 编辑丨&
编辑丨&ENCODE 计划(Encyclopedia of DNA Elements)中提到,人类基因组中仅 2% 序列编码蛋白质,其余 90% 非编码区的调控功能长期成谜。
了解人类生物学需要的不仅仅是绘制基因图谱,还必须了解基因表达是如何被调节的,以指导身体系统的健康发育、生长和维系。对于作为远端调控元件的增强子,其突变与先天性心脏病、肢体畸形等发育疾病密切相关。
劳伦斯伯克利国家实验室(Berkeley Lab) 和斯坦福大学的科学家们解决了传统体外实验复杂环境的干扰,通过转基因小鼠模型 + 机器学习,系统性绘制了人类发育增强子的突变敏感性图谱。
该研究以「In vivo mapping of mutagenesis sensitivity of human enhancers」为题,于 2025 年 6 月 18 日刊登于《Nature》。

论文链接:https://www.nature.com/articles/s41586-025-09182-w
增强子捕捉计划
远距离作用的增强子在动物发育过程中以组织特异性方式调节基因表达,它通过与转录因子(TFs)结合来发挥作用。
然而,由于对所有可能的 TF 结合事件、个体功能贡献以及结合 TF 之间的相互作用知之甚少,目前无法直接从 DNA 序列预测增强子活性,也就无法预测遗传变异如何影响基因表达。
最近改进的小鼠转基因工程技术方法已经使人们能够在胚胎体内整个生物体的水平上,对调控元件和突变效应进行大规模、敏感且可重复的评估(enSERT),而这给了团队灵感。
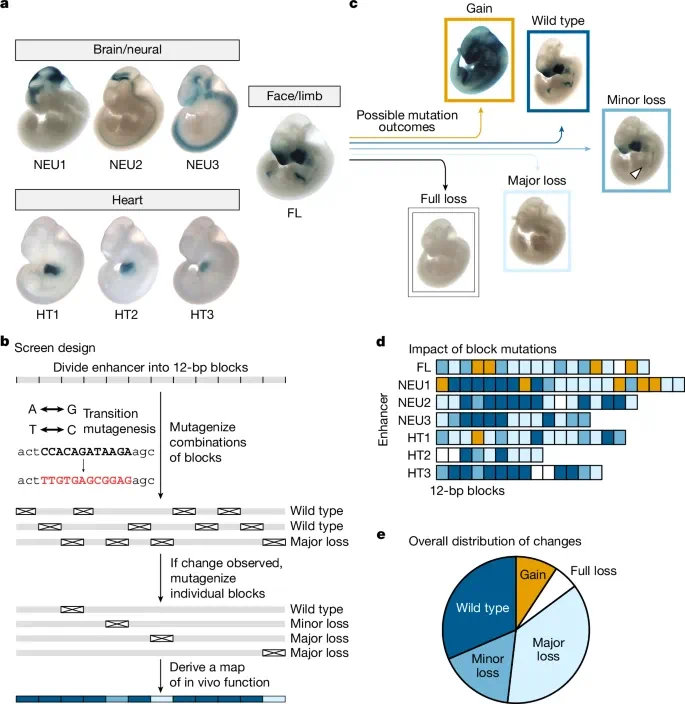
图 1:增强子的一般特性。
团队注意到了转基因小鼠的特质:它可以揭示序列变化对哺乳动物胚胎发育过程中增强子复杂空间活性模式的影响。
为此,团队精心准备了七个长度在 223 bp 到 431 bp 之间的增强子,创建了超过 1700 只转基因小鼠,涉及超过 260 种突变增强子等位基因。
这七个增强子包含 167 个诱变片段(每个片段长 12 bp)。对于每个增强子,团队还生成了一系列转基因报告基因构建体,这些构建体使用了一种转换诱变方案,旨在消除片段中可能存在的任何转录因子结合位点。
团队观察到,许多增强子的外围区域通常并不影响其功能。在七个增强子中,共有 108 个功能核心区域,6% 进行突变导致完全丧失功能,37% 导致主要丧失功能,17% 导致次要丧失功能,9% 导致功能获得,而在突变 31% 的情况下未观察到变化(如图 1-e)。
机器模型的分析与预测
全面的体内阻塞性突变增强子数据集为开发和评估预测单个核苷酸对正常体内增强子功能的重要性提供了独特的机会。
为此,团队训练了一个机器学习模型(ChromBPNet)来预测全基因组开放染色质信号,在碱基分辨率水平预测功能核苷酸,并通过 DeepLift 算法解析模型对转录因子结合基序的识别能力。
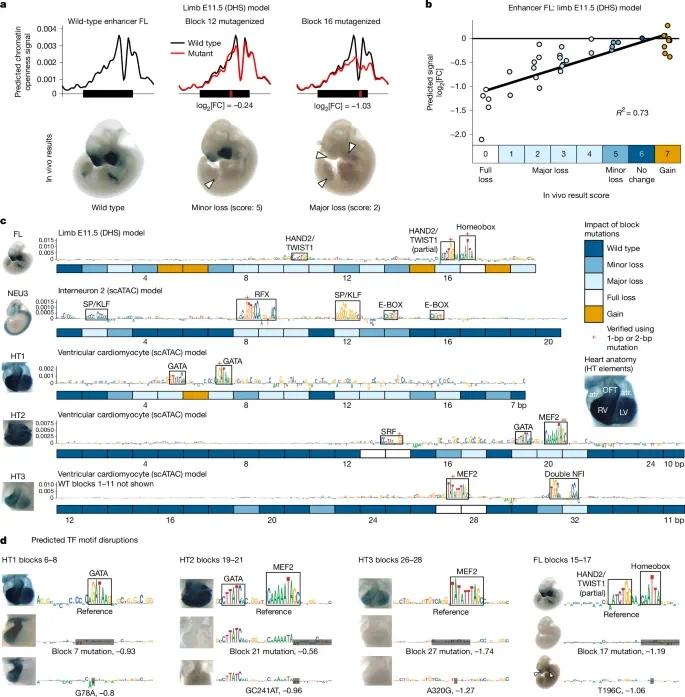
图 2:机器学习模型的选择与验证。
这些机器学习模型预测的绝大多数基序(88%)与体内功能的变化相吻合,模型显示出较高的敏感性,识别出了所有功能片段的 59%。
研究人类体内增强子中以累积方式存在的复杂相互作用的普遍性,团队系统地比较了单个 12bp 区块或此类区块配对突变对体内活性的影响。
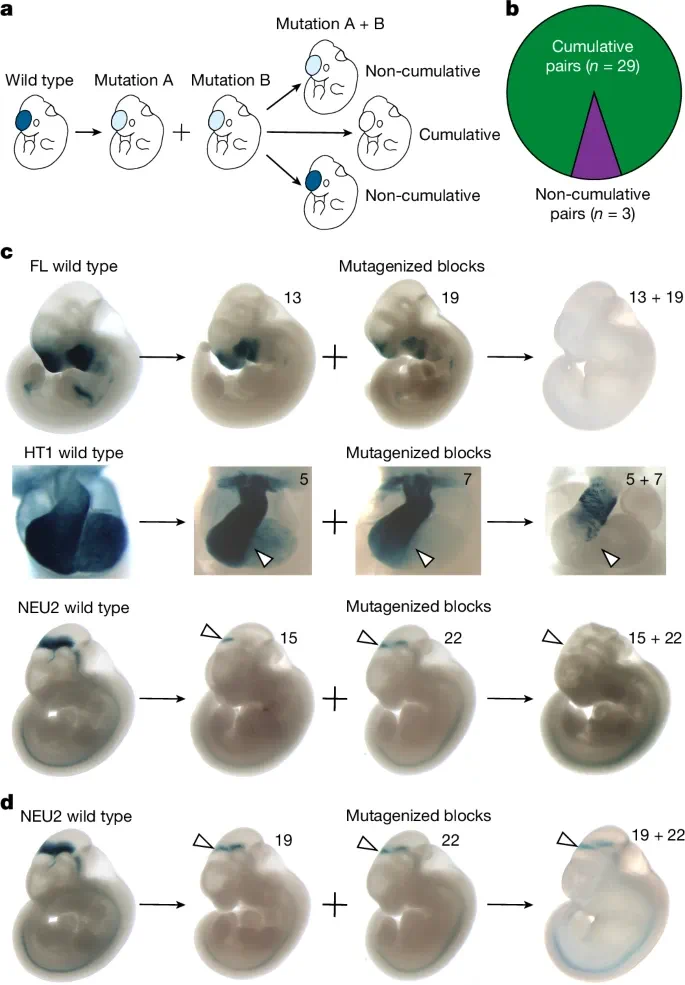
图 3:单个和配对区块突变的比较。
比较实验里,32 对片段中 29 对(91%)符合累积模型的模式(例如增强子 FL 的片段 13 和 19 的联合突变导致完全失活,而单独突变只会导致增强子活性不完全降低)。
上述实验结果表明,人类体内增强子内的大多数功能位点以累积的方式共同贡献于增强子的整体调节活性。
小结
为了研究个体中增强子如何在体内指导基因表达,团队对七个发育中的人类增强子进行了全面的体内突变图谱分析,生成了超过 1,700 个独立转基因小鼠胚胎。
不过经过实验团队的验证,尽管该模型可以通过搜索已知指示结合位点的序列模式来识别增强子的许多功能重要区域,但它也会错过其他至关重要的序列。
仅从目前来看,该模型所采用的数据集可以作为其他机器学习模型的基准,对于增强子内调控逻辑的发现为解释人类非编码变异和进化变化奠定了基础,并将有助于设计合成增强子以满足生物技术和治疗目的的需求。
代码链接:https://github.com/kundajelab