
8月中旬的时候,我去MinerU的办公室交流过一次。当时对方有位工作人员表示,接下来会很快基于视觉模型的路线实现全面 SOTA。说实话,那个时候我还挺怀疑的。毕竟,那个时候MinerU2.0从6月中旬算起,已经发布了快两个月。但我在手头一些复杂布局的项目文档测试发现,实际和Textin这种闭源产品还是有不小差距。
然后,MinerU2.5.4 在9月26 号更新后,我又上手测试了些之前的 corner cases,这次不得不说效果惊艳了很多。虽然依然因为YOLO的许可协议限制,沿用了 AGPL-3.0 的许可证,但是作为开源项目还是值得拆解学习下其中的很多工程思路。
这篇试图说清楚:
MinerU2.5的性能评测效果、双后端架构设计梳理、核心实现原理源码拆解、部署与许可证注意事项,以及企业集成与扩展参考。
1、MinerU2.5评测效果
1.1基准测试情况
根据官方发布的技术报告文档(https://arxiv.org/abs/2509.22186),MinerU 2.5 在权威的 OmniDocBench 基准测试中,实现了全面 SOTA,尤其是在布局检测、文本识别、表格识别、公式识别等关键指标上,也超过了 Gemini 2.5-Pro、GPT-4o 等模型。
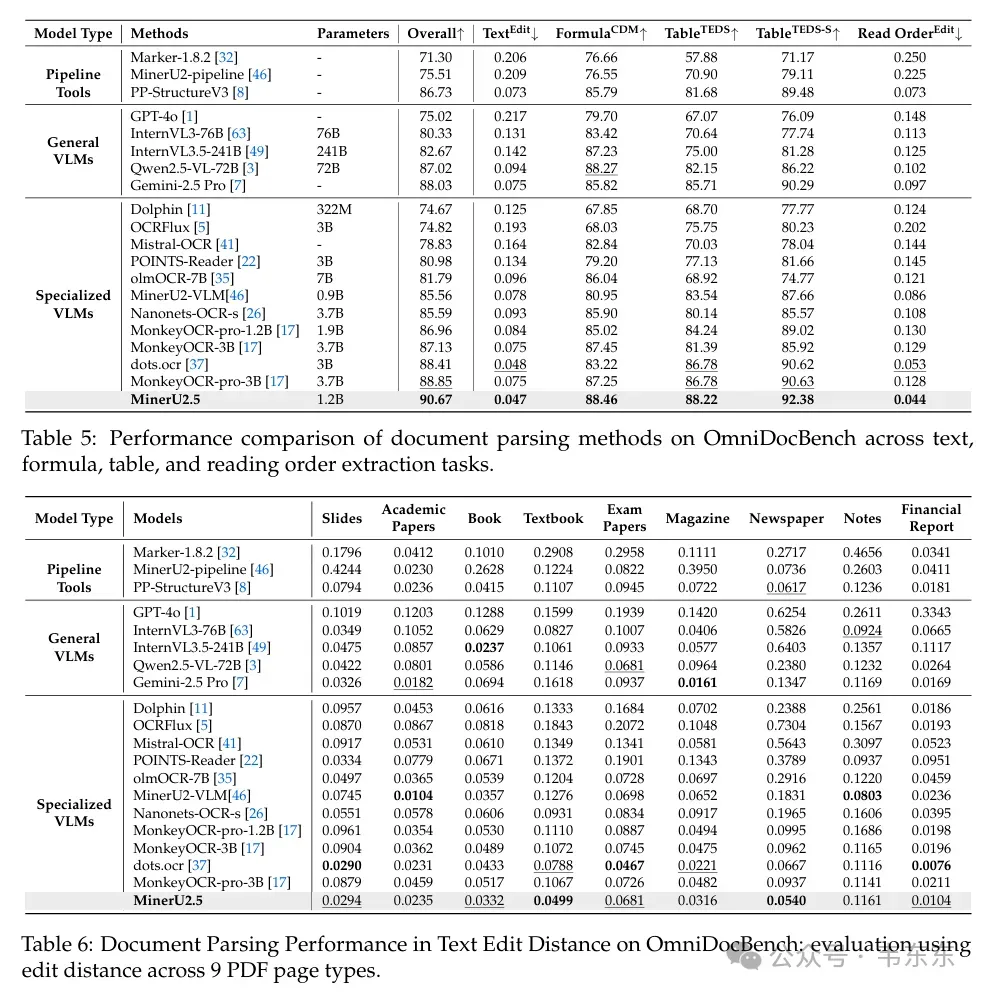
同时,相比开源文档解析方案(如 MonkeyOCR、PP-StructureV3),MinerU2.5 在解析精度、结构完整性和格式自然度方面也表现出了明显的领先优势。
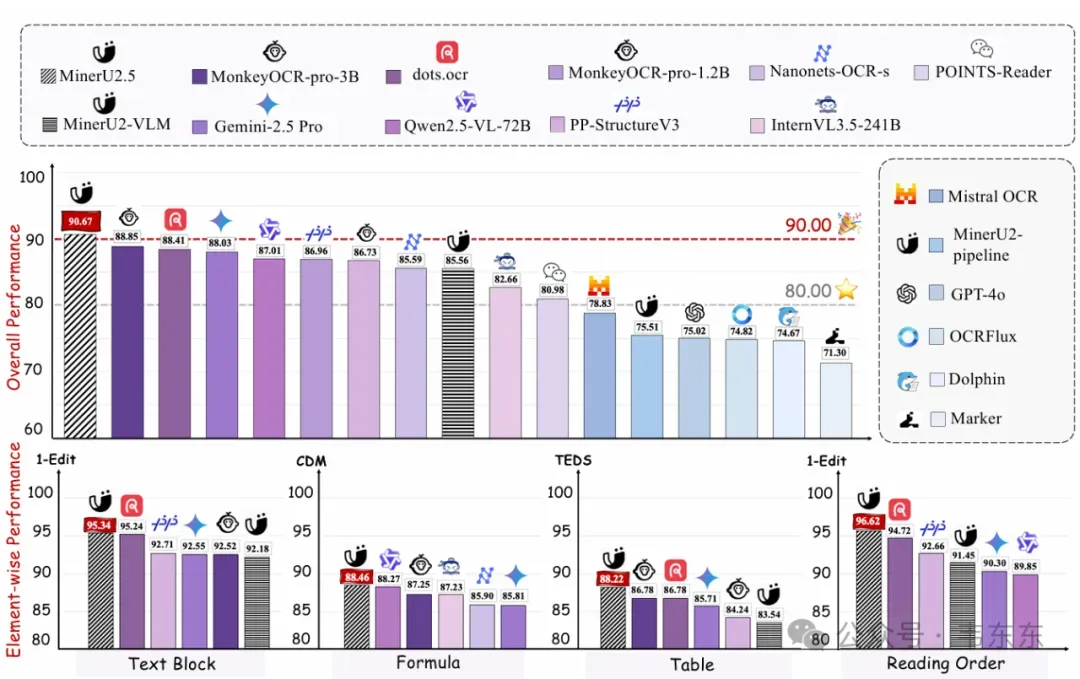
1.2迭代效果一览
首先看下复杂的数学公式解析效果,传统方案很容易出现符号遗漏或者结构错乱,MinerU2.5 最新版本能够比较准确识别长难公式,并输出 LaTeX 代码,直接渲染为完整公式。这点也算是小试牛刀了下。

其次,对于财报中的复杂表格而言,传统模型往往输出结构散乱,而 MinerU2.5 能够完整保持原始表格结构。
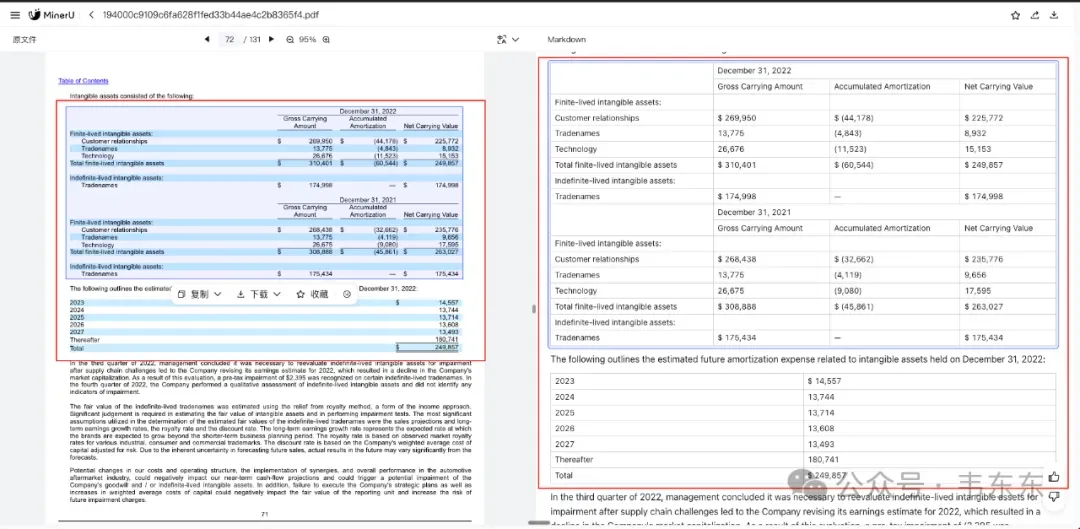
不过值得注意的是,在这个英文财报中对于一个比较简单的文本段落,MinerU2.5 丢失了其中的美元符号,并莫名的把字体变成了红色表示,这说明其微调数据中,独立的数字比"$+数字"的组合更常见,所以模型倾向于只输出数字。
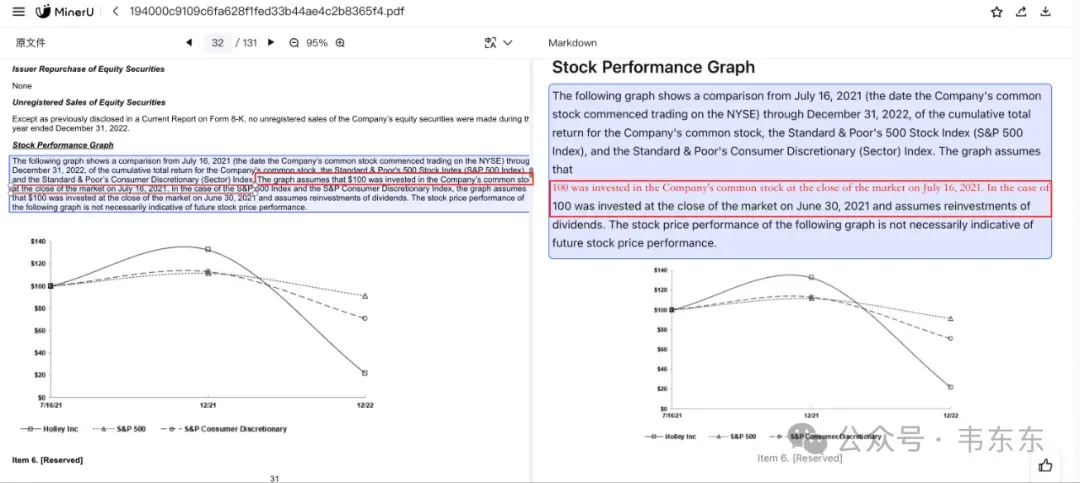
其次,这个例子中也出现了比较严重的文本重复和日期混乱问题,原文中是提到了两种假设情况,视觉模型可能试图同时表达这两种情况,但因为缺乏明确的结构化约束,导致生成时两种描述被错误地融合,这也算是端到端模型的原罪了。
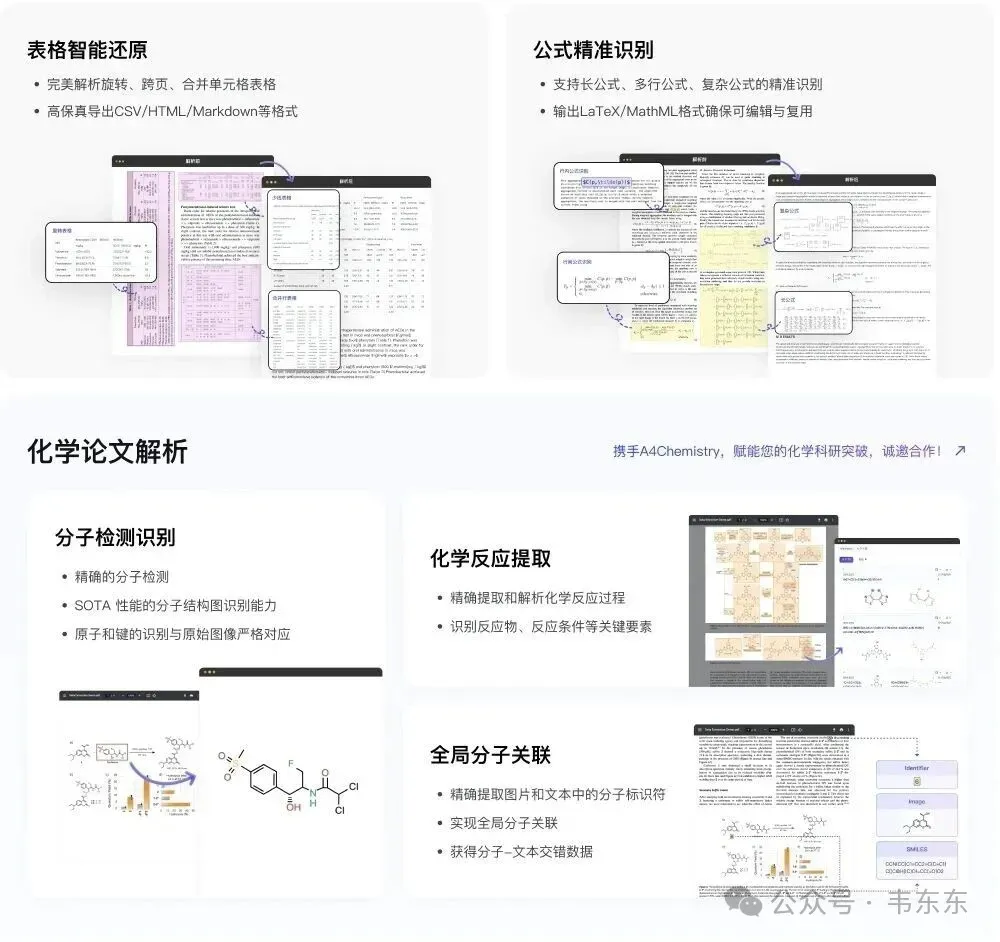
最后贴张官方公众号的一些解析效果汇总图示,总的来说这次MinerU2.5比较能打。但如果需要处理金融、法律等精确性要求极高的文档,还是不要完全依赖端到端视觉模型。
2、双后端架构设计
MinerU 2.5 采用了双后端互斥选择的机制,这种设计体现了不同技术路径在文档解析领域的本质差异。
传统的 Pipeline 后端代表了现在业界有充分共识的“多模型协作”思路,通过 8 个专业子模型分工合作,每个模型专注于特定任务,如布局检测、公式识别、OCR 等。这种方式的优势在于可控性强、问题定位精确,每个环节都可以独立优化。
而 MinerU2.0 版本开始引入的 VLM 后端,选择了端到端的路线。也就是使用单一的视觉大模型处理整个文档解析流程。这种方式的核心优势是模型间的信息传递更加顺畅,避免了传统流水线中的误差累积问题。
2.1Pipeline 后端
Pipeline 后端采用了经典的分而治之策略,把复杂的文档解析任务分解为 8 个相对独立的子任务。这种做法追求的是识别准确率和错误可控性。在源码中,这 8 个子模型通过 mineru/bckend/pipeline/model_list.py 文件进行统一定义:
复制这个类定义看似简单,实际上是整个 Pipeline 后端的“协议规范”。每个字符串常量都对应着一个专门的深度学习模型,这些模型在mineru/backend/pipeline/model_init.py中被具体实例化。
以下是 Pipeline 后端的处理流程图。
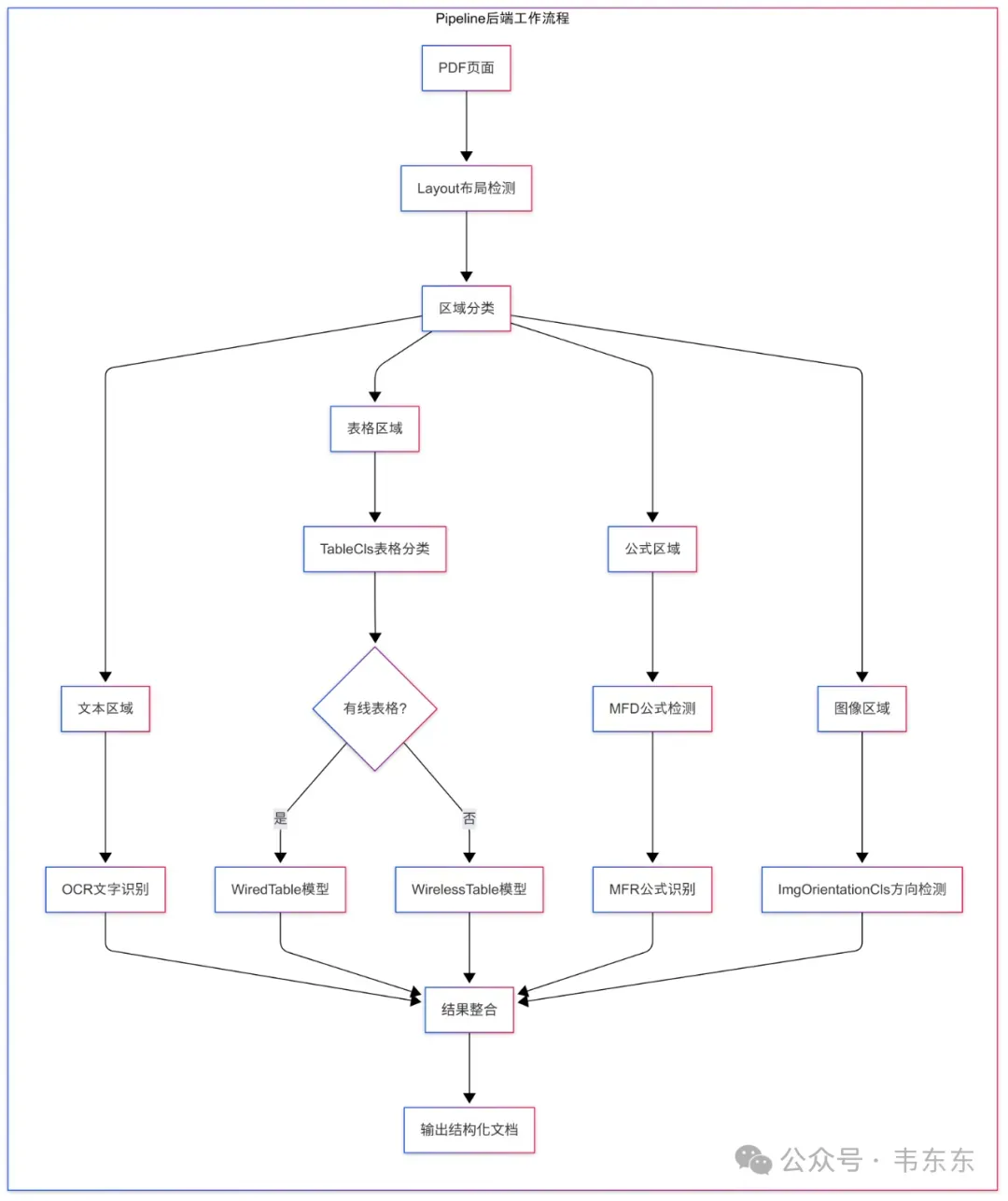
每个子模型的技术选型也都体现了在特定任务上的最佳实践,以下选择三个模型简要描述下:
布局检测模型
这部分采用的是 DocLayoutYOLO 架构,源码位于mineru/mod/layout/doclayoutyolo.py。选择 YOLO 系列当然是因为其在目标检务上的成熟性和实时性优势,能够快速准确地识别文档中的各种区域类型。
数据公式处理
这部分采用了“检测+识别”的两阶段策略。MFD 使用 YOLOv8 进行公式区域定位,MFR 使用 UniMERNet 进行公式内容识别。这种分离设计的优势在于可以针对性地优化每个阶段的性能。
表格处理
这部分实现了三层处理架构,具体来说,先通过 TableCls 进行表格类型分类,然后根据是否有边框选择不同的识别模型。有线表格使用 UNet 架构,无线表格使用 SLANet Plus 架构,这种差异化处理是种很成熟的工程实践,实测是可以显著提升表格识别的准确率。
从mineru/backend/pipeline/model_init.py中可以看到这些模型的导入关系:
复制从这段导入代码可以看出 MinerU 在技术栈选择上的务实做法,既有基于 PyTorch 的现代架构(如 UniMERNet),也有基于 PaddlePaddle 的成熟方案(如 PaddleOCR),体现了选择最适合的工具而非统一技术栈的工程哲学。
2.2VLM 后端
不同于 Pipeline 后端的经典做法,VLM 后端代表了当前文档解析领域的一个重要技术路线。也就是从多模型协作转向单模型端到端处理。这种方式的核心理念是利用大型视觉-语言模型的理解能力,让模型直接从原始文档图像生成结构化输出。
vlm 的三种启动方式
VLM 后端提供了三种不同的启动方式,这种设计体现了对不同部署场景的灵活选择。在mineru/cli/client.py:53-60中定义了这些选项:
复制vlm-transformers:这是最直接的方式,基于 HuggingFace Transformers 框架进行本地推理。选择这种方式的场景通常是开发调试阶段,或者对数据安全有严格要求的离线环境。优势在于配置简单、依赖关系清晰,但推理速度相对较慢。
vlm-vllm-engine:这种是性能优化的方案,使用 vLLM 引擎进行推理加速。通过 PagedAttention、连续批处理等技术,理论上能把推理速度提升 20-30 倍。这种方式适合高性能生产环境,特别是需要处理大批量文档的场景。
vlm-http-client:最后这种是分布式部署的解决方案,采用客户端-服务器分离的架构。服务器端运行模型推理服务,客户端通过 HTTP 接口调用。这种方式的最大优势是资源共享,多个用户可以共享同一套 GPU 资源,显著降低部署成本。
VLM 两阶段推理
VLM 后端最具创新性的设计应该算是"两阶段推理"机制。从源码中可以看到,在mineru/backend/vlm/vlm_analyze.py:151调用了关键方法:
复制这个batch_two_step_extract方法明确体现了两阶段处理架构。虽然使用的是同一个视觉大模型,但通过不同处理策略实现了布局分析与内容识别的逻辑解耦。
第一阶段:结构理解与区域定位
模型接收 PDF 页面图像,输出结构化的区域信息。每个区域块包含以下关键字段:
复制第二阶段:内容提取与后处理
第二阶段通过MagicModel类处理第一阶段的输出,进行分类映射和内容优化:
复制整了张图示,方便理解 vlm 两阶段推理的完整流程:
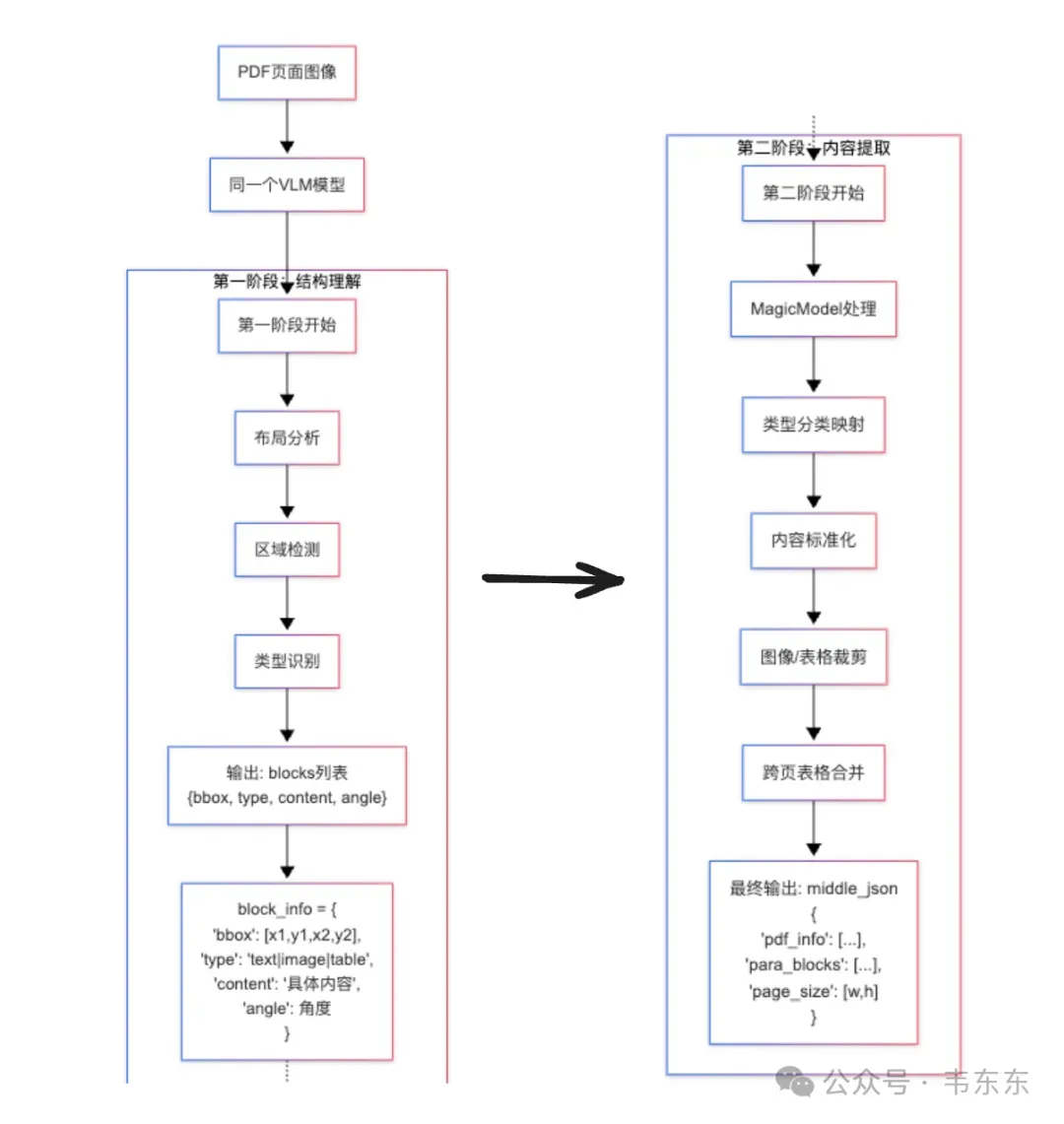
这种设计的巧妙之处在于,把复杂的文档理解任务分解为“先理解结构,再提取内容”两个相对简单的子任务。第一阶段专注于空间布局和语义分类,第二阶段专注于内容标准化和后处理优化。通过这种方式,既保持了端到端模型的信息传递优势,又避免了一次性处理过于复杂任务导致的性能下降问题。
3、核心实现原理
前面一章介绍了MinerU的架构设计和 VLM 两阶段推理机制,这部分内容我挑了四个觉得比较重要的核心技术实现原理进行下拆解。
注意,这部分更多是算法原理层面的分析,不感兴趣的直接跳到最后一段。
3.1批处理机制
MinerU在处理大批量文档时采用了很有特色的批处理策略,不同模型根据其计算特性采用不同的批大小配置,实现 GPU 资源的最优利用。
其中,Pipeline 后端通过动态批处理优化性能,在mineru/backend/pipeline/batch_analyze.py:17-22中定义了各模型的基础批大小:
复制批处理类的核心设计体现了对性能和资源的精确控制:
复制这种设计很合理,毕竟不同模型的计算复杂度和内存需求差异很大。布局检测和公式检测需要处理高分辨率图像,内存占用大,所以批大小设为 1;而公式识别和 OCR 处理的是裁剪后的小图像区域,可以大批量并行处理,显著提升吞吐量。
3.2内存管理和 GPU 优化策略
MinerU 实现了智能的内存管理机制,根据 GPU 显存动态调整批处理参数。VLM 后端在mineru/backend/vlm/vlm_analyze.py:72-84中展示了显存自适应逻辑:
复制这种自适应机制确保了 MinerU 能够在不同硬件配置上稳定运行,避免了 OOM(内存溢出)错误。同时通过环境变量MINERU_VIRTUAL_VRAM_SIZE户手动限制显存使用,适应容器化部署环境。
3.3多尺度图像处理与坐标转换
MinerU 采用了多尺度图像处理策略来平衡识别精度和处理速度。在图像裁剪过程中,通过scale参数控制输出图的分辨率:
复制scale=2的设计体现了很好的工程权衡:2 倍分辨率既能保证 OCR 和表格识别的精度要求,又不会过度消耗存储空间。对于数学公式等高精度需求的内容,高分辨率图像能够保留更多细节信息,提升识别准确率。坐标有效性检查确保了系统的健壮性:
复制这种检查防止了无效坐标导致的图像裁剪失败,提升了系统在处理异常 PDF 时的容错能力。
3.4表格识别的分类算法
MinerU 在表格处理上采用了创新的分类算法,通过统计分析自动判断表格类型。在mineru/model/table/rec/unet_table/main.py:326-331中实现了基于非空单元格数量的智能分类:
复制这个算法的数学原理是:通过非空单元格数量的平方根计算表格的“复杂度因子”,然后比较有线和无线两种算法的预期处理能力,自动选择最适合的识别方案。
这种自适应选择机制不得不说很聪明,避免了传统方法中需要人工预设表格类型的问题,明显提升了表格识别的自动化程度和准确率。特别是对于复杂的学术论文和技术文档中的表格,这种智能分类算法表现出了明显的优势。
4、部署与扩展
4.1AGPL-3.0 许可证注意事项
根据官方 README 的说明,MinerU 选择 AGPL-3.0 许可证主要是受 YOLO 算法的限制。由于 Pipeline 后端中的多个核心模型(如布局检测、公式检测等)依赖 YOLO 算法,而 YOLO 本身遵循 AGPL 协议,因此 MinerU 必须采用相同的许可证。官方也提到未来会探索替换为许可条款更宽松的模型。
不过大多数情况下,把 MinerU 作为独立工具使用(如命令行调用、容器化部署、API 调用等)是相对安全的。但如果你修改了 MinerU 的源代码,并把它作为网络服务提供,或者将其深度集成到商业产品中进行分发,则需要按照 AGPL-3.0 的要求开源相关代码。如果需在商业环境中深度使用,建议通过 API 方式调用以降低许可证风险,或咨询法务部门确保合规。
4.2企业级部署考虑
对于生产环境,推荐使用 Docker 容器化部署 MinerU,确保环境一致性和可扩展性。同时需要考虑多实例负载均衡,特别是 VLM 后端的 http-client 模式天然支持分布式架构。可以通过 Nginx 或 Kubernetes 实现请求分发,确保单点故障时的服务连续性。
此外,对于敏感文档的解析,建议使用 HTTPS 加密传输、实施访问权限控制、定期审计处理日志、考虑数据脱敏需求。
4.3微调投入产出比问题
虽然 MinerU 理论上支持模型微调,但在实际应用中需要谨慎评估投入产出比。一方面官方迭代速度可能是快于大部分团队的微调周期,其次,单就 VLM 模型微调而言,因为需要大量 PDF 页面图像配合高质量的结构化 JSON 标注数据。一个有效的微调数据集动辄上万页标注数据,这也是不差钱的团队才有的选择。
简言之,MinerU 的通用模型已经在 OmniDocBench 等权威评测中达到 SOTA 水平,理论上能够覆盖 90%以上的实际应用场景。对于特殊垂直领域的需求,更务实的做法是通过后处理和规则优化来解决。
4.4RAGFlow 集成预告
MinerU 作与 RAGFlow 等成熟的 RAG 框架具有天然的互补性,通过把 MinerU 集成到 RAG 工作流中,可以显著提升文档预处理的质量,为后续的向量化和检索提供更精确的文本内容。具体的集成策略、性能优化配置以及最佳实践案例,我会在下一篇文章中详细介绍。
5、写在最后
记得上次在MinerU现场交流时,我问到说如何看待MinerU和Textin这种很多年技术积累的传统Pipeline 产品竞争,对方回答是会基于研究院的人才密度在VLM这种路线上实现弯道超车。
客观来说,VLM 终归是生成模型,幻觉问题和同样输入的不一致性输出问题仍然是绕不开的原罪。其次,视觉模型虽然可以解决 90%的场景,但剩下的 10%场景的微调可能会顾此失彼。且不说边缘 case 本就数据稀少,也很难形成有效训练。所以,可以预见的是在未来几年内,对于高精度要求的场景 Pipeline 方法依然会占主导。
当然,MinerU 提供双后端的设计也很明智。让用户根据场景自主选择,而不是强推某一种技术路线。长期来看,预计会出现混合架构,就是用 VLM 做粗粒度理解,用专门模型做精细化处理。或者 VLM 作为“调度器”,根据文档复杂度混合使用不同工具。再或者,可以使用 VLM 增强的 Pipeline,就是 VLM 对 Pipeline 输出结果进行审核修正,或许也是一种值得考虑的解法。
Anyway,多源异构的文档解析是个很重要的辛苦活,MinerU那句“Tokenize Anything”的slogan想想确实没错,这事可能是得官方团队出手可能干的才更加技术普惠些。


