思考自身行为的后果,并在必要时进行修正 —— 这是人类智慧的核心特征之一。
一个月前,我们曾报道过清华姚班校友、普林斯顿教授陈丹琦似乎加入 Thinking Machines Lab 的消息。有些爆料认为她在休假一年后,会离开普林斯顿,全职加入 Thinking Machines Lab。
最近,陈丹琦在普林斯顿大学的团队发布了最新学术成果,表明了 RLVR 范式在可验证领域之外依然有效,提出了 基于模型奖励思维的强化学习(RLMT) 方法,它将显式的思维链推理融入通用聊天模型之中。

论文标题:Language Models that Think, Chat Better
论文链接:https://www.arxiv.org/overview/2509.20357v1
众所周知,大型语言模型传统上遵循一种多阶段训练范式:首先在大规模文本语料上进行 预训练,然后通过 监督微调 来学习指令跟随,最后借助 强化学习 来对齐人类偏好。
这种方法确实催生了功能强大的对话式 AI 系统,但仍存在一个关键局限:
在数学、编程等领域通过可验证奖励的强化学习(RLVR)所获得的推理能力,并不能有效迁移到通用对话任务上。
本文介绍了 基于模型奖励的思维强化学习(RLMT) 方法,它弥合了 专门推理能力 与 通用对话能力 之间的差距。该方法使语言模型能够在开放式任务中进行显式的「思考」过程,将 链式思维 的优势从可验证领域扩展到更广泛的范围,从而提升整体对话表现。

使用基于奖励模型的强化学习,在多样化的、通用的用户提示上训练具备长链式思维的语言模型。与 RLHF 相比,RLMT 让模型能够进行「思考」,并且将 RLVR 扩展到了更广泛的、开放式任务之中。
当前的大语言模型训练面临一个根本性的两难局面。像 DeepSeek-R1 所采用的 RLVR 方法,在数学推理和代码生成等领域表现突出,因为它们训练模型在给出最终答案之前生成显式的推理轨迹。然而,这类专门化的推理技能难以推广到日常对话中多样化、主观性强的任务场景里,因为这些任务缺乏可行的基于规则的验证机制。
与之相对,RLHF(基于人类反馈的强化学习) 在对齐模型与人类偏好、提升通用对话能力方面非常成功,但它将模型输出视为一个整体,并未鼓励模型发展内部推理过程。结果导致模型要么能在窄域内进行出色的推理,要么能在广域中进行自然对话,但难以同时兼顾两种能力。
RLMT(基于模型奖励的思维强化学习) 的动机来源于一个关键观察:人类在处理开放式对话任务时,自然而然会进行审慎思考 —— 包括规划、权衡不同可能性、不断修正回答。若能让语言模型也采用类似的显式推理过程,就可能在保持基于偏好的对齐优势的同时,显著提升其在通用对话基准上的表现。

由使用 RLMT 训练的语言模型在开放式问题上生成的推理轨迹示例。
RLMT 方法: RLHF 与 RLVR 结合
优化目标
尽管最新的 RLVR 模型在形式化领域中表现出色,但它们在更广泛的推理问题和聊天基准测试中的泛化能力有限。与此同时,规划与推理确实有助于人类完成各种日常任务。
研究团队提出 模型奖励思维强化学习(RLMT),以在开放式任务上施加广泛监督。RLMT 通过以下目标函数来优化语言模型:
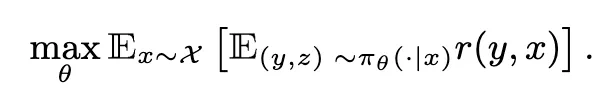
如公式所示,RLMT 要求语言模型在生成最终回答 y 之前,先生成推理轨迹 z。这与 RLHF 不同;同时,RLMT 使用奖励模型 r 来对回答进行评分,而不像 RLVR 那样依赖基于规则的验证。
训练方法
由于当前使用的语言模型并不会自然采用所需的思维格式,因此研究团队尝试了两种方法来引导这一行为:
通过有监督微调(SFT)进行热启动;
直接对基础模型进行提示而不经过 SFT(即 DeepSeek-AI (2025) 提出的 「Zero」 方法)。
通过 SFT 热启动。 首先通过有监督微调(SFT)来教授模型所需的思维格式。
具体来说,团队从 Tülü 3 SFT 混合数据集中采样了 6k 个提示(与用于 RLMT 的提示互不重叠),用于 SFT。使用 Gemini 2.5 Flash (0417 Preview) 生成响应,它是近期常用的一种教师模型,用于从推理模型中蒸馏推理行为 。由于 Gemini 的 CoT 不可直接获取,通过提示它在生成最终回答之前,先产生一个模拟的思维轨迹。
基础模型的零训练。 研究团队也直接在未经热启动的基础模型上应用 RLMT,这一设置称为 Zero。
具体而言,在 Llama-3.1-8B (Llama3, 2024) 和 Qwen-2.5-7B (Qwen-2.5, 2025) 上进行了实验,这些模型都没有经历过后训练。在这种情况下,通过在输入前添加一个固定的指令前缀来引导所需的输出结构。除此之外,后续的 RL 训练过程与 RLMT 的设置保持一致。
结果:思维有利于开放式推理
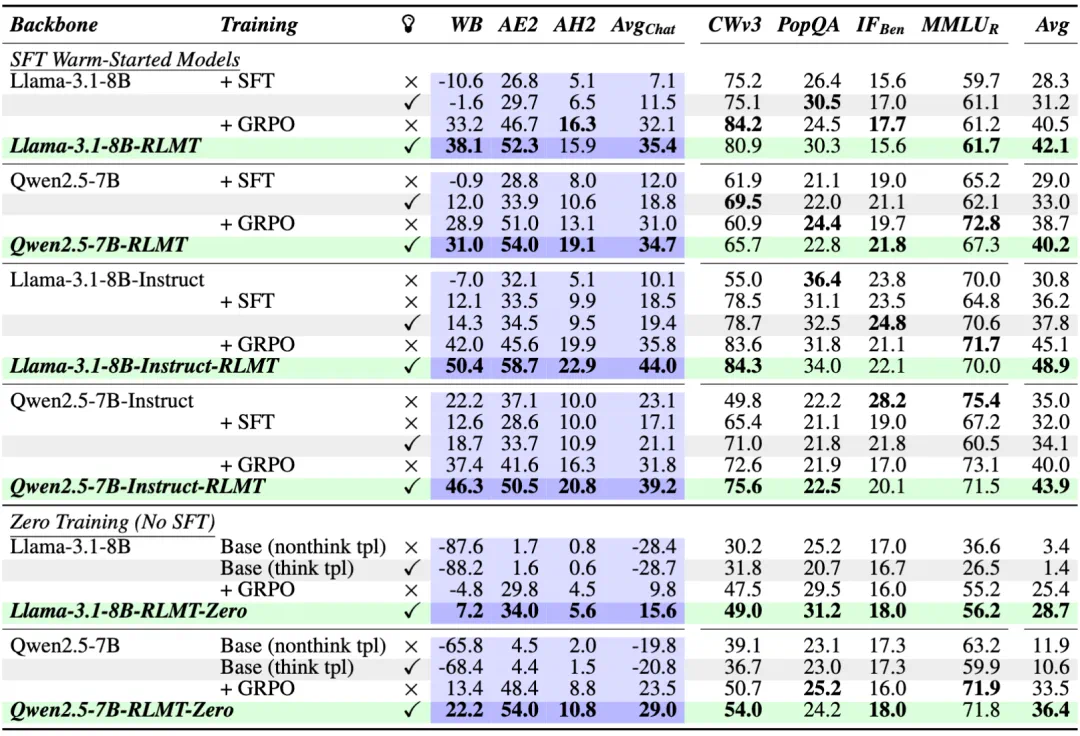
基于 GRPO 的实验结果。
实验比较了在 Llama-3.1-8B 和 Qwen2.5-7B(base 和 instruct 版本)上进行热启动 与 zero 训练的模型。表中展示了是否启用「思维」,其中 ✓ 表示 RLMT 模型,× 表示 RLHF 模型。
可以看到,启用思维的模型在表现上优于非思维基线模型,尤其是在聊天和创意写作任务上。主要关注点是聊天基准测试:WildBench (WB)、AlpacaEval2 (AE2) 和 ArenaHardV2 (AH2)。在评估未经训练的 base 模型时,研究团队使用了 思维模板 和 非思维模板 (tpl) 两种提示方式。
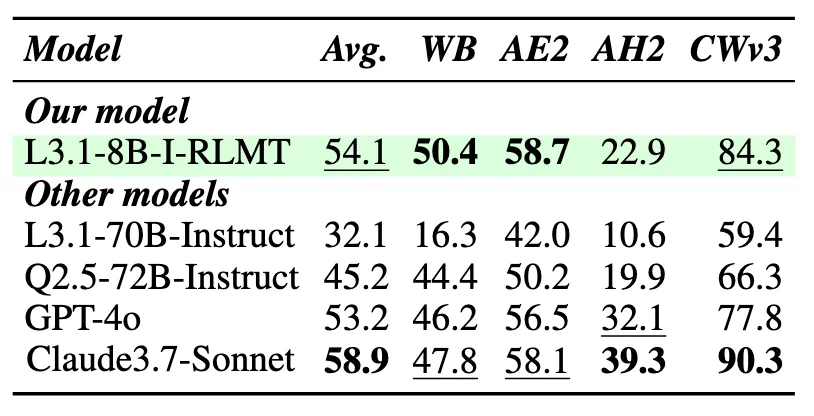
表 2:将 Llama-3.1-8B-InstructRLMT 与强大的开源和闭源模型进行比较,包括 GPT-4o 和 Claude-3.7-Sonnet。
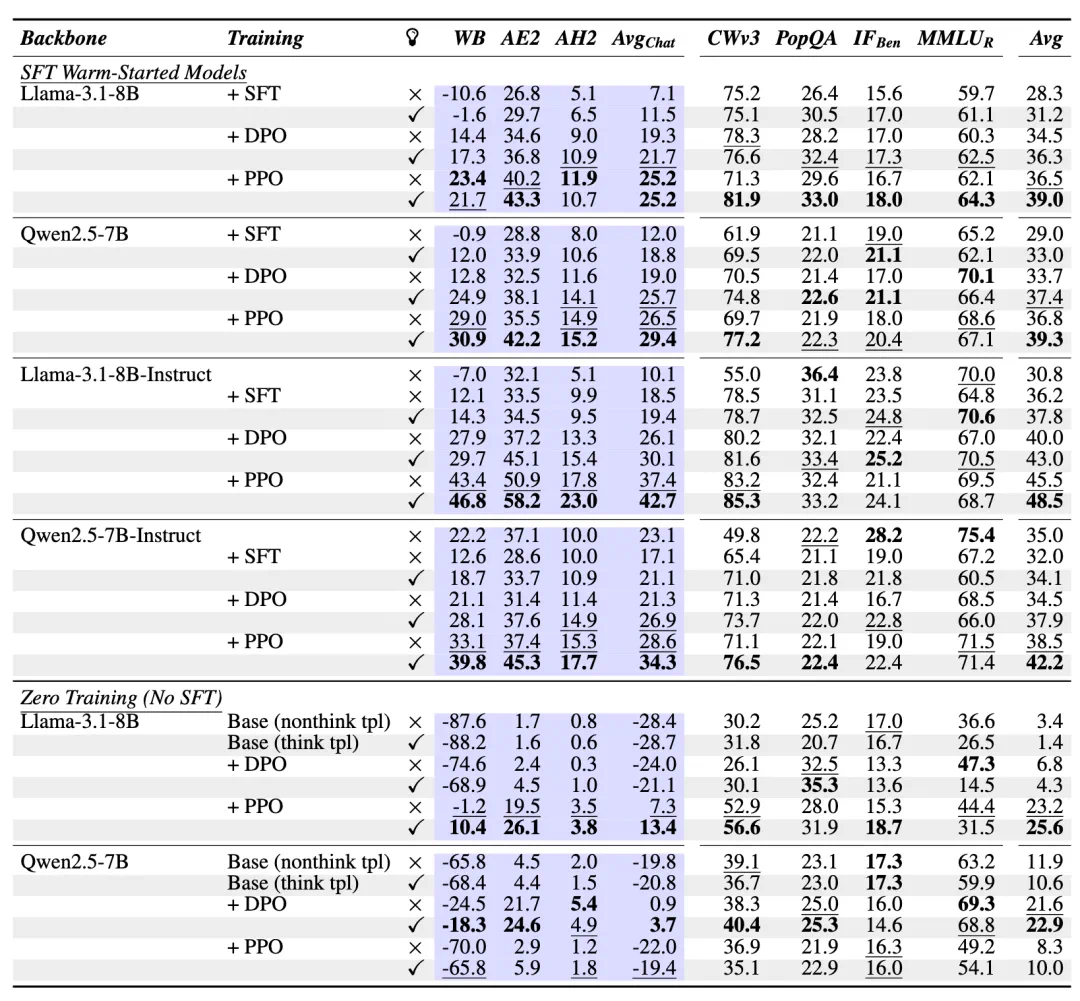
DPO/PPO 在 warm-start 和 zero training 设置下的结果。
从表中可以看到,Warm-start + RLMT 在 DPO/PPO 下依然有效,但整体落后于 GRPO;而在 zero training 设置下,DPO 和 PPO 相比 GRPO 效果明显不足。
RL 训练如何改变模型行为
研究团队分析思维模型(thinking models)在聊天基准测试上表现优异的原因。具体做法是,将 Llama-3.1-8B-Instruct-RLMT(最佳模型) 与其 仅 warm-start 但未经过 RLMT 的版本进行对比,结果发现:
SFT 模型的思维过程往往从分层规划开始(先列大纲、分小节、用 checklist 进行规划)。
RLMT 模型则更倾向于先列出约束条件和相关子主题,再将想法归为主题组,最后才规划具体细节。
规划风格上,SFT 模型是线性的,而 RLMT 模型是迭代式的:会回头修订之前的部分,比如交叉引用已提及的观点。
这些差异反映出 优秀写作者的思维习惯,而 RLMT 的训练能自然地诱发这些特质,令人鼓舞。
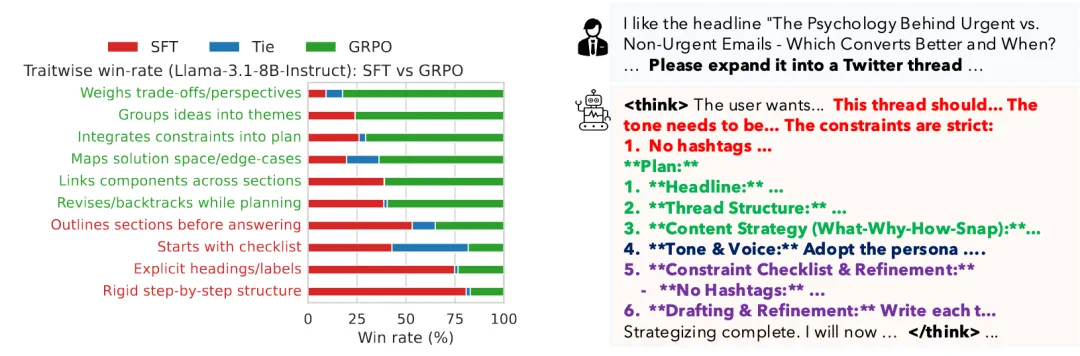
左图:展示了 SFT 模型与 GRPO 模型在不同思维特征上的逐项对比胜率。红色表示该特征在经过 GRPO 训练后减弱,绿色表示该特征增强。右图:给出了一段推理行为示例。当被要求撰写一个推文串时,模型首先梳理出题目要求的各种约束条件,然后规划推文的整体展开顺序。接着,它会通过 checklist 对全局进行检查,并标注出需要修正之处,最后才生成最终输出。
总结
RLMT 成功地将显式推理的优势从专业化领域扩展到通用对话式人工智能,在保持计算效率的同时实现了显著的性能提升。该方法在不同模型架构、训练算法和评测基准上的有效性,表明它具有广泛的适用性,并有潜力重塑我们对语言模型训练的方式。通过让模型「先思考再表达」,RLMT 代表着迈向更智能、更强大的对话式人工智能系统的重要一步。
更多细节,请参阅原论文。