviton/ARM 节点、现货队列
使用云计算器进行验证,然后通过另一个提示导出 Terraform JSON。示例:
输入:
根据下面描述的基础架构堆栈,生成 JSON 格式的 Terraform(*.tf.json)以在 AWS 上配置架构:
要求:
每秒 250K 个事件的流提取存储 3 PB/年的数据(对象存储 + lakehouse 格式)支持 <200ms 分析延迟使用自动扩展计算 Kubernetes 上的 Spark使用 Kafka + Flink 2.0 的实时引擎使用ClickHouse 进行低延迟分析
包括:
S3 存储设置MSK(托管 Kafka)集群用于 Spark/Flink 工作负载的 EKS 集群基于 ClickHouse EC2 的集群IAM 角色、网络基础知识(VPC、子网)
成本优化:
分层 S3 存储、Graviton2 EC2 节点、现货车队使用情况
输出:
复制{
“provider” : {
“aws” : {
“region” : “us-east-1”
}
} ,
“resource” : {
“aws_s3_bucket” : {
“data_lake” : {
“bucket” : “my-event-data-lake” ,
“force_destroy” : true
}
} ,
“aws_msk_cluster” : {
“event_stream” : {
“cluster_name” : “event-stream-msk” ,
“kafka_version” : “3.4.0” ,
“number_of_broker_nodes” : 3 ,
“broker_node_group_info” : {
“instance_type” : “kafka.m5.large” ,
“client_subnets” : [ “subnet-abc123” , “subnet-def456” ] ,
“security_groups” : [ “sg-0123456789abcdef0” ]
}
}
} ,
“aws_eks_cluster” : {
“analytics_cluster” : {
“name” : “spark-flink-cluster” ,
“role_arn” : “arn:aws:iam :: 123456789012:role / eks-cluster-role” ,
“vpc_config” : {
“subnet_ids” : [ “subnet-abc123” , “subnet-def456” ]
}
}
} ,
“aws_eks_node_group” : {
“analytics_nodes” : {
“cluster_name” : “$ {aws_eks_cluster.analytics_cluster.name}” ,
“node_role_arn” : “arn:aws:iam :: 123456789012:role / eks-node-role” ,
“subnet_ids” : [ “subnet-abc123” , “subnet-def456” ] ,
“instance_types” : [ “m6g.large” ] ,
“scaling_config” : {
“desired_size” : 4 ,
“max_size” : 10 ,
“min_size” : 2
} ,
“capacity_type” : “SPOT”
}
} ,
“aws_security_group” : {
"clickhouse_sg" : {
"name" : "clickhouse-security-group" ,
"description" : "允许内部访问 ClickHouse 节点" ,
"ingress" : [
{
"from_port" : 8123 ,
"to_port" : 8123 ,
"protocol" : "tcp" ,
"cidr_blocks" : [ "10.0.0.0/16" ]
}
] ,
"egress" : [
{
"from_port" : 0 ,
"to_port" : 0 ,
"protocol" : "-1" ,
"cidr_blocks" : [ "0.0.0.0/0" ]
}
] ,
"vpc_id" : "vpc-0123456789abcdef0"
}
} ,
"aws_instance" : {
"clickhouse_node" : {
“ami” : “ami-0abcdef1234567890” ,
“instance_type” : “m6g.large” ,
“count” : 3 ,
“vpc_security_group_ids” : [ “${aws_security_group.clickhouse_sg.id}” ] ,
“subnet_id” : “subnet-abc123” ,
“tags” : {
“名称” : “clickhouse-analytics-node”
}
}
}
}
}提示:
您必须将子网 ID、VPC ID、AMI和IAM 角色替换为实际值。
此配置不包括Flink 或 Spark 部署,这些部署将通过 Helm 图表或 Kubernetes 清单在 EKS 内处理(Terraform 可以触发 Helm)。
根据需要添加自动扩展组、数据分层策略和监控(例如 CloudWatch)。
五、LLMOps — 每个数据工程师必备
大型语言模型操作 (LLMOps) 位于数据工程和 MLOps 的交汇处。以下是一些核心最佳实践:
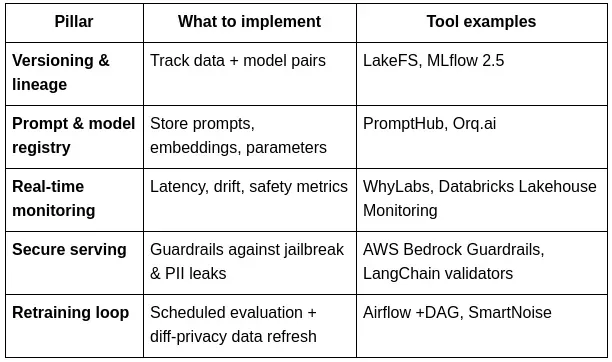
六、小结
为了在不断发展的数据和人工智能领域保持竞争力,掌握架构和基础设施设计的快速工程技术如今已成为一项基础技能。采用 Lakehouse 架构和开放表格式将简化 GenAI 集成并简化数据工作流程。此外,熟练掌握 Mostly.ai 或 YData 等合成数据生成工具以及 SmartNoise 等差异化隐私框架,对于确保数据合规性至关重要。虽然使用 GenAI 实现基础设施决策自动化可以显著提高效率,但根据成本、延迟和安全约束验证这些决策至关重要。此外,随着数据工程师承担起维护生产环境中大型语言模型健康的责任,投资 LLMOps 也变得越来越重要。通过掌握上述技能,您将确保您的数据工程技能在 GenAI 持续重塑整个技术栈的背景下依然保持竞争力。


