AI 也要「考古」式科研?
人工智能的「第一性原理」扩展定律(Scaling Laws),把模型性能与算力等资源投入联系在了一起,是如今人们构建更先进大模型重要的参考标尺。
有关扩展定律的起源,存在很多种说法,有人认为是 2020 年 OpenAI 提出的,有人认为是 2017 年百度发现的,详情可参阅我们之前的报道《遗憾不?原来百度 2017 年就研究过 Scaling Law,连 Anthropic CEO 灵感都来自百度》。
前些天,康奈尔大学博士生、Meta 研究员 Jack Morris 发推称 Scaling Law 的真正探索者其实是贝尔实验室,这又进一步将历史向前推到了 1993 年。

他进一步解释说,这篇论文其实是一篇 NeurIPS 论文。贝尔实验室的研究者「在不同大小的数据集、不同大小的模型上训练了分类器并拟合了幂律」。这让 Morris 不禁感叹:「不敢相信这已经是 32 年前的事了。」
近日,OpenAI 联合创始人、总裁 Greg Brockman 也转发了这一消息,并表示这些结果跨越了多个数量级和几十年的时间,经历了时间的考验,可以说揭示了深度学习的根本。

这也不得不让人赞叹贝尔实验室的前瞻性和众多开创贡献:

贝尔实验室的 Scaling Law
回到人们正在讨论的这篇论文本身。它是一篇 AI 顶会 NeurIPS 论文:

论文标题:Learning Curves: Asymptotic Values and Rate of Convergence
论文链接:https://proceedings.neurips.cc/paper/1993/file/1aa48fc4880bb0c9b8a3bf979d3b917e-Paper.pdf
这篇论文介绍说,基于大规模数据训练分类方法是相当耗费算力的工作。因此,开发高效的程序来可靠地预测分类器是否适合执行给定任务至关重要,这样才能将资源分配给最有潜力的候选分类器,或腾出资源来探索新的候选分类器。
作者提出了一种实用且有原则的预测方法,避免了在整个训练集上训练性能较差的分类器的高成本过程,同时拥有坚实的理论基础。作者证明了所提方法的有效性,以及适用于单层和多层网络。
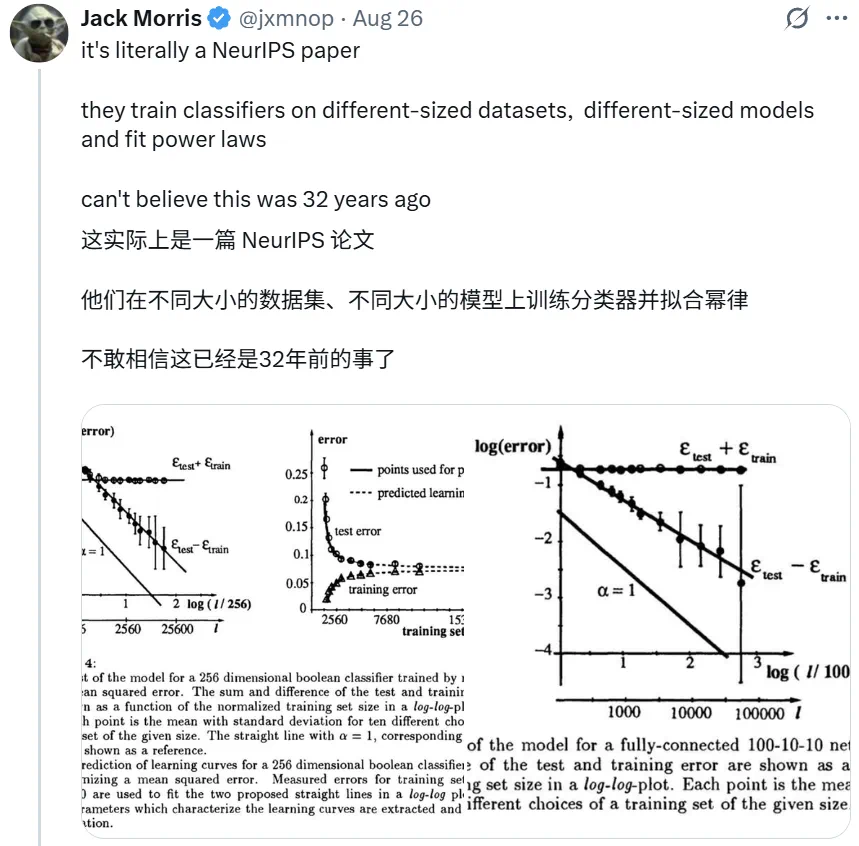
在该工作中,作者研究了自动分类的算法,随着训练数据逐步增加,分类器的能力(模型出错的概率)被持续标记。在测量了多个数据点后,可以发现模型的错误率对比训练数据的数量,在对数曲线上呈现出了一定的规律。
作者进而得出结论:「经过 12000 种模式的训练后,很明显新网络的表现将优于旧网络…… 如果我们的预测方法能够对网络的测试误差做出良好的定量估计,我们就可以决定是否应该对新架构进行三周的训练。」
这就意味着模型的规模扩大,AI 的智能会越来越强;而这就是 Scaling Law(扩展定律)!
从几万条数据训练的机器学习模型开始,到去年 GPT-4 上万亿巨量数据集、万亿参数的规模,几十年来,扩展定律一直有效。
作者介绍:从「国宝」到「疯狂科学家」
这篇论文一共有 5 位作者:Corinna Cortes、L. D. Jackel、Sara A. Solla、Vladimir Vapnik、John S.Denker。各自都有自己的传奇经历。
Corinna Cortes
这篇论文的一作 Corinna Cortes 已经拥有超过 10 万引用!她与四作 Vladimir Vapnik 也是经典论文《Support-vector networks》(引用量超过了 7.7 万)的两位作者。这篇论文提出了大家熟知的现代意义上的支持向量机。
另外,她还与 LeCun 等人一起构建了著名的 MNIST 数据集,而这也成为了后续大量研究的重要基础数据集。
也无怪乎有人在评论区称她是「国宝」:
Corinna Cortes 的职业履历很简单:先在贝尔实验室工作了 14 年,之后于 2003 年加入谷歌,领导 Google Research NY 达 21 年之久。现在她是 NeurIPS 的董事会成员之一。她同时也是一名竞技跑步运动员。
Lawrence D Jackel
这篇论文的二作 Lawrence D Jackel 是时任的贝尔实验室应用系统研究部门负责人。1988 年 Yann LeCun 加入该实验室后,与他合作完成了多项高引用研究成果,其中包括一篇重要的反向传播论文《Backpropagation applied to handwritten zip code recognition》。
Sara A. Solla
Sara A. Solla 则是一名物理学家和神经科学家。她最高引用的论文也是与 Yann LeCun 合著的《Optimal brain damage》。
该论文运用信息论的思想,推导出了一类用于调整神经网络规模的实用且近乎最优的方案。通过从网络中移除不重要的权重,可以预期实现多项改进:更好的泛化能力、更少的训练样本需求以及更快的学习和 / 或分类速度。其基本思想是利用二阶导数信息在网络复杂度和训练集误差之间进行权衡。
Vladimir Vapnik
前文我们已经见到过 Vladimir Vapnik 的名字,即支持向量机的作者之一。除此之外,这位拥有超过 33.5 万引用的大佬还是统计学习领域著名的 Vapnik–Chervonenkis 理论的提出者之一 —— 是的,这个理论就是以他和苏联数学家 Alexey Chervonenkis 的名字命名的。
Vladimir Vapnik 在 1995 年出版的 《The Nature of Statistical Learning Theory》是系统化提出统计学习理论(Statistical Learning Theory, SLT)的代表作,堪称机器学习领域的里程碑。
John S. Denker
John S. Denker 则更是一位多才多艺的研究者,涉足过大量不同领域,甚至可以说是天才(Genius)的代名词。

他曾就读于加州理工学院。大三时,他创办了一家成功的小型软件和电子公司,在安防系统、好莱坞特效、手持电子游戏和视频游戏等多个领域做出了开创性的工作。此外,在读本科期间,他还在加州理工学院创建并教授了一门课程:「微处理器设计」。
他在康奈尔大学的博士研究考察了氢原子气体在仅比绝对零度高千分之几摄氏度的温度下的性质,并表明在这种稀薄的玻色气体中存在量子自旋输运和长寿命的「自旋波」共振。他的其他研究涉及超低噪声测量设备的设计 —— 其中基本的量子力学限制起着重要作用。
Denker 博士加入过 AT&T 贝尔实验室多年时间,曾担任杰出技术人员、部门主管和部门经理等职务。他的研究兴趣包括计算机安全、选举安全、网络电话和神经网络。他还发明了新型低能耗「绝热」计算系统。
1986 年至 1987 年,他担任加州大学圣巴巴拉分校理论物理研究所客座教授。他曾担任多个重要科学会议的组委会委员。
他拥有多项专利,撰写了 50 多篇研究论文和一本书的章节,并编辑了 《Neural Networks for Computing》一书。他的演讲范围广泛。
他以爱恶作剧和典型的疯狂科学家而闻名。他的一些事迹曾被改编成电影《Real Genius》和《The Age Seeking for Genius》,并刊登在《时代》和《IEEE Spectrum》等刊物上。

John Denker 还拥有商用飞行员、飞行教练和地面教练资格。他是美国联邦航空管理局(FAA)的航空安全顾问。他曾任蒙茅斯地区飞行俱乐部董事会成员,以及美国国家研究委员会商用航空安全委员会成员。
Scaling Law 的历史可能还能继续向前追溯
有意思的是,在相关推文的评论区,有不少研究者评论认为贝尔实验室的这篇论文其实也不是 Scaling Law 的最早论文。
比如著名研究者、科技作家 Pedro Domingos 表示其实心理学领域才是最早探索「学习曲线」的领域。

研究者 Maksym Andriushchenko 表示 Vladimir Vapnik 在上世纪 60 年代就已经研究过样本大小方面的 Scaling Law。

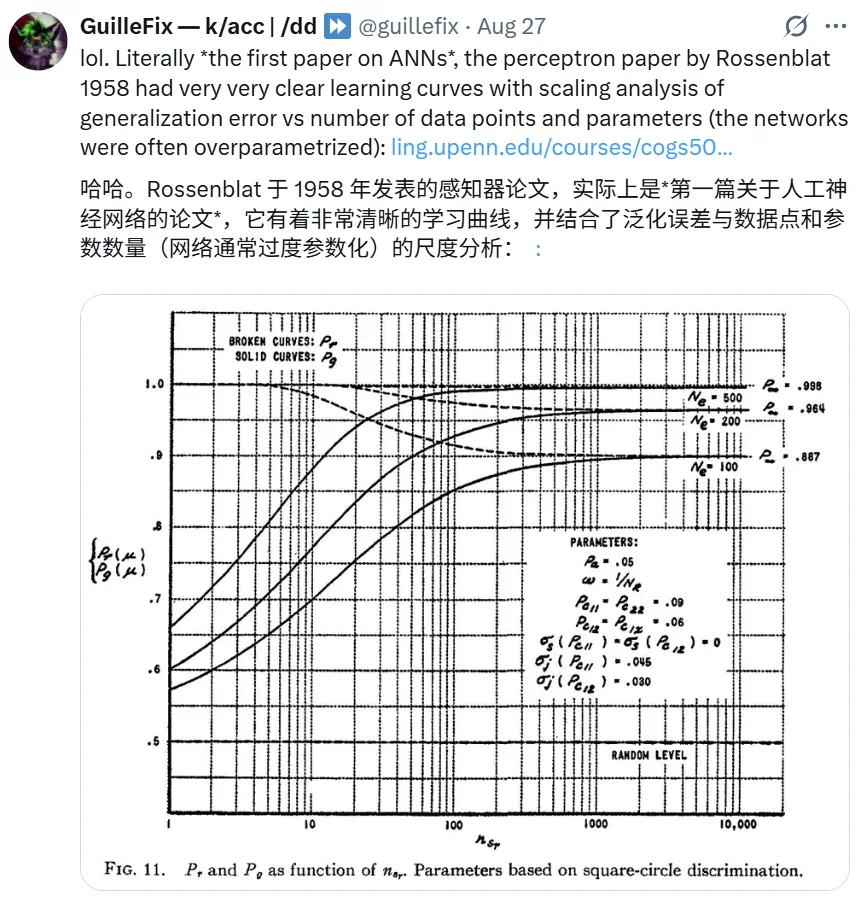
而 @guillefix 则表示 Frank Rosenblatt 在 1958 年发表的感知器论文《The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain》就已经给出了非常清晰的学习曲线。
此外,𝕏 用户 @lu_sichu 提出了 1992 年日本工程师和神经科学家甘利俊一(Shun-ichi Amari)写的论文《A Universal Theorem on Learning Curves》也比贝尔实验室的上述论文更早一些。
其中证明了一类普适的学习曲线渐近行为,适用于一般的无噪声二分机器或神经网络。结果表明:无论机器的架构如何,其平均预测熵或信息增益 <e*(t)> 都会在训练样本数 t 增加时收敛至零,并满足 <e*(t)> ~d/t 的规律,其中 d 为机器的可调参数的个数。

纵观数十年的研究脉络,Scaling Law 的提出并非灵光乍现的顿悟,而是跨越学科、跨越时代的逐步累积。从心理学的学习曲线,到感知器的早期探索,再到 Vapnik、Amari、贝尔实验室的系统化研究,最后发展到 OpenAI 等机构在大规模实验中验证和推广,每一代学者都在为这条「经验定律」添砖加瓦。
今天我们所说的 Scaling Law,看似清晰而坚固,但它背后蕴含的是数十年理论与实践的反复印证。正如 Brockman 所言,它揭示了深度学习的根本,而这一「根本」并不是一蹴而就的,而是科学探索在时间长河中的积累与沉淀。
对此,你怎么看?


