
本文的主要作者来自北京航空航天大学、清华大学、香港大学和 VAST。本文的第一作者为北京航空航天大学硕士生黄泽桓。本文的通讯作者为北京航空航天大学盛律教授与 VAST 公司首席科学家曹炎培博士。
在游戏、影视制作、虚拟人和交互式内容创作等行业中,高质量的 3D 动画是实现真实感与表现力的基础。然而,传统计算机图形学中的动画制作通常依赖于骨骼绑定与关键帧编辑,这一流程虽然能够带来高质量与精细控制,但需要经验丰富的艺术家投入大量人力与时间,代价昂贵。
随着生成模型的快速发展,自动化的角色动画生成逐渐成为可能,为行业提供了新的解决思路。然而,现有方法存在显著局限:
基于动作捕捉的扩散模型或自回归模型只能在固定骨骼拓扑下工作,主要面向类人动作,难以推广至更广泛的角色类别;
基于视频生成模型的工作虽然能够生成多样化的动态序列,却往往依赖于高自由度的三维形变场优化,计算开销大、结果不稳定,往往需要耗时的优化过程。
为解决这一难题,北京航空航天大学团队提出了 AnimaX,一个高效的前馈式 3D 动画生成框架,并且支持任意类别的骨骼拓扑结构。

- 论文题目:AnimaX: Animating the Inanimate in 3D with Joint Video-Pose Diffusion Models
- 论文链接:https://arxiv.org/abs/2506.19851
- 项目主页:https://anima-x.github.io/
AnimaX 的核心思想是将视频扩散模型的运动先验与骨骼动画的低自由度控制相结合。创新性地将 3D 动作表示为多视角、多帧的二维姿态图,并设计了一种视频-姿态联合扩散模型,能够同时生成 RGB 视频与对应的姿态序列。
通过共享位置编码与模态特定嵌入,该模型实现了跨模态的时空对齐,有效地将视频中的丰富运动知识迁移到 3D 动画生成中。最终,通过反投影与逆向运动学将生成的姿态转化为 3D 动画。
总结而言,AnimaX 的主要贡献包括:
提出了 AnimaX,首个支持任意类别的骨骼拓扑结构,同时兼顾视频先验的多样性与骨骼动画的可控性的高效前馈式 3D 动画框架。
设计视频-姿态联合扩散模型,通过共享位置编码实现跨模态时空对齐,显著提升运动表达能力。
构建了一个涵盖约 16 万条绑定骨骼的 3D 动画数据集,包含人形、动物及其他多种类别,为训练通用的动画模型提供了重要资源。
效果展示:不限物体类别的 3D 骨骼动画生成
AnimaX 能够为多种类别的 3D 网格生成自然连贯的动画视频,不论是人形角色、动物还是家具与机械结构,都能实现时空一致的动作表现。不同于以往依赖高代价优化的方法,AnimaX 可以在几分钟内完成 3D 动画序列生成,并在保持动作多样性和真实性的同时展现出极强的泛化能力。
技术突破:基于视频扩散模型的任意骨骼动画生成
骨骼动画的局限与挑战
传统 3D 动画生成依赖骨骼绑定与关键帧设计,虽然能带来高质量和可控性,但需要大量人工成本。近期基于动作捕捉的扩散模型和视频生成模型提供了自动化可能性,但前者受限于固定骨骼拓扑,难以泛化至非人形角色;后者则依赖高自由度的形变场优化,计算昂贵、结果不稳定,甚至需要数十小时才能得到一条动画。
新思路:联合视频-姿态扩散建模
AnimaX 打破了这一局限。团队提出将 3D 动作重新表示为多视角、多帧的二维姿态图,并训练一个视频-姿态联合扩散模型,同时生成 RGB 视频与姿态序列。通过共享位置编码与模态嵌入,团队首次在视频和姿态之间实现了稳健的时空对齐,使视频扩散模型中学到的运动先验能够无缝迁移到姿态序列生成。
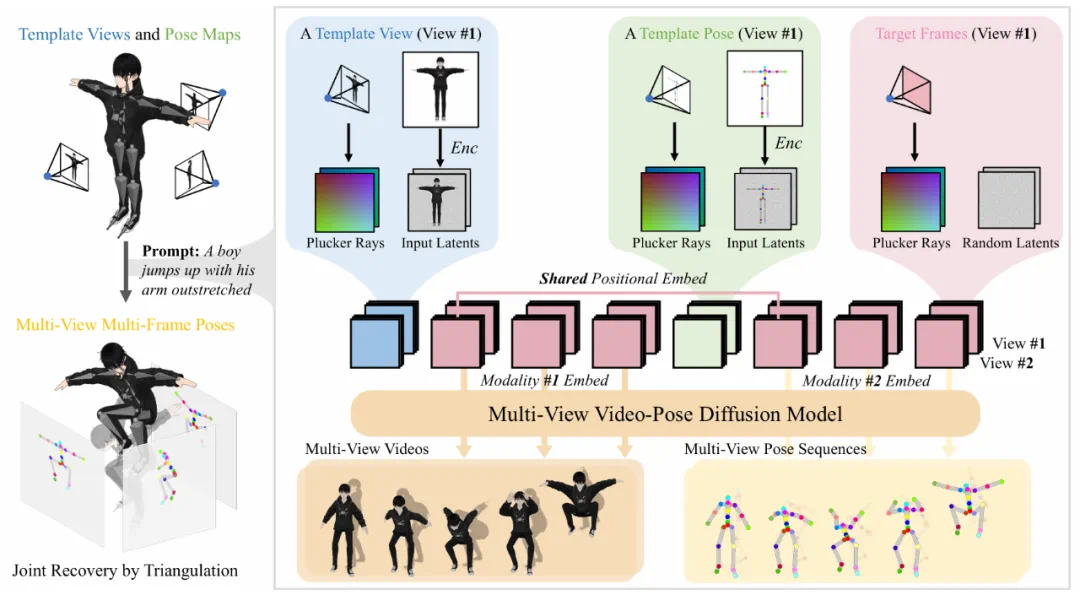
团队首先提出了一种姿态图表示方式,将三维骨骼的关节位置投影到二维图像平面,使模型能够精确定位姿态结构,为后续的三维动作重建打下基础。
在此基础上,研究者构建了一个视频-姿态联合扩散模型。该模型在原有视频扩散模型上引入了模态嵌入与共享位置编码,前者用于区分 RGB 与姿态两类信号,后者则确保两种模态在空间位置上的对齐,使模型能够同时学习 RGB 视频与姿态序列的联合分布。
通过这一机制,视频和姿态序列的生成过程得以在同一框架下协同进行。之后,为了进一步发挥视频扩散模型的时空建模能力,团队设计了一种统一序列建模策略,即将输入的模板图像(包括 RGB 与姿态图)与目标生成序列拼接在一起,再通过三维自注意力进行联合推理。这种方式使预训练模型的时空先验能够自然迁移,从而保证了输出动画的稳定性与连贯性。
最后,团队采用 Plücker ray 来编码相机参数,并在网络中加入多视角注意力机制以解决多视角不一致的问题,使得不同视角下的视频与姿态能够直接建立空间对应关系。得益于这一设计,生成的动画在不同相机角度下依然保持协调一致,避免了常见的视角漂移和形变不稳的问题。
3D 姿态重建与动画生成
在生成多视角姿态序列后,团队设计了一套高效的三维动作重建与动画生成流程:先通过聚类提取二维关节位置,再利用多视角三角化与最小二乘优化恢复三维关节坐标,最终通过逆向运动学将其映射为骨骼旋转驱动网格,从而生成自然流畅的三维动画。不同于以往依赖长时间迭代优化的方法,AnimaX 仅需数分钟即可得到结构合理、动作连贯的结果,并能够泛化到人形、动物乃至家具、机械等多种类别。
卓越性能:泛化的动画合成
团队将 AnimaX 与众多优秀的开源模型进行定性定量的对比。可以看到 AnimaX 的结果基本都优于现有方法,并在后续的人类偏好测试中取得了显著优势。
动画生成
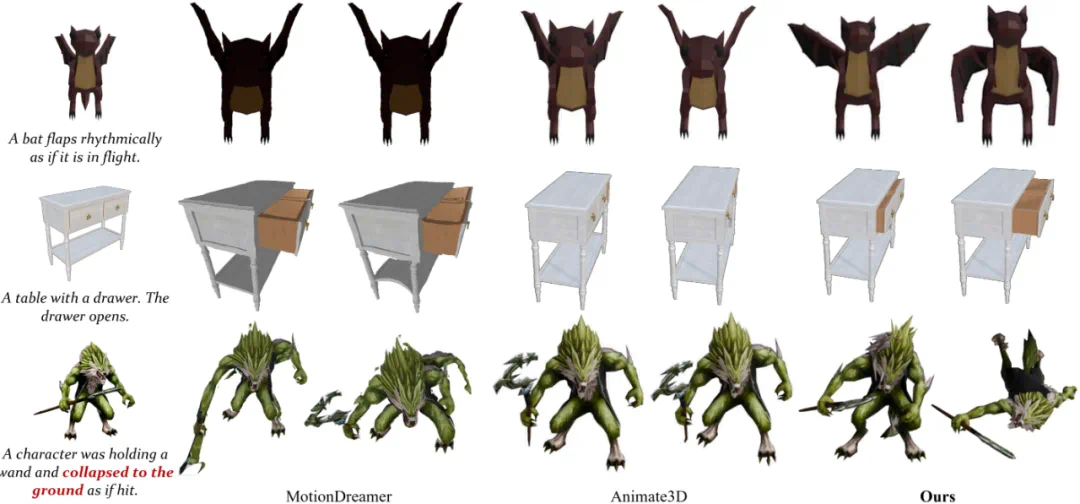
团队对比了 AnimaX、MotionDreamer 和 Animate3D。
从结果中可以看出,AnimaX 通过联合视频-姿态建模,将视频中的运动先验有效迁移到骨骼驱动的动画合成中,能够高质量地生成各类物体 3D 运动动画,并同时保持物体的一致性。
相比之下,MotionDreamer 依赖预训练视频扩散模型来监督模型形变,但由于形变场的自由度过高,约束能力有限,往往导致几何不一致和时序不稳定;Animate3D 则通过微调多视图视频扩散模型提升跨视角一致性,虽然在一定程度上减少了伪影,但重建过程困难,常出现几乎静止的结果。
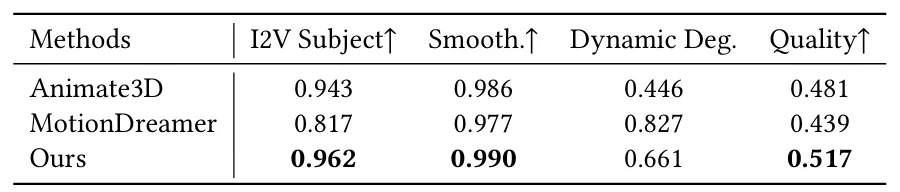
团队从 VBench 中选取了四个指标进行评测,包括主体一致性(I2V Subject)、运动平滑度(Smooth)、动态程度(Dynamic Deg.)和外观质量(Quality)。
结果显示,AnimaX 在除运动丰富度外的所有指标上均显著优于现有方法,尤其在外观质量上表现突出。而对于运动丰富度指标,团队通过进一步实验发现由于其对部分样本不够鲁棒,比如,在视频中物体突然消失也会产生虚高分数,因此难以说明视频的实际运动表现。
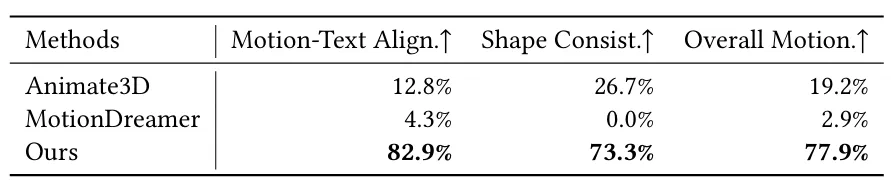
团队还额外进行了用户评测,以检验人类在实际使用中对不同方法的偏好。团队共招募了 30 位参与者,使其对测试集中不同方法的生成结果从动作与文本的匹配度、三维形体的一致性以及整体运动质量三个方面分别选择最佳结果。结果显示,AnimaX 在所有指标上均获得了最高偏好率,进一步说明了 AnimaX 将视频扩散模型的运动先验迁移到骨骼驱动的 3D 动画的做法具有更强优势。
消融实验
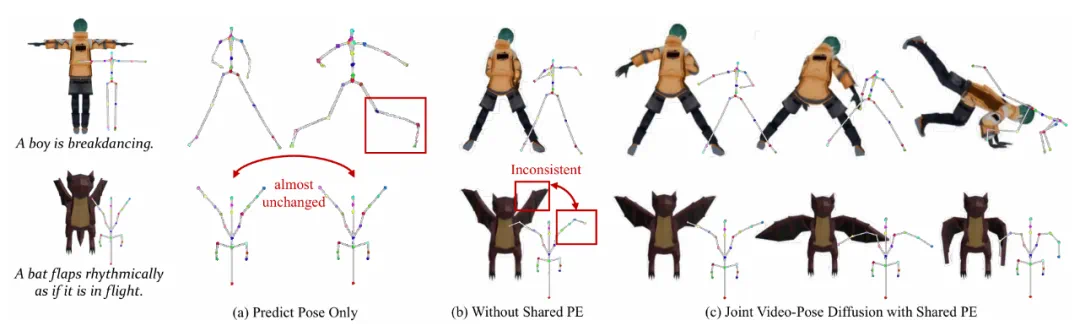
团队还进一步进行了消融实验,对比了三种不同的设置:
在视频扩散模型基础上仅生成动作序列;
同时生成视频与动作序列,但两种模态不共享位置编码;
完整的 AnimaX 模型,即联合视频-姿态生成并共享位置编码。
实验结果表明,方案 1 由于动作序列稀疏且与视频模态差异较大,难以充分利用视频先验,往往生成畸变或近乎静止的结果;方案 2 虽然一定程度缓解了问题,但视频与动作之间缺乏空间对齐,仍存在不稳定现象。
相比之下,完整的 AnimaX 模型通过共享位置编码实现了视频与姿态的紧密对齐,更好地继承了视频扩散模型的运动先验,在一致性与动作表现力上均显著优于其他对比方案,进一步验证了方法设计的有效性。
未来展望
AnimaX 研究团队提出了一种新方法,将视频扩散模型中可迁移的运动先验与骨架动画的结构化可控性相结合,实现对任意骨架结构的三维网格进行高效动画生成,为更灵活的多视角三维动画生成奠定了基础。
同时,AnimaX 的设计思路也为多个方向提供了新的可能性。一方面,联合视频-姿态建模不仅适用于骨骼动画,还可扩展到场景级动态建模,从而推动更广泛的 4D 内容生成;另一方面,当前方法基于单次前馈生成,未来可尝试结合长时序视频生成,以提升长程动画的连贯性与细节保真度,进而支持更复杂、更丰富的 3D 动画生成。


