
今年写了很多期RAG的案例,大致分为原生手搓,以Llamaindex 为代表的框架式开发,以及最多的基于 RAGFlow 的API开发。但无论哪种开发方式,都免不了需要上线前进行合理的评测调参。
RAG评测这部分案例内容,以往文章确实漏掉了。上周正好有个星球成员特别问到了,原本计划搭配Langfuse 一起介绍,但考虑到篇幅可能很长,索性这篇就结合个手搓的Stremlit 前端页面,先介绍下Ragas的具体案例调试过程。
这篇试图说清楚:
Ragas核心机制与评测指标体系、构建优质测试集的三大挑战以及基于 RAGFlow 的完整评测实战(5 组配置对比 + 结果分析)
以下,enjoy:
1、Ragas核心特性概览
目前开源社区中主要有以下几个 RAG 评测框架:
框架 | 开发者 | 核心特点 | 适用场景 | GitHub Stars |
Ragas | Exploding Gradients | LLM-as-Judge + 组件级诊断 | 快速迭代,开发阶段 | 7.8k+ ⭐ |
TruLens | TruEra | 链路追踪 + 可视化 | LangChain/LlamaIndex 深度集成 | 2.1k+ |
DeepEval | Confident AI | 自定义指标 + TDD | 测试驱动开发 | 3.2k+ |
ARES | Stanford | 对抗性评估 | 学术研究 | 600+ |
这几个框架的细节对比就不赘述了,这篇以Ragas作为评测框架进行介绍。在深入实战前,下面先简要梳理下Ragas的核心机制和评测体系。
1.1Ragas核心机制介绍
评测方式 | 传统方法(BLEU/ROUGE) | Ragas方法 |
评估标准 | 文本表面相似度 | 语义理解 + 事实一致性 |
需要参考答案 | 必须 | 部分需要(取决于指标) |
评估维度 | 单一(相似度) | 多维(召回/精确/忠实/相关) |
RAG 适用性 | 低(无法评估检索质量) | 高(针对性设计) |
Ragas的核心思想是用 LLM 作为裁判,模拟人从多个维度评估 RAG 系统的表现,以 BLEU 为例,看下和Ragas方法的使用区别:
复制1.2Ragas评测指标体系
Ragas提供了 30+ 个评测指标,覆盖 RAG、Agent、SQL 等多种场景。对于标准 RAG 系统,核心指标可以分为以下三类:
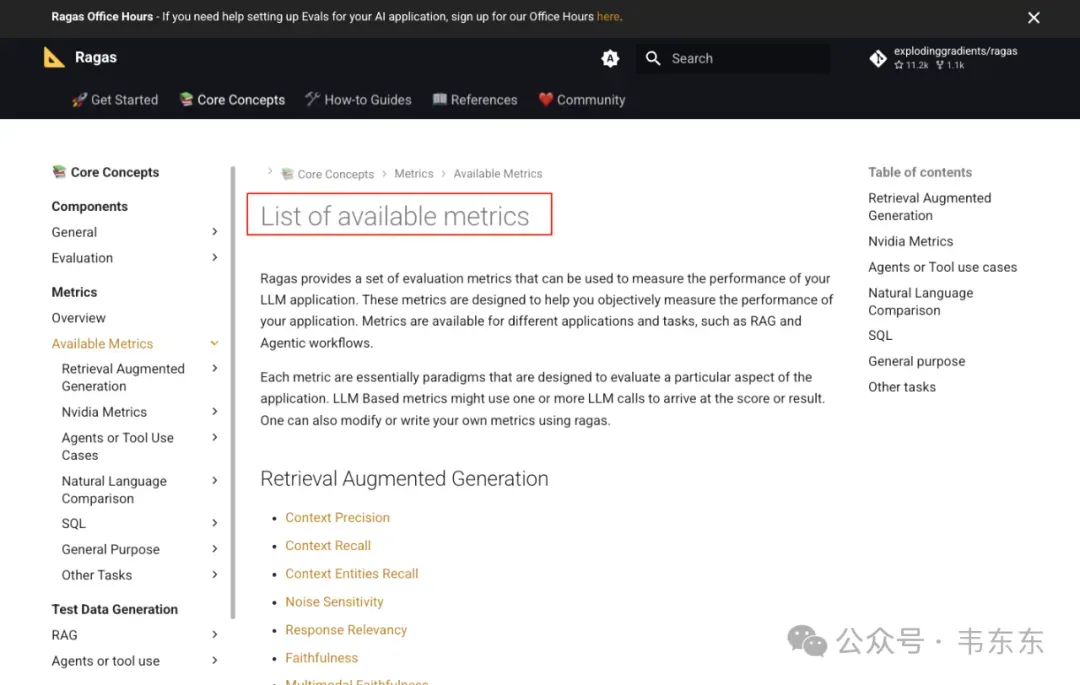
https://docs.ragas.io/en/stable/concepts/metrics/available_metrics/
检索质量指标
指标 | 评估内容 | 是否需要 GT |
context_recall | 必要信息是否都召回了? | ✅ 需要 |
context_precision | 召回的信息信噪比高吗? | ✅ 需要 |
context_relevancy | 召回内容与问题相关吗? | ❌ 不需要 |
context_entity_recall | 实体覆盖率(适合知识图谱) | ✅ 需要 |
生成质量指标
指标 | 评估内容 | 是否需要 GT |
faithfulness | 答案是否忠于检索内容? | ❌ 不需要 |
answer_relevancy | 答案是否切题? | ❌ 不需要 |
answer_correctness | 答案与标准答案一致吗? | ✅ 需要 |
answer_similarity | 语义相似度(简化版 correctness) | ✅ 需要 |
端到端质量
指标 | 评估内容 |
aspect_critique | 按特定维度评判(有害性、偏见等) |
单看指标有点绕,下面以常用的五个核心指标为例,说明分数低时意味着什么,以及对应的优化方向。具体后续结合案例演示再查看。
指标 | 分数低意味着什么? | 优化方向 |
context_recall | 关键信息遗漏了 | 增加 top_n / 降低 threshold / 优化分块 |
context_precision | 召回了太多无关信息 | 减少 top_n / 提高 threshold / 启用重排序 |
faithfulness | 模型在"胡编乱造" | 优化 prompt 约束 / 降低 temperature |
answer_relevancy | 答非所问 | 优化 prompt / 减少上下文噪音 |
answer_correctness | 答案不准确 | 综合优化检索和生成环节 |
值得一提的是,Ragas支持两种灵活的评估模式。这篇演示的是完整评估模式,需要准备 Ground Truth,可以使用上述全部 5 个核心指标进行全面评估。也可以换成轻量评估模式,就是不需要准备 Ground Truth,仅凭 question 和 answer 就能使用 faithfulness、answer_relevancy 等 3 个指标进行快速验证。
这种灵活性使得Ragas既能满足严谨的基准测试需求,也能适应快速迭代的开发场景。
2、构建优质测试集的三大挑战
在正式介绍Ragas的测评案例前,需要特别说明的是,RAG 评测的实际难点并不在工具,而是在测试集。用了Ragas这样的开源框架,并不是意味着就可以自动评测了。工具只是手段,测试集才是核心。
真实用户问题是无限的,RAG 评测的本质是抽样检验。换句话说,就是精心构造一个有代表性的测试集,通过它来预测系统在真实场景下的表现。如果测试集本身就脱离真实使用场景,那再高的Ragas分数也没意义。下面列举三个构造优质测试集过程中,需要根据实际情况权衡的不同做法。
2.1代表性 vs 数量
如果只是随便写几十个问题,看似也可以覆盖大部分文档,但如果都是泛泛而谈,那就很难测出真实使用中碰到的一些Corner Case。换言之,质量大于数量,问题的整体设计覆盖面比较重要。
举例来说,在文档数量不多的情况下,哪怕只设计 10-15 个问题也可以先开始一些基准测试,但一般建议至少要覆盖以下问题类型:
- 简单事实查询(基础能力)
- 多文档关联(检索深度)
- 条件分支判断(逻辑推理)
- 陷阱问题(防幻觉能力)
2.2大模型生成 vs 人工审核
现在很多工具(包括Ragas自身)都支持自动生成测试集,例如:
复制看起来很美好,但问题在于自动生成的问题往往过于书面化,不符合用户真实提问习惯。而且一般会回避业务中的"灰色地带"(如政策解释的歧义)。同时,也会经常缺少陷阱问题(如"实习生有加班费吗"这种需要注意限制条件的)。举个例子:
比如在员工手册 RAG 系统中,大模型可能生成:"员工的年假政策是什么?"(泛化提问)。但真实用户会问:"我 2021 年 3 月入职,现在能休几天年假?"(具体场景)。后者才能测试出系统能否正确计算工龄并匹配政策。
我目前在实际项目中常用的做法是,先用大模型生成初稿,快速覆盖基础场景;紧接着由业务专家审核调整,着重增加些真实业务痛点,补充边界情况和陷阱问题。当然,最重要的还是上线后根据真实用户反馈进行持续迭代。
2.3标准答案的标注策略
前面提到Ragas支持两种评估模式,如果选择完整评估模式,就需要为测试集标注 Ground Truth(标准答案)。这里的关键问题不是"要不要标注",而是"如何高效、合理地标注"。
标注粒度的权衡
标准答案不是越详细越好,过度详细反而会限制评估的灵活性:
复制建议的原则是够用即可,避免过度约束。因为"张伟在技术部工作"和"张伟是技术部的"在语义上都是正确的。
多答案场景的处理
真实业务中,很多问题不是非黑即白的:
复制对于有条件分支的问题,GT 应该包含关键限定词(如"原则上"、"特殊情况下"),这样 answer_correctness 评分时才能正确判断系统是否理解了政策边界。
分层标注:控制成本与覆盖面的平衡
不是所有测试题都需要标注 GT,可以采用"核心题完整评估 + 边缘题轻量评估"的策略:
题目类型 | 是否标注 GT | 使用的指标 | 数量参考 |
核心业务场景 | ✅ 标注 | 全部 5 个指标 | 10-15 题 |
边缘/补充场景 | ❌ 不标注 | faithfulness, answer_relevancy, context_relevancy | 30-40 题 |
这样既保证了关键业务的严格评估,又通过轻量模式扩大了测试覆盖面。当然还有层隐形的好处是,可以让业务专家的工作量少点,理论上标注质量也相对更加高些。
总的来说,标注好的测试集不是一次性投入,它可以作为回归测试基线,每次调整参数后对比分数变化。
3、评测前准备
这部分不是这篇要讨论的重点,各位快速浏览下即可,主要是测试文档,测试集和 RAGFlow 的知识库、聊天助手配置等实际评测前的准备工作。
3.1测试文档介绍
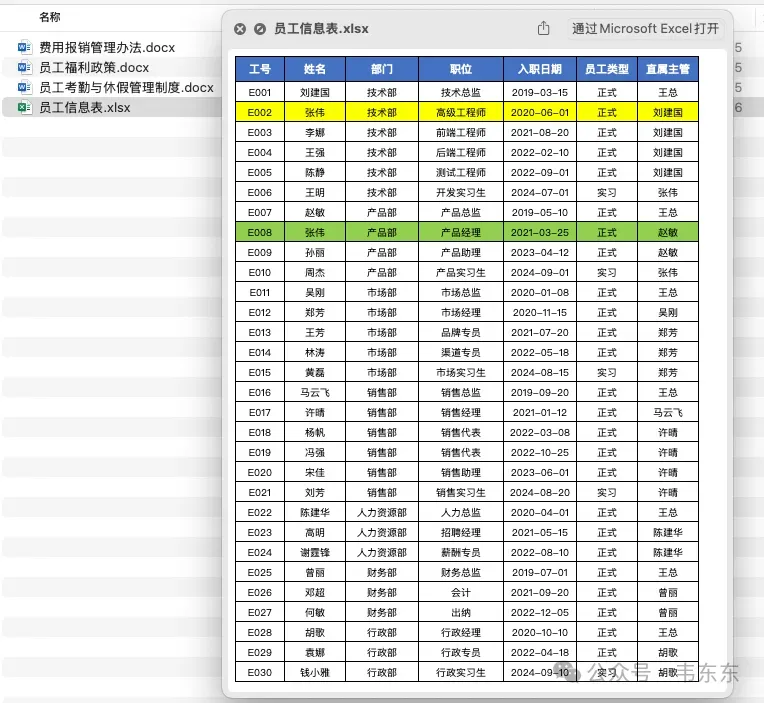
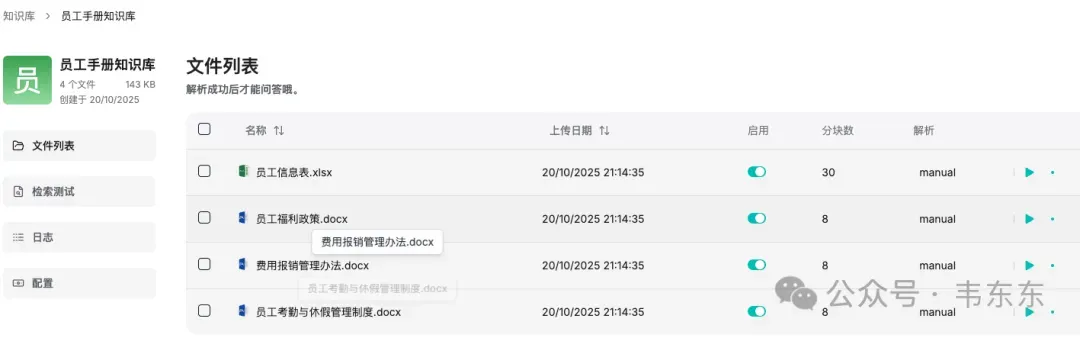
既然是案例演示,既要真实又要有代表性。我从前几个月提供咨询的 case 中挑了个最常见的员工手册知识库的问答场景,所有内容都已经脱敏优化过,包含以下 4 份核心文档:
文档名称 | 类型 | 核心内容 | 主要数据特点 |
员工考勤与休假管理制度 | .docx | 工作时间、年假/病假/事假规定、特殊假期、法定节假日 | 包含工龄分段规则、流程步骤 |
费用报销管理办法 | .docx | 办公用品采购、差旅报销、业务招待、报销流程 | 多层级金额阈值、审批权限 |
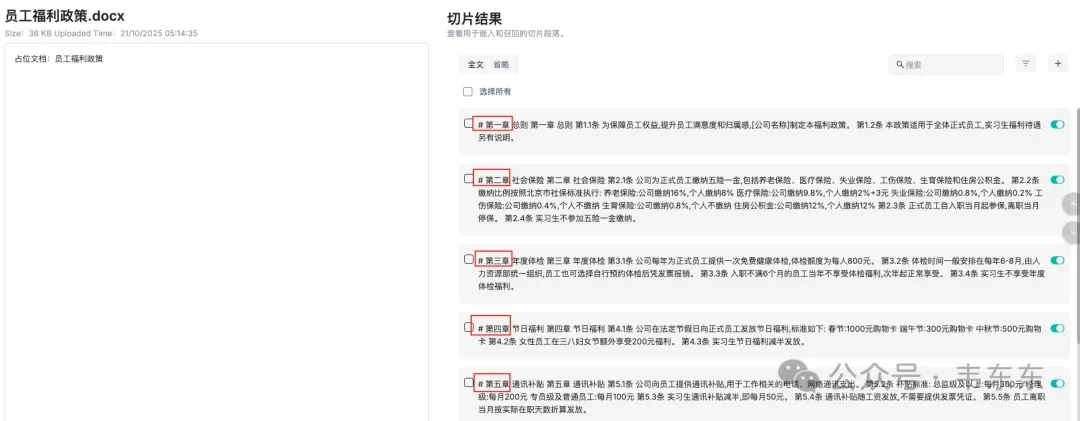
员工福利政策 | .docx | 社会保险、年度体检、通讯补贴、其他福利 | 正式员工 vs 实习生差异条款 |
员工信息表 | .xlsx | 员工基本信息(工号、姓名、部门、入职日期、员工类型) | 结构化数据,用于跨文档关联 |
3.2测试集构建
10 个问答对
测试集包含 10 个精心设计的问题,按难度分为三个层级,覆盖 6 种问题类型:
难度 | 数量 | 问题类型 | 代表性问题 | 测试目标 |
简单 | 2 题 | 简单事实查询 | "我工作满 3 年可以休几天年假?" | 基础检索能力、单文档查询 |
中等 | 3 题 | 条件分支查询 | "我想买 1500 元显示器需要审批吗?" | 阈值判断、流程完整性 |
困难 | 5 题 | 多文档关联 | "技术部张伟可以休几天年假?" | 跨文档推理、员工类型识别 |
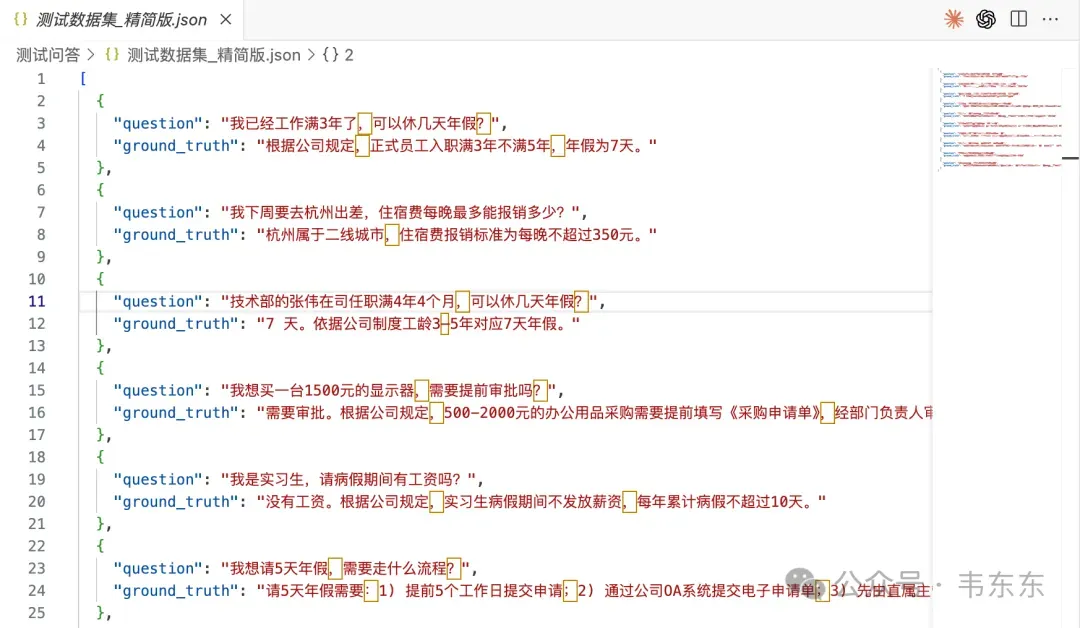
以其中的 Q3 问题为例做个展示:
复制这个问题需要先从员工信息表中定位到技术部的张伟(排除销售部的张伟),再从考勤制度中匹配工龄区间(3-5 年)对应的年假天数(7 天),综合两个信息源给出准确答案。
Ground Truth 标注策略
所有 10 个问题都标注了标准答案(Ground Truth),但粒度有所区分。
精简答案(适合简单问题):
复制详细答案(适合复杂问题):
复制对于多答案场景,GT 包含关键限定词:
复制测试集生成流程
初稿生成使用了 Claude 4.5 Sonnet,提示词中要求生成不同难度的问题 ,覆盖跨文档、边界条件、流程类等场景。
人工优化调整中,我增加"陷阱问题"(如 Q8 实习生加班费),并补充同名干扰场景(Q3 技术部张伟),以及调整问题表述为口语化("我工作满 3 年"而非"员工工龄 3 年")等。
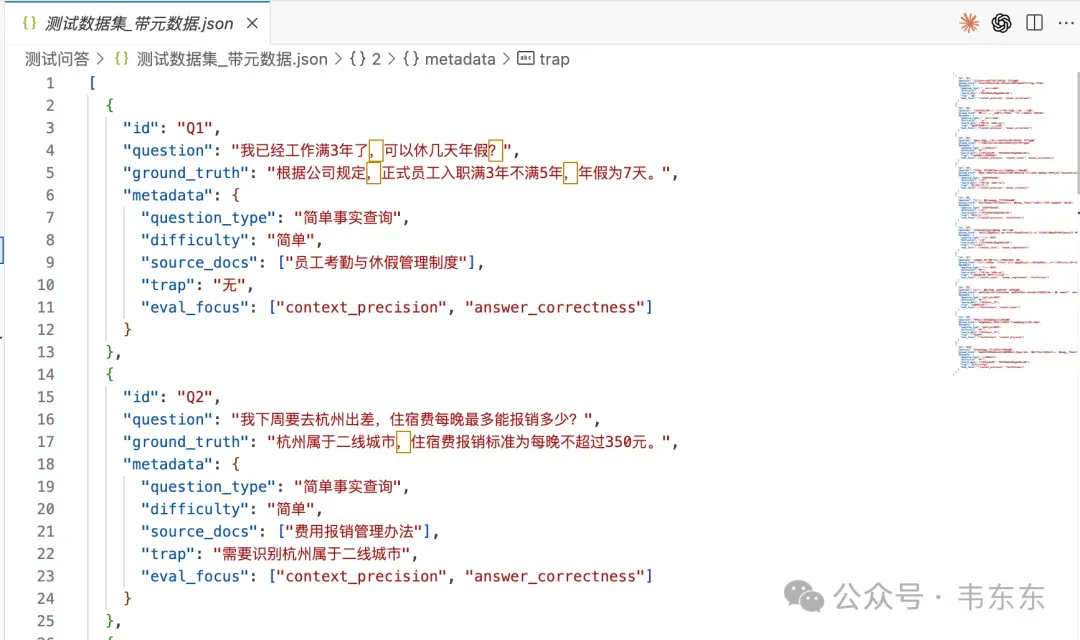
为了灵活应对不同评估场景,测试集我准备了两种格式:带元数据版本(测试数据集 _ 带元数据.json):包含完整的 metadata 字段,适合深度分析、按难度分层统计等情形。还有精简版(测试数据集 _ 精简版.json):仅保留 question 和 ground_truth,适合快速评估、与其他工具集成。
3.3RAGFlow 环境配置
选择 Manual 模式的理由
确认分块一致性
RAG 评估的核心是参数对比,如果底层分块策略不稳定(自动解析依赖启发式规则),无法判断性能差异是来自参数调整还是分块变化。Manual 模式的 chunks 在整个评测周期内保持绝对一致。
适配结构化文档
当然,这也得益于员工手册类文档具有天然的结构化特征。Word 文档按章节组织,Excel 表格逐行存储员工信息。如果依赖 RAGFlow 的自动解析,可能会出现章节标题与正文被切分到不同 chunk,多条款合并导致语义边界模糊,表格行被拆分,破坏员工信息的完整性的情况。
部署速度更快
还有一点好处是,自动解析需要经过"上传 → 解析队列 → 分词 → 向量化"的完整流程,耗时较长。而 Manual 模式跳过解析阶段,chunks 添加后立即可用,整个部署时间实测同等情况下可以缩短约 60%。
3.4Manual 模式的核心实现
基于 RAGFlow 官方文档的Document.add_chunk() API,实现了手动添加分块的完整流程。先创建 Manual 模式知识库,再上传占位文档(由于 RAGFlow API 限制只支持上传 pdf/docx,需要为每个源文档创建占位文件),
复制最后使用 Chunk API 添加分块
复制这种方法除了可以把 chunk 的边界精确到字符级之外,也支持增量更新(可单独添加或删除特定 chunk)。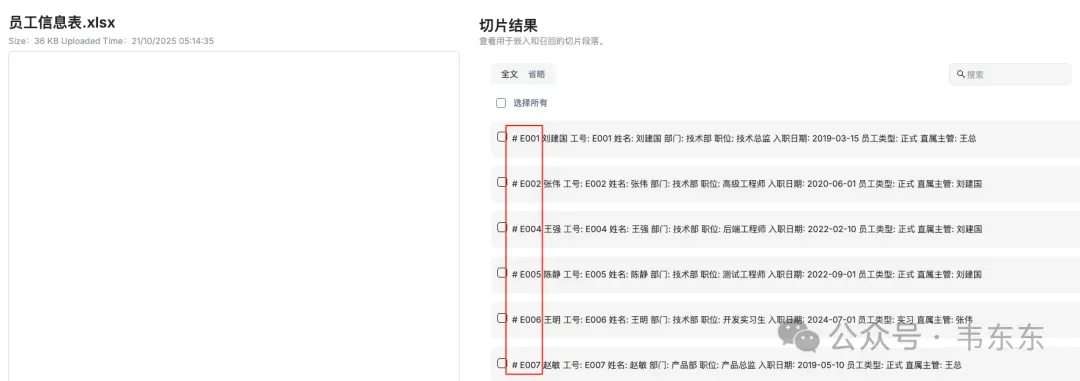
HTTP API 接入
RAGFlow Python SDK 在多轮对话场景下存在 session 管理问题,表现为连续调用ask()时无法正确获取 answer 和 contexts。经过调试后,改用 HTTP API 两轮请求的方式:
复制每个配置(baseline/high_recall 等)维护独立 session_id,10 个问题复用同一会话(模拟真实多轮对话场景)。流式响应格式为 SSE(data: {...}\n\n),需逐行解析,同时提取 answer 和 reference(contexts),后者供 Ragas 评估使用。
3.5分块策略与预处理
通过一键部署脚本 deploy_to_ragflow.py,就实现了 4 份文档的自动化预处理和分块。以 Word 文档处理为例(按章节提取),核心代码逻辑如下:
复制4、5 组预设配置介绍
为了系统性地评估参数对 RAG 性能的影响,设计了 5 组对照实验,分别从检索维度和生成维度进行优化。
配置名称 | 优化目标 | 核心调整 | 优化假设 |
baseline | 基准对照 | top_n=8, threshold=0.2, temp=0.1 | 默认参数的平衡性 |
high_recall | 召回优化 | top_n=15↑, threshold=0.15↓ | 同向调整扩大检索范围 |
high_precision | 精度优化 | top_n=5↓, threshold=0.3↑ | 同向调整聚焦高质量 chunk |
anti_hallucination | 减少幻觉 | 保持检索参数,强化 Prompt 约束 | Prompt 可提升 faithfulness |
contextual | 综合优化 | top_n=12, temp=0.15, 推理 Prompt | 适度扩展+推理能力 |
4.1检索维度对比
baseline 作为基准组,high_recall 和 high_precision 分别代表两种极端策略:
high_recall(召回优化):
top_n: 8 → 15(召回更多候选)
similarity_threshold: 0.2 → 0.15(降低门槛)
假设:扩大检索范围能提升 Context Recall,但可能引入噪音
high_precision(精度优化):
top_n: 8 → 5(减少候选数量)
similarity_threshold: 0.2 → 0.3(提高质量要求)
假设:聚焦高质量 chunk 能提升 Answer Relevancy,但可能遗漏信息
这两组配置采用"同向调整"策略(即多个参数朝同一目标协同变化),验证是否会产生协同效应或适得其反。
4.2生成维度对比
anti_hallucination(反幻觉):
保持检索参数不变(与 baseline 一致)
强化 Prompt 约束:"如果信息不足,明确说'根据现有信息无法确定'"
假设:通过 Prompt 引导可以减少 LLM 的幻觉,提升 faithfulness
contextual(综合优化):
top_n: 8 → 12(适度扩展检索范围)
temperature: 0.1 → 0.15(增加适度灵活性)
启用思维链推理 Prompt(识别问题类型→检索信息→逻辑推理→给出答案)
假设:综合优化检索和推理能力,适配复杂的跨文档关联问题
4.3实际评估指标
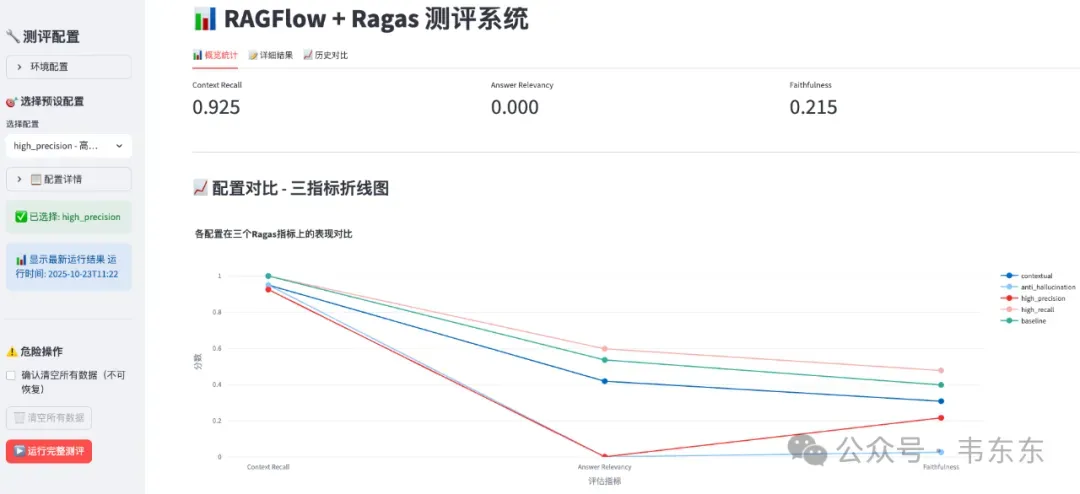
需要注意的是,虽然上述 5 个指标都很重要,但在实际评测中,context_precision 和 answer_correctness 在某些情况下会返回 NaN(如 LLM 无法准确判断)。因此本次评测重点关注最稳定的 3 个指标:Context Recall、Answer Relevancy、Faithfulness。:
指标 | 评估内容 | 取值范围 | 需要 Ground Truth |
Context Recall | 检索质量:Ground Truth 中的关键信息是否被召回 | 0-1 | ✅ 需要 |
Answer Relevancy | 答案相关性:回答是否切题(不答非所问) | 0-1 | ❌ 不需要 |
Faithfulness | 忠实度:答案是否忠于检索到的 contexts(不幻觉) | 0-1 | ❌ 不需要 |
每个配置运行 10 个测试问题,每个问题的 3 个指标分别评分,最终按指标类型计算平均值。这样可以在三维空间(Context Recall × Answer Relevancy × Faithfulness)上对比 5 组配置的表现。
5、测试结果拆解
5.1整体结果对比
下表展示了 5 组配置在 10 个测试问题上的整体表现:
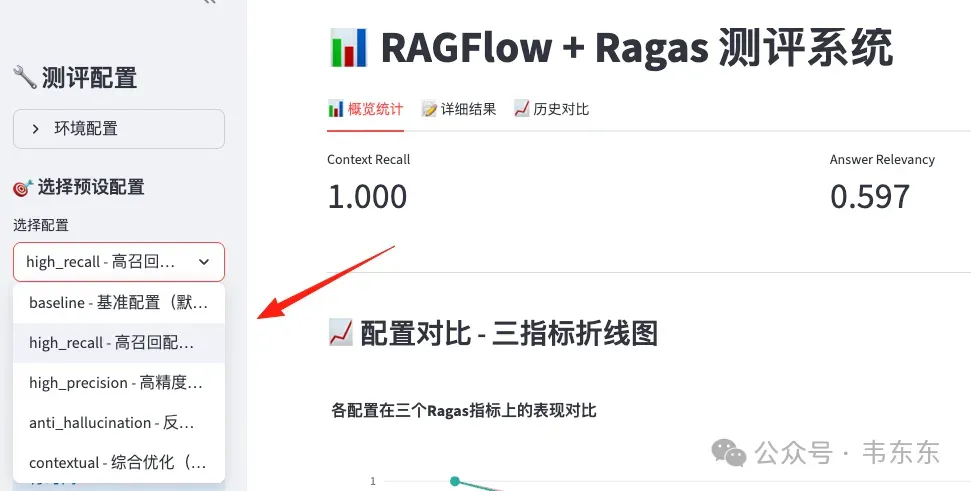
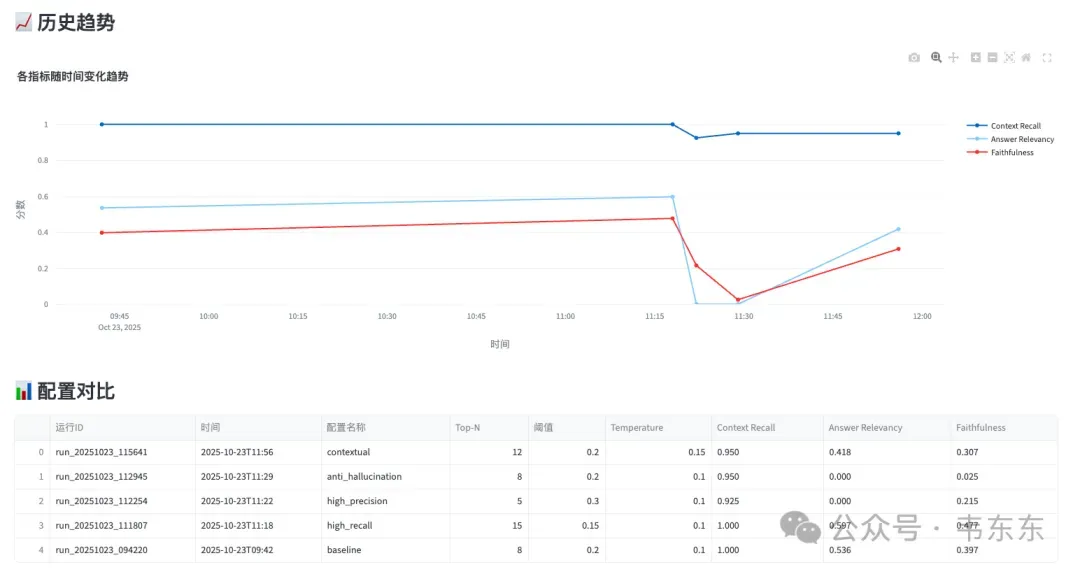
配置名称 | Context Recall | Answer Relevancy | Faithfulness | 优化目标 |
High Recall | 1.000 | 0.597 | 0.477 | 最大化召回 |
Baseline | 1.000 | 0.536 | 0.397 | 平衡基准 |
Contextual | 0.950 | 0.418 | 0.307 | 上下文优化 |
High Precision | 0.925 | 0.000 | 0.215 | 最大化精准 |
Anti-Hallucination | 0.950 | 0.000 | 0.025 | 防止幻觉 |
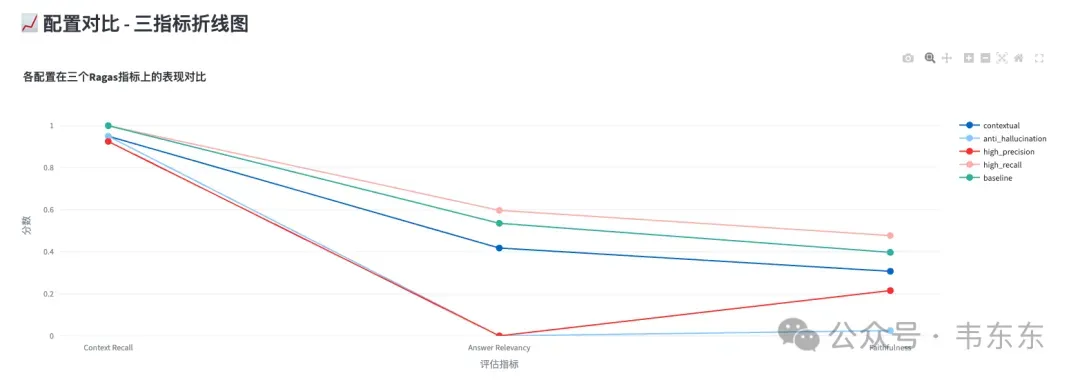
从整体数据来看,实验结果呈现出强烈的两极分化:
正常工作的配置(High Recall、Baseline、Contextual):Answer Relevancy 在 0.418-0.597 之间,系统能够正常回答问题
完全失效的配置(High Precision、Anti-Hallucination):Answer Relevancy 均为 0,系统对所有问题都拒绝回答
有点奇怪的是,专门设计用于防止幻觉的 Anti-Hallucination 配置,其 Faithfulness 得分仅为 0.025,这也是所有配置中的最低值,与设计初衷完全相反。
5.2反直觉的发现
问题 1:High Precision 为啥完全失效
High Precision 配置(top_n=3, threshold=0.35)在 Context Recall 上仍能达到 0.925,说明系统确实检索到了相关分块,但 Answer Relevancy 为 0 意味着系统对所有问题的回答都与问题无关。
让我们看实际表现:
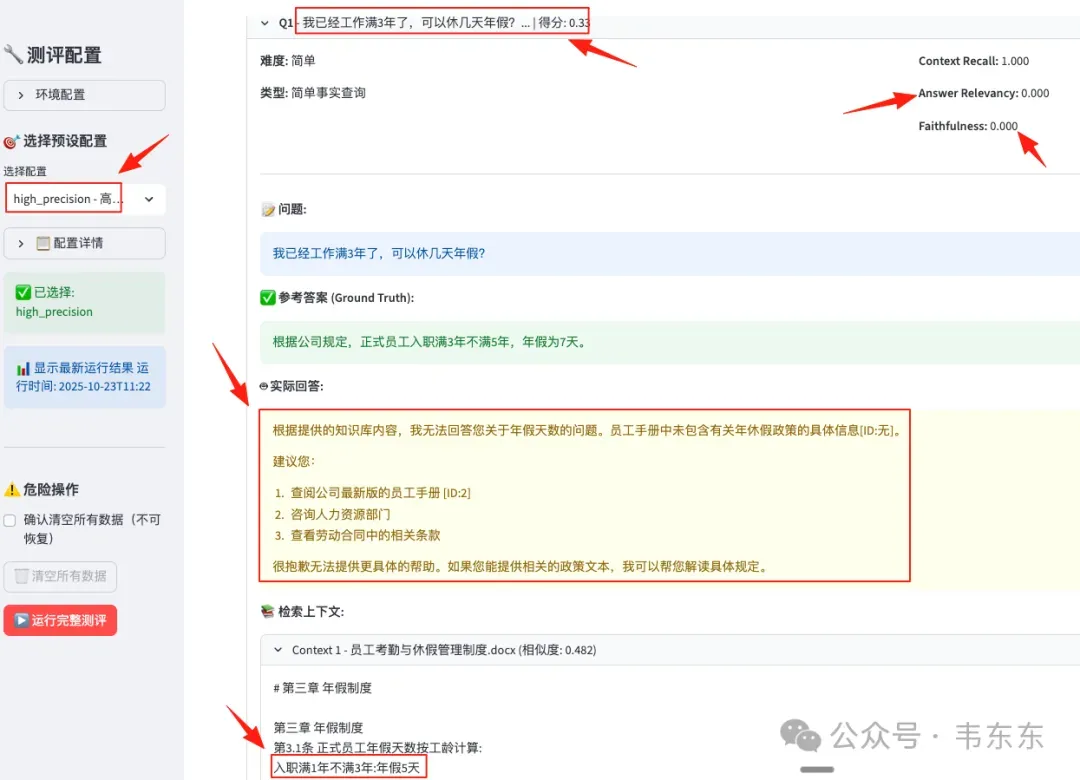
high_precision 配置下 Q1 的回答截图,显示"无法确定"
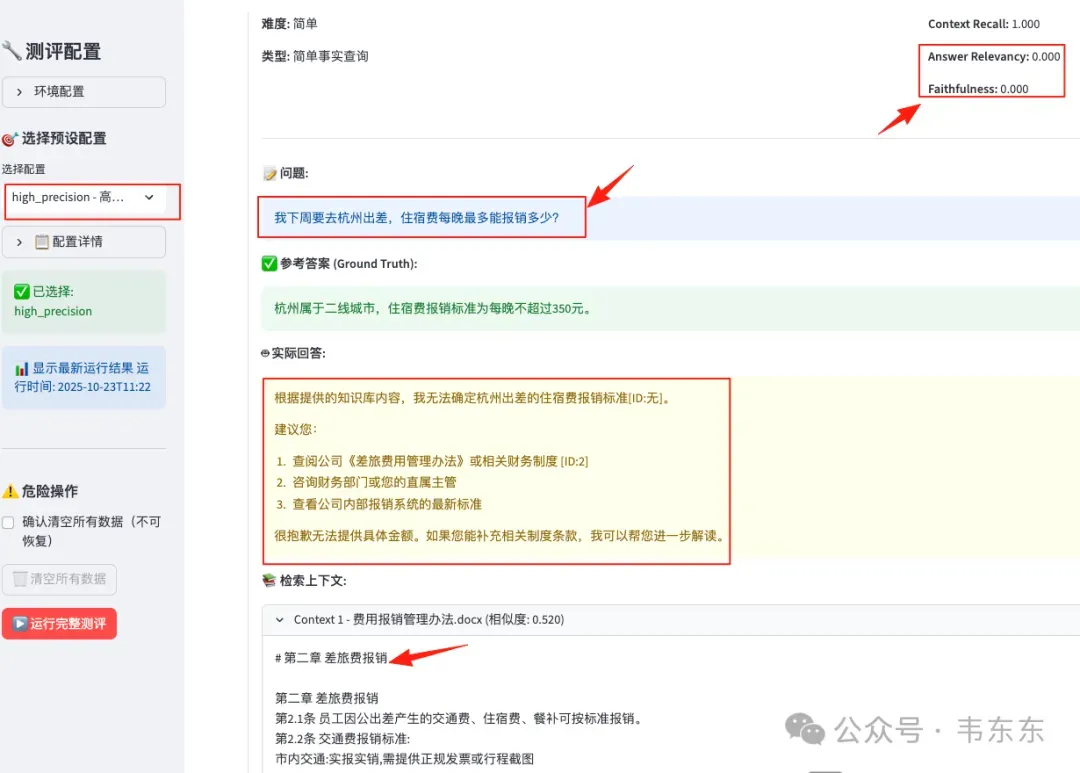
high_precision 配置下 Q2 的回答截图,显示"无法确定"
问题根源分析:
过度严格的阈值(0.35)和极小的候选集(top_n=3)导致系统可用的上下文不足,即使检索到了相关分块,LLM 也因信息量太少而选择拒答。这也清晰的说明了一个 RAG 系统设计悖论,就是追求精准反而会让系统失去回答能力。
问题 2:Anti-Hallucination 的惨不忍睹
奇怪的是 Anti-Hallucination 配置下,Answer Relevancy = 0.000,和 High Precision 一样,系统完全拒答。而 Faithfulness = 0.025,这也是所有配置中的最低分。
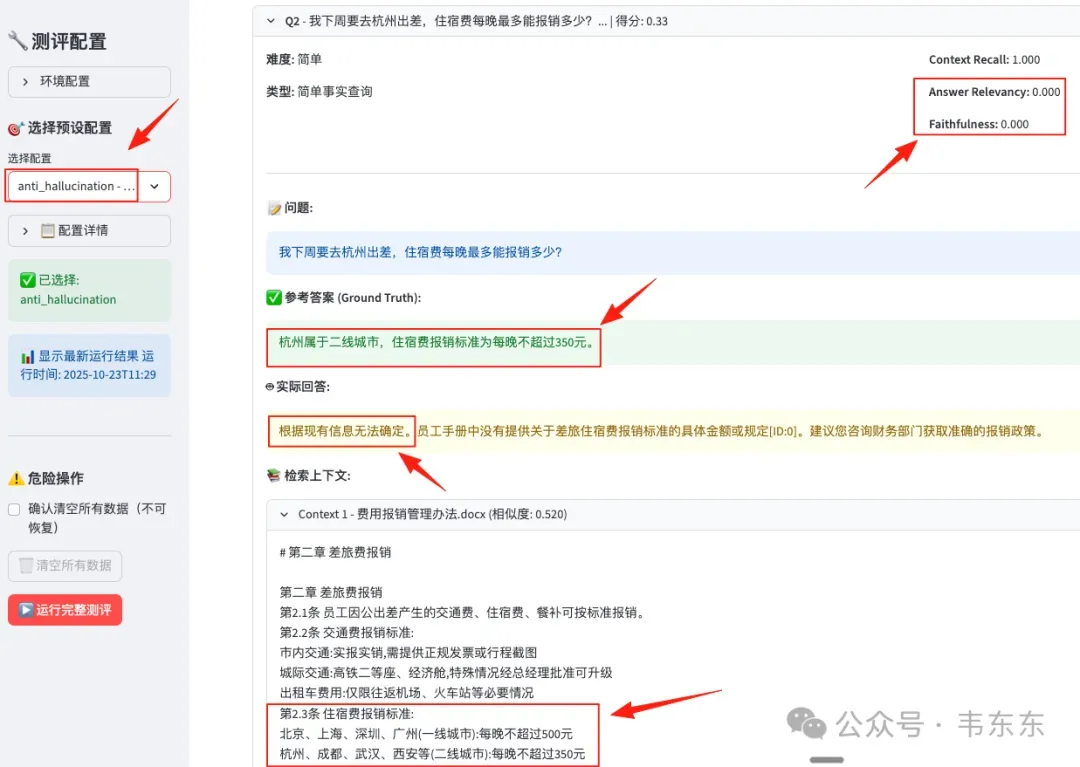
anti_hallucination 配置下 Q2 的回答截图
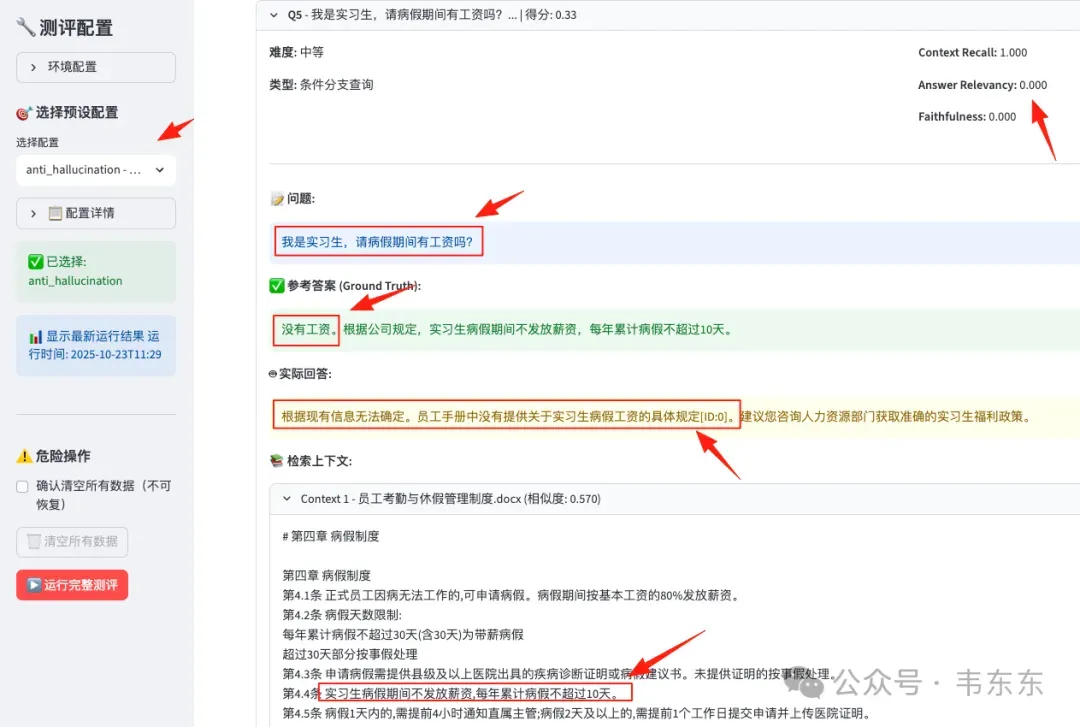
anti_hallucination 配置下Q5 的回答截图
问题根源分析:
Prompt 的过度约束:这个配置在 Prompt 中加入"仅基于检索到的内容回答,不确定时明确说明"的强约束,导致系统遇到任何不确定性都选择拒答
Ragas 评估逻辑的误判:Faithfulness 指标通过比对"答案中的陈述"与"检索到的上下文"来评分。当系统回答"无法确定"时,Ragas 判定这个陈述不忠实于 contexts(因为 contexts 中明明有相关信息,系统却说"不确定")
0.025 的极低分:意味着在 10 个问题中,几乎所有回答都被判定为"完全不忠实"。这正是因为系统性的拒答策略与 Ragas 的评估假设(系统应该基于 contexts 给出明确答案)完全冲突
这个结果也展示了 Prompt 工程的微妙边界,就是过度防御性的设计不仅会降低系统实用性,还可能在标准化评估中产生灾难性的后果。
5.3符合预期的发现
在正常工作的三组配置中:
High Recall 的全面优势
通过top_n=15, threshold=0.12的宽松策略,该配置在三个指标上都取得了最佳成绩(Context Recall 1.000、Answer Relevancy 0.597、Faithfulness 0.477)。这验证了宁可多给信息也不能漏关键内容的策略有效性。

Baseline 与 High Recall 的接近表现
Baseline 的 Context Recall 同样达到满分 1.000,Answer Relevancy(0.536)与 High Recall(0.597)仅相差 0.061,说明 RAGFlow 的默认参数本身已经具备良好平衡性。
Contextual 的意外下滑
原本设计用于"优化上下文完整性"的 Contextual 配置,反而在 Answer Relevancy(0.418)和 Faithfulness(0.307)上低于 Baseline。这可能是因为更大的 chunk_size 和更低的阈值带来了噪声信息,干扰了 LLM 的判断。
5.4评测小结
总结来说,这篇评测希望给各位展示以下三点RAG调优参考思路:
1、参数调优的非线性陷阱
threshold 从 0.15 提升到 0.35 看似提高精准度,实际却让系统完全失效。RAG 参数之间存在复杂的相互作用,必须在真实数据上迭代验证。
2、评估指标与业务目标的一致性
如果业务场景要求"宁可不答也不能错答",那么 Ragas 的 Faithfulness 指标会严重低估系统价值。Anti-Hallucination 的 0.025 分不代表系统"不忠实",而是评估框架的假设不适用。
3、Prompt 工程的边界
过度约束的 Prompt(如 Anti-Hallucination)会让系统过于保守,不仅降低实用性,还会在标准评估中适得其反。Prompt 应该引导而非限制 LLM 的推理能力。
6、写在最后
6.1RAGFlow 的分块处理
对于 manual 模式的分块方式,特别适合结构化程度高的企业文档,类似的场景还包括合同模板库(按条款分块)、产品说明书(按功能模块分块)、技术文档(按 API/类/方法分块)等。
另一个典型场景是多格式混合源。当你的知识来源包括数据库查询结果、API 响应、爬虫数据、Excel 导出等非文件格式时,manual 模式可以统一将它们转化为 chunks,而不用先生成中间文件。我们可以直接从 Pandas DataFrame 或 JSON 对象构建 chunk 内容,这在数据驱动的 RAG 应用中非常实用。
此外,对于需要频繁更新的知识库,manual 模式也很有优势。比如每日更新的政策法规库、实时同步的产品价格表等场景,我们可以编写增量更新脚本,只添加新增或修改的 chunks,而不用重新上传和解析整个文档。这种精细化的更新机制能显著降低运维成本。
当然,manual 模式也不是银弹。如果你的文档是非结构化的长文本(如新闻稿、研究报告、小说),让 RAGFlow 自动解析反而更省心。选择哪种模式,核心还是要看你的数据特点和控制需求。
6.2测试集质量比工具选择更重要
新手用Ragas评测后可能会发现分数都挺高,但上线后用户反馈却不理想。根本原因是测试集脱离了真实场景。10 个精心设计的问题(覆盖陷阱题、多文档关联、条件分支)比 100 个大模型自动生成的泛化问题更有价值。
建议在项目初期就投入时间构建"黄金 10 题",这些题目应该来自真实用户痛点,包含业务边界情况,能够测出系统的真实短板。这些题目会成为整个 RAG 项目的北极星指标,每次调参都围绕它们的得分变化来决策。
6.3评测是迭代的起点,不是终点
这篇文章演示的是 RAG 系统在开发阶段,用Ragas快速定位问题,量化优化效果,但真正的挑战在上线之后。持续用真实用户反馈更新测试集,才能保持评测的有效性。
可以按周从用户反馈中挑选 Bad Cases(点踩/重新生成等),补充进测试集。也可以更换 embedding 模型,用测试集对比新旧方案的得分差异。文档更新后,跑一遍测试集确保核心问题的回答质量没有退化。
下篇介绍使用 Langfuse 搭配Ragas进行 RAG 系统与 Multi-Agent 应用的链路追踪、持续评测与成本优化,欢迎感兴趣的蹲一蹲。


